向量数据库(Vector Database)是专为高维向量数据设计的存储与检索系统,其核心功能是通过相似性搜索快速匹配数据。
核心组件:
嵌入向量(Embedding Vectors):通过大模型将文本、图像等数据映射为高维向量(如768维)
相似性度量(Similarity Metrics):余弦相似度、欧氏距离、内积等
索引结构(Indexing):HNSW、IVF-PQ、LSH等高效检索算法
类比理解:
传统图书馆 → 向量数据库 书籍分类编号 → 向量索引 读者查找书籍 → 相似性搜索 管理员维护书架 → 分布式存储
数据预处理流程:
原始数据 → 嵌入模型 → 向量化 → 索引构建 → 持久化存储
典型存储结构:
# ChromaDB存储示例
import chromadb
client = chromadb.PersistentClient(path="/data/vector_db")
collection = client.create_collection("articles")
# 插入向量数据
collection.add(
documents=["AI发展历史", "量子计算原理"],
embeddings=[[0.2, 0.5, ...], [0.7, 0.3, ...]], # 768维向量
ids=["id1", "id2"]
)
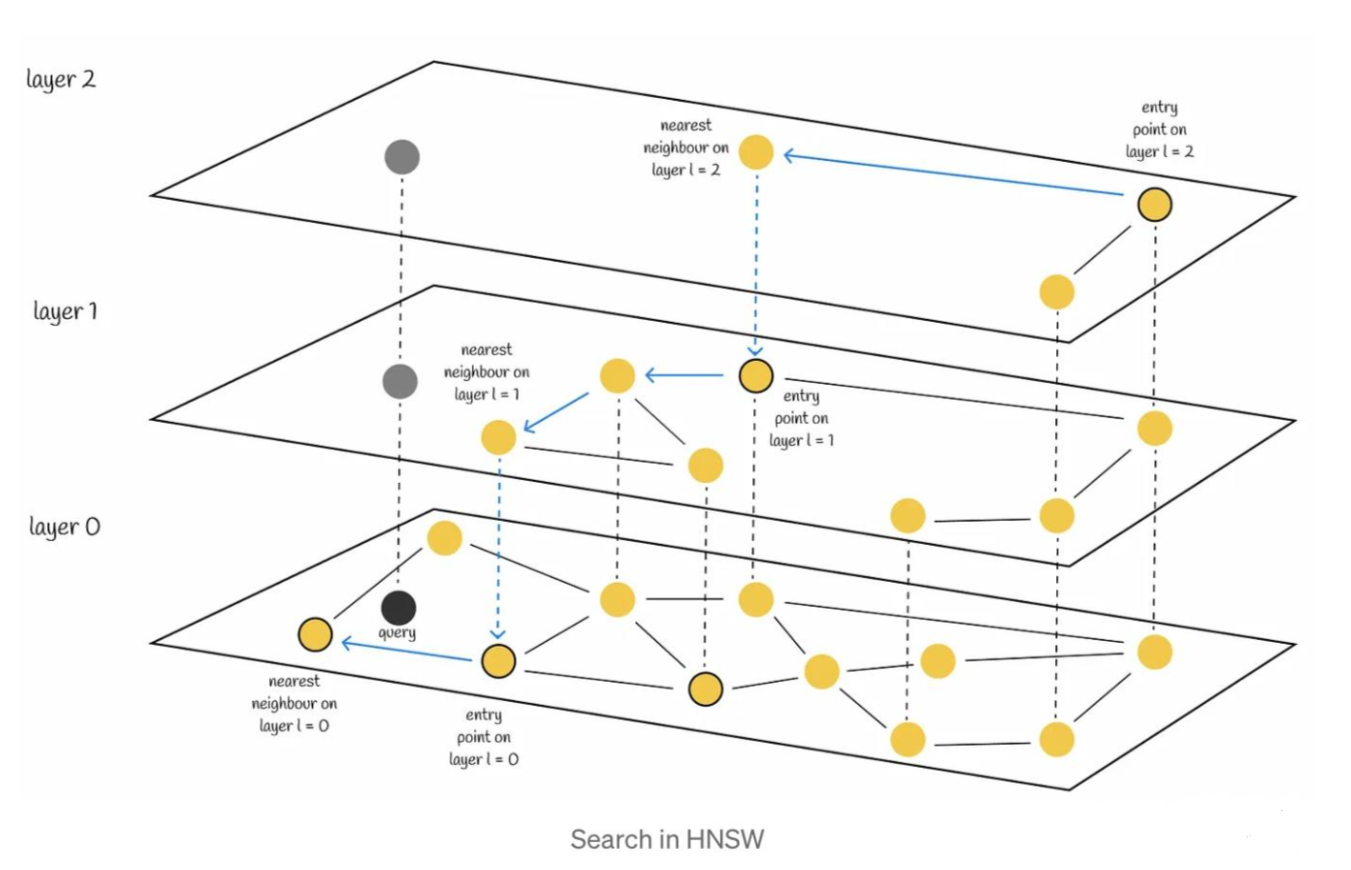
HNSW检索过程图示:
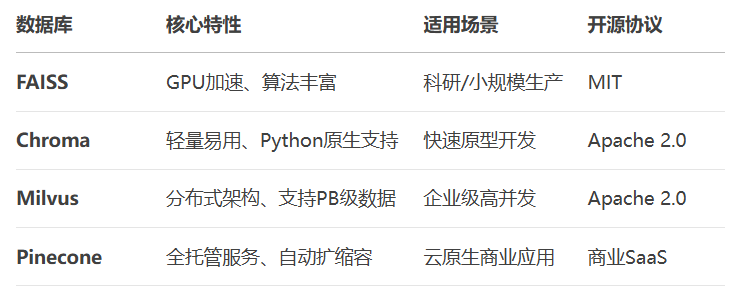
Milvus分布式部署:
# Docker单节点 docker run -d --name milvus \ -p 19530:19530 \ -v ~/milvus_data:/var/lib/milvus \ milvusdb/milvus:latest # Kubernetes集群部署 helm install milvus milvus-helm/milvus \ --set cluster.enabled=true \ --set persistence.enabled=true
FAISS快速使用:
import faiss
import numpy as np
dim = 768
index = faiss.IndexFlatL2(dim)
# 添加100万个768维向量
vectors = np.random.rand(1000000, 768).astype('float32')
index.add(vectors)
# 相似性搜索
query = np.random.rand(1, 768).astype('float32')
distances, indices = index.search(query, 10)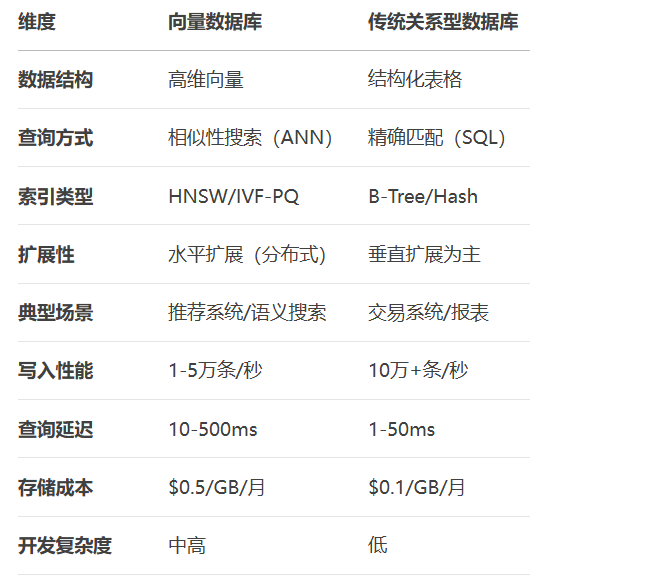
是否需要相似性搜索? → 否 → 选择MySQL/PostgreSQL → 是 → 数据规模 > 1亿条? → 是 → 选择Milvus → 否 → 需要云托管? → 是 → Pinecone → 否 → 需要快速开发? → 是 → Chroma → 否 → FAISS
用户行为 → 实时特征工程 → 向量化 → Milvus检索 → 推荐结果
优化方案:
混合索引:HNSW+IVF_PQ提升召回率
缓存策略:Redis缓存热点商品向量
异步更新:每小时增量更新索引
Milvus性能配置:
# server_config.yaml queryNode: graceTime: 3000 # 服务优雅退出时间 schedulerInterval: 100 # 调度间隔(ms) flowGraphMaxQueueLength: 1024 index: indexBuildingThreshold: 100000 # 触发建索引的阈值 enableIndex: true indexParams: nlist: 2048 # IVF聚类中心数 m: 16 # HNSW层间连接数
掌握向量数据库需持续实践:从Hugging Face数据集开始实验检索效果,更多AI大模型应用开发学习内容,尽在聚客AI学院。



