DeepSeek R1并非从零开始训练,而是基于DeepSeek V3-Base模型通过强化学习(RL)分阶段优化的产物。其核心目标是通过奖励机制引导模型发展出类人的推理能力,而非单纯的语言生成能力。训练流程分为两个关键阶段:
R1-Zero阶段:采用纯RL训练探索推理能力的自然涌现,生成初始版本;
R1正式阶段:引入多阶段训练管道,结合冷启动数据(Cold-Start Data)和结构化RL流程,最终形成兼具高推理性能和可读性的模型。
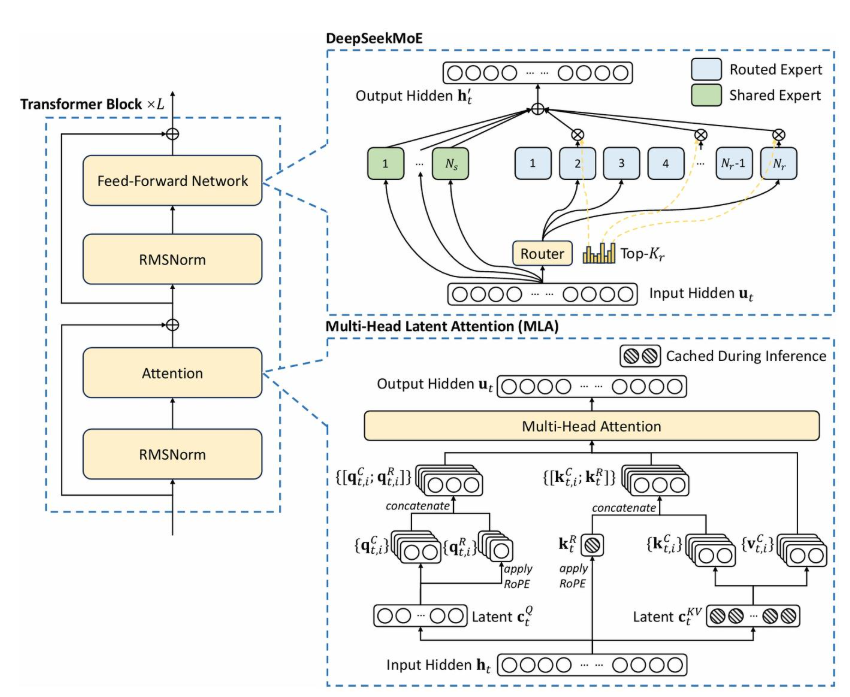
DeepSeek V3采用混合专家模型(Mixture-of-Experts, MoE),总参数量达6710亿,但每个输入仅激活370亿参数。其核心由两条路径构成:
快速记忆系统:通过检索相似案例快速构建上下文(类似人类直觉反应);
智能路由决策:根据问题复杂度动态选择处理方式:
快速处理器:处理简单任务(如常识问答),响应时间<100ms;
专家系统:针对复杂问题(如数学证明)激活专业子网络进行深度分析。
路由模块通过注意力机制计算专家权重,实现"按需激活"。例如处理"解方程√(a+x)=x"时,系统会优先激活数学专家模块,同时调用符号计算子网络生成分步推导。这种架构使V3在保持70B级模型推理成本的同时,达到千亿参数模型的性能。
在RL训练中,V3扮演策略模型(Actor)的角色,其交互流程包含三个核心组件:
环境(Environment):由数学题、编程问题等推理任务构成;
动作(Action):模型生成包含推理过程的答案(如:"解:设x为...,则方程变形为...");
奖励(Reward):基于答案正确性和推理逻辑质量计算,正向奖励可达+2.7,错误推理惩罚可达-1.3。
以问题"3.11和3.8哪个大?"为例:
初始响应:"3.11更大,因为小数点后第二位1>0"(奖励+0.5)
优化后响应:"比较3.11与3.8需统一小数位:3.8=3.80,故3.11<3.80"(奖励+1.8)
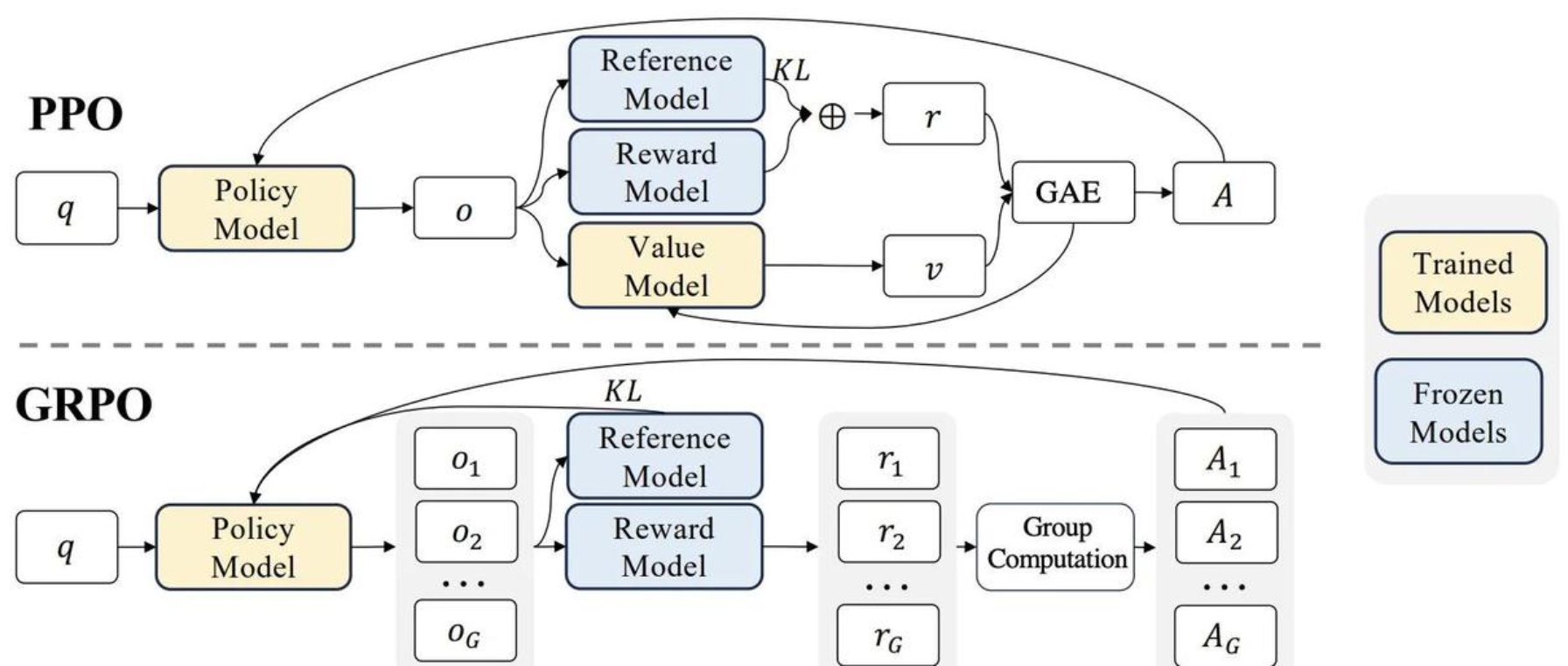
GRPO(Group Relative Policy Optimization)针对传统PPO的缺陷进行改进:
组采样机制:每个问题生成16组响应,通过组内比较计算相对优势值;
去Critic设计:直接利用奖励分布计算基线值,节省40%显存消耗;
稳定训练策略:引入KL散度惩罚项,限制策略更新幅度(β=0.02)。
优势值公式:
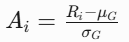
其中为组内平均奖励,为标准差。该设计使模型能识别"相对优质"的推理路径,而非依赖绝对奖励阈值。
目标函数包含两个关键部分:
1.奖励优化项:
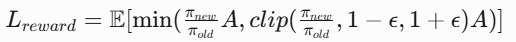
通过策略概率比限制更新幅度(ε=0.2),防止策略崩溃。
2.稳定性约束项:

控制新策略与旧策略的偏离程度,实验表明KL值需维持在3.5±0.8区间。
规则检查(30%):验证数学符号规范性(如"√"正确使用)和公式推导连贯性;
格式奖励(20%):强制响应包含
训练奖励(50%):基于问题类型动态调整权重,例如编程题侧重代码正确性(权重0.7),数学题侧重推导完整性(权重0.6)。
def calculate_reward(response): if format_check(response) and logic_validate(response): return accuracy_score * 0.5 + format_score * 0.2 + length_bonus * 0.3 else: return -1.0 # 格式错误直接惩罚
初始化:加载V3-Base模型,设置初始温度参数τ=1.2;
采样阶段:每个问题生成16组响应,耗时约23秒/问题;
奖励计算:并行评估组内响应,峰值计算吞吐量达152 samples/sec;
策略更新:使用GRPO更新参数,学习率3e-6,batch_size 1024。
训练过程中关键指标变化:

语言混合:中英文混杂(如"解:Let x=..."),发生概率达38%;
格式混乱:未闭合标签出现频率17%,影响下游解析。
过度冗长:后期响应平均长度增长270%,其中有效信息占比仅提升15%;
反思循环:约9%的响应出现"Wait, let me recheck..."类无效反思。
这些问题在后续的R1正式版本中通过冷启动数据(2000条人工标注CoT数据)和监督微调得到显著改善,最终使AIME准确率提升至79.8%,接近OpenAI-o1-1217水平。



