总显存 = 模型参数 + 梯度 + 优化器状态 + 激活值 + 临时缓存
模型参数:参数量 × 精度(FP32=4字节,FP16=2字节)
梯度:与参数同精度
优化器状态:Adam需额外2倍参数空间(动量+方差)
激活值:序列长度 × 隐藏层维度 × 层数 × 精度
实战测算(以LLaMA-7B为例):

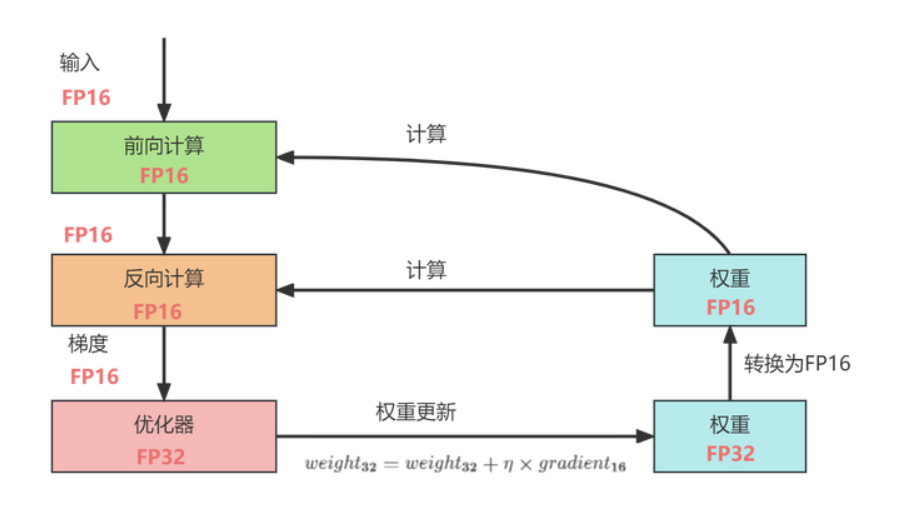
FP16存储:权重、梯度、激活值
FP32主副本:用于参数更新,防止舍入误差
Loss Scaling:放大损失值避免下溢出
PyTorch实现:
from torch.cuda.amp import autocast, GradScaler scaler = GradScaler() for inputs, targets in dataloader: with autocast(): outputs = model(inputs) loss = criterion(outputs, targets) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()
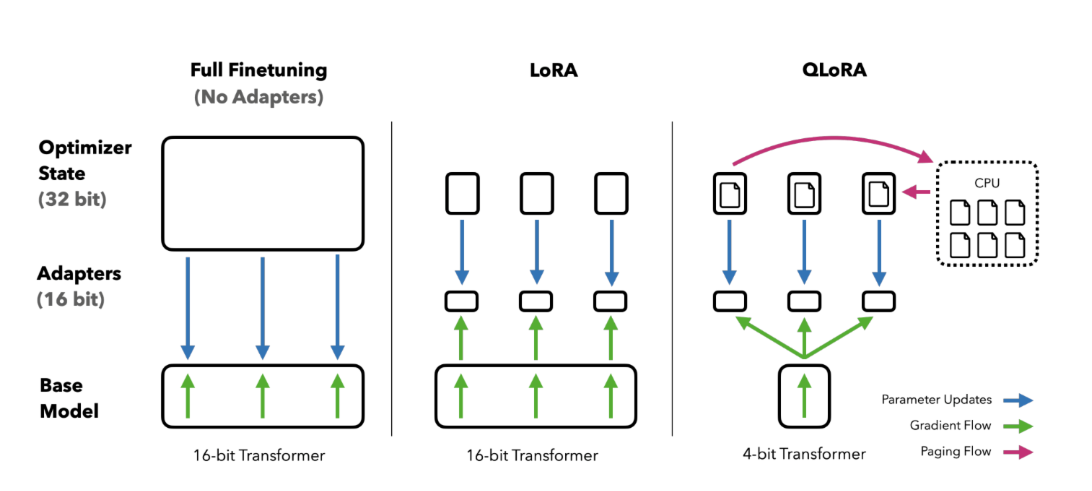
技术突破:
向量量化:将FP16矩阵分解为Int8矩阵+FP16缩放因子
异常值分离:0.1%的异常值保留FP16计算
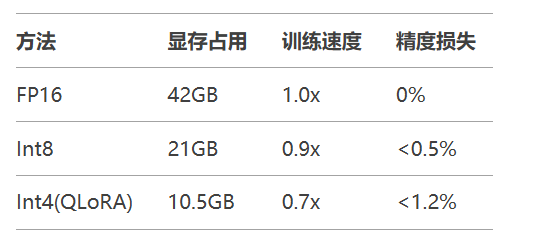
内存节省对比:
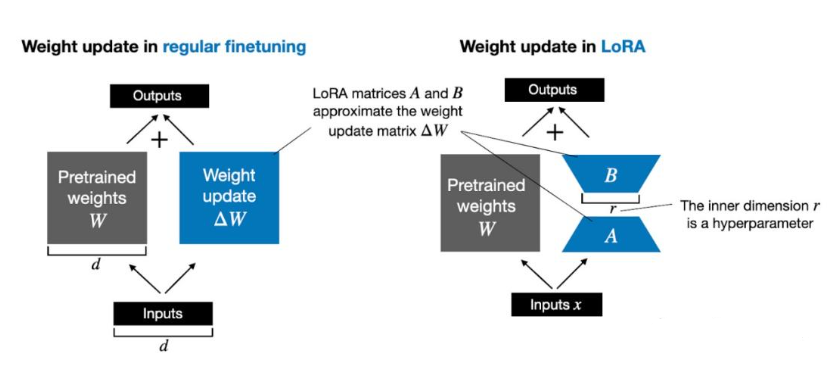
4bit NormalFloat量化:自适应数值范围优化
双量化:对量化常数二次压缩
Paged Optimizers:优化器状态分页管理
环境配置:
pip install bitsandbytes accelerate peft transformers
训练脚本:
from peft import LoraConfig, get_peft_model from transformers import Trainer model = AutoModelForCausalLM.from_pretrained( "meta-llama/Llama-2-7b", load_in_4bit=True, quantization_config=BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=True ) ) peft_config = LoraConfig( r=8, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.05 ) model = get_peft_model(model, peft_config) trainer = Trainer( model=model, train_dataset=dataset, args=TrainingArguments( per_device_train_batch_size=4, gradient_accumulation_steps=8, fp16=True, optim="paged_adamw_8bit" ) ) trainer.train()
关键参数说明:
gradient_accumulation_steps=8:通过累积梯度降低显存峰值
paged_adamw_8bit:分页管理优化器状态
原理:用时间换空间,重计算中间激活
model.gradient_checkpointing_enable() # 可节省30%-50%显存
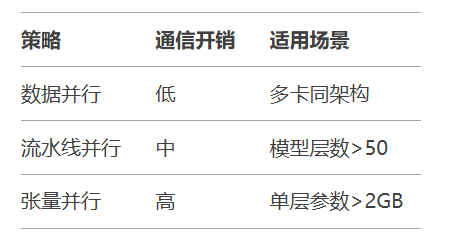
CPU Offload示例:
from accelerate import init_empty_weights, load_checkpoint_and_dispatch with init_empty_weights(): model = AutoModelForCausalLM.from_config(config) model = load_checkpoint_and_dispatch( model, checkpoint_path, device_map="auto", offload_folder="offload", no_split_module_classes=["LlamaDecoderLayer"] )
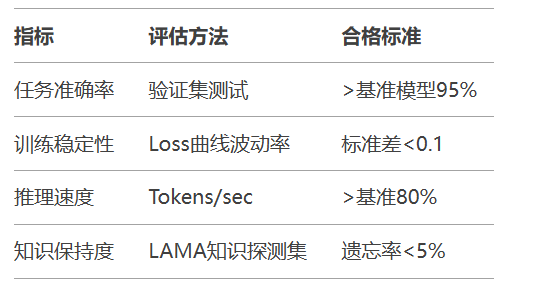
5.2 超参数调优指南
from optuna import create_study
def objective(trial):
lr = trial.suggest_float("lr", 1e-6, 1e-4, log=True)
batch_size = trial.suggest_categorical("batch_size", [4,8,16])
# ...训练与评估...
return validation_loss
study = create_study(direction="minimize")
study.optimize(objective, n_trials=50)掌握大模型微调需持续实践:建议从Hugging Face PEFT库入手,更多AI大模型应用开发学习内容,尽在聚客AI学院



