
模型微调(Fine-tuning)是指基于预训练大模型(如GPT、BERT等),在特定领域数据上进行二次训练的技术。预训练模型通过海量通用数据掌握了语言理解、知识推理等基础能力,而微调则使其适应具体应用场景。
以医疗问答系统为例:
原始GPT-3可以生成流畅文本,但无法准确回答专业医学问题
使用医学文献和病例数据进行微调后,模型能理解医学术语并给出专业建议
核心价值体现:
节省算力成本:无需从头训练(预训练需数千张GPU)
保留通用能力:维持原有语言理解和生成能力
提升专业性能:在目标领域达到接近专家水平
特点:更新所有模型参数
适用场景:数据量充足(百万级样本)、计算资源丰富
示例代码:
model = AutoModelForCausalLM.from_pretrained("gpt2")
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()冻结底层网络,仅训练顶层模块
适用:基础能力保留,快速适应新任务
分阶段解冻网络层(先顶层后底层)
平衡训练效率与效果
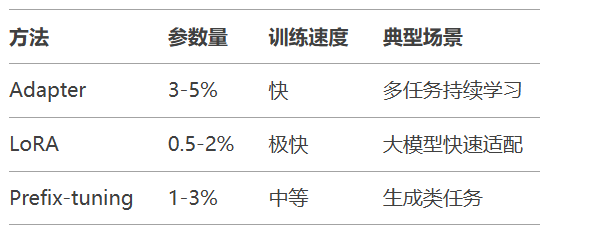
LoRA实现示例:
from peft import LoraConfig, get_peft_model config = LoraConfig( r=8, lora_alpha=16, target_modules=["q_proj", "v_proj"] ) model = get_peft_model(model, config)
核心组件:
Trainer API:封装训练流程
Accelerate:分布式训练加速
Datasets:数据预处理流水线
微软开发的分布式训练框架
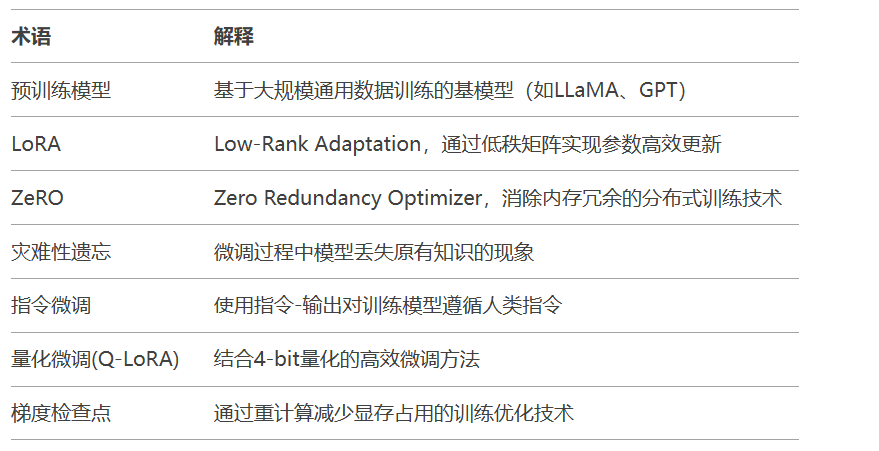
关键技术:
ZeRO优化器:显存优化技术
3D并行:数据/模型/流水线并行
Hugging Face参数高效微调工具包
支持方法:
LoRA
IA3
Prompt Tuning
数据规模 < 10万条 → PEFT+Transformers 10万-100万条 → DeepSpeed+部分微调 100万条+ → 全量微调+多机分布式
数据准备黄金法则:
质量 > 数量:500条高质量数据优于5万条噪声数据
领域匹配度:医疗微调数据应包含病例、医学文献等
数据多样性:覆盖目标场景的各种情况
超参数设置:
training_args = TrainingArguments( learning_rate=2e-5, # 典型初始值 per_device_train_batch_size=4, gradient_accumulation_steps=8, # 显存不足时使用 num_train_epochs=3, warmup_ratio=0.1 # 学习率预热比例 )
效果评估矩阵:
通用能力测试集(如MMLU)
领域专项测试(医疗领域需设计诊断准确率评估)
人类专家盲测



