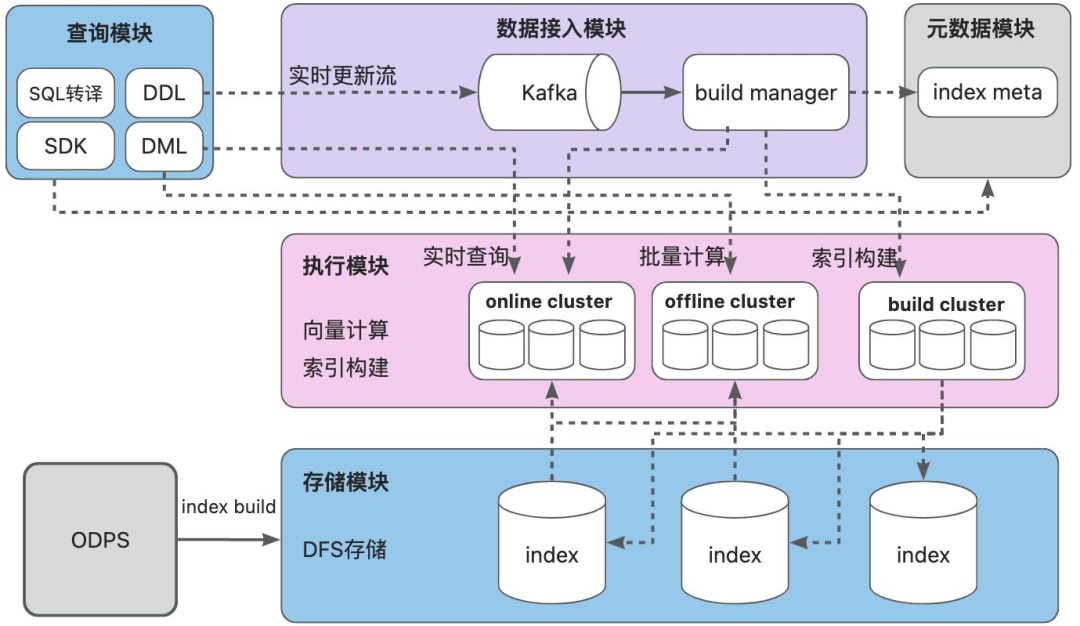
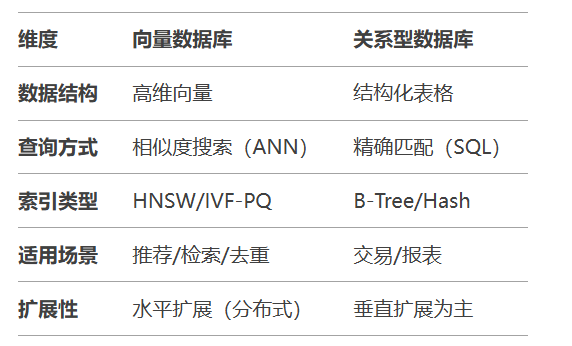
向量数据库是专为高维向量数据设计的存储与检索系统,其核心能力在于:
相似性搜索:在毫秒级时间内从十亿级数据中找到最相似项
多模态支持:统一管理文本、图像、音视频的向量表示
动态扩展:支持实时插入与增量更新
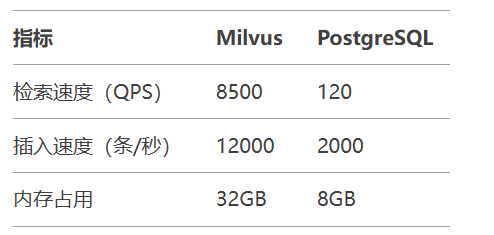
工业级案例:某电商平台使用向量数据库实现商品推荐,点击率提升23%,退货率降低15%
降维技术:
t-SNE:适合局部结构可视化
UMAP:保留全局结构更优
PCA:计算效率最高
可视化工具:
import matplotlib.pyplot as plt from sklearn.manifold import TSNE vectors = [...] # 高维向量列表 tsne = TSNE(n_components=2) vis_data = tsne.fit_transform(vectors) plt.scatter(vis_data[:,0], vis_data[:,1]) plt.show()
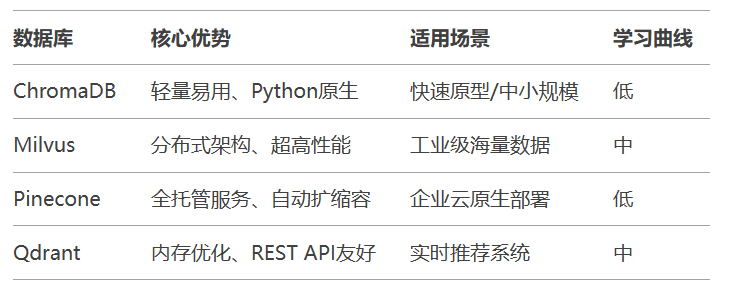
是否需要云托管? → 是 → Pinecone → 否 → 数据规模 > 1亿条? → 是 → Milvus → 否 → 需要快速开发? → 是 → ChromaDB → 否 → Qdrant
Collection:类似数据库的表,包含向量+元数据
Embedding Function:指定向量生成模型
Query:支持混合搜索(向量+元数据过滤)
import chromadb
# 1. 初始化客户端
client = chromadb.PersistentClient(path="/data/chroma")
# 2. 创建集合
collection = client.create_collection(
name="products",
metadata={"hnsw:space": "cosine"} # 相似度计算方式
)
# 3. 插入数据
collection.add(
documents=["智能手机", "笔记本电脑"],
metadatas=[{"category": "电子"}, {"category": "电脑"}],
ids=["id1", "id2"]
)
# 4. 相似性查询
results = collection.query(
query_texts=["平板电脑"],
n_results=2
)
print(results["documents"][0])
# 输出:['笔记本电脑', '智能手机']混合查询:
results = collection.query(
query_embeddings=[...],
where={"category": {"$eq": "电子"}}, # 元数据过滤
n_results=10
)性能调优:
# 调整HNSW参数 collection.modify( hnsw:ef_construction=200, # 控制索引精度 hnsw:M=16 # 控制内存占用 )
import pandas as pd
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('BAAI/bge-base-zh')
movies = pd.read_csv("movies.csv")
# 生成向量
embeddings = model.encode(movies["description"].tolist())collection.add(
documents=movies["description"].tolist(),
metadatas=movies[["genre", "year"]].to_dict('records'),
ids=movies["id"].astype(str).tolist(),
embeddings=embeddings.tolist()
)5.3 推荐查询
def recommend_movie(user_query):
query_embed = model.encode([user_query])
results = collection.query(
query_embeddings=query_embed.tolist(),
n_results=5,
where={"year": {"$gte": 2010}} # 过滤2010年后电影
)
return results["metadatas"][0]
print(recommend_movie("浪漫的爱情故事"))
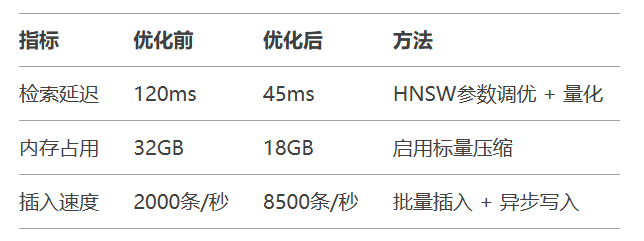
# 输出:[{'title': '泰坦尼克号', 'genre': '爱情'}, ...]索引算法:HNSW在精度与速度的最佳平衡
混合查询:结合向量相似度与元数据过滤
动态更新:支持实时增删改操作