1.1 快速安装与环境配置
# 创建虚拟环境 conda create -n langchain-env python=3.11 conda activate langchain-env # 安装核心依赖 pip install langchain langchain-openai duckduckgo-search pip install langchain-experimental # 高级功能支持
1.2 六大核心模块概览

2.1 实现流式输出(SSE协议)
from langchain_community.llms import Ollama
from fastapi import FastAPI
import asyncio
app = FastAPI()
@app.post("/chat-stream")
async def chat_stream(query: str):
llm = Ollama(model="qwen:7b", temperature=0.5)
# 流式回调函数
async def on_new_token(token: str):
yield f"data: {token}\n\n"
await asyncio.sleep(0.01)
# 执行流式生成
await llm.astream(query, callbacks=[{"on_llm_new_token": on_new_token}])技术要点:
使用 astream() 替代 invoke() 实现异步流式输出
通过 yield 返回 Server-Sent Events (SSE) 数据流
3.1 结构化提示词实战
from langchain.prompts import ChatPromptTemplate, FewShotPromptTemplate
# 1. 定义示例集
examples = [
{"input": "高兴", "output": "笑容满面"},
{"input": "悲伤", "output": "泪流满面"}
]
# 2. 构建动态模板
example_template = "输入: {input}\n输出: {output}"
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=PromptTemplate.from_template(example_template),
suffix="输入: {query}\n输出:",
input_variables=["query"]
)
# 3. 注入变量
formatted_prompt = prompt.format(query="愤怒")
print(formatted_prompt)输出效果:
输入: 高兴 输出: 笑容满面 输入: 悲伤 输出: 泪流满面 输入: 愤怒 输出:
优势:通过示例引导模型输出结构化内容
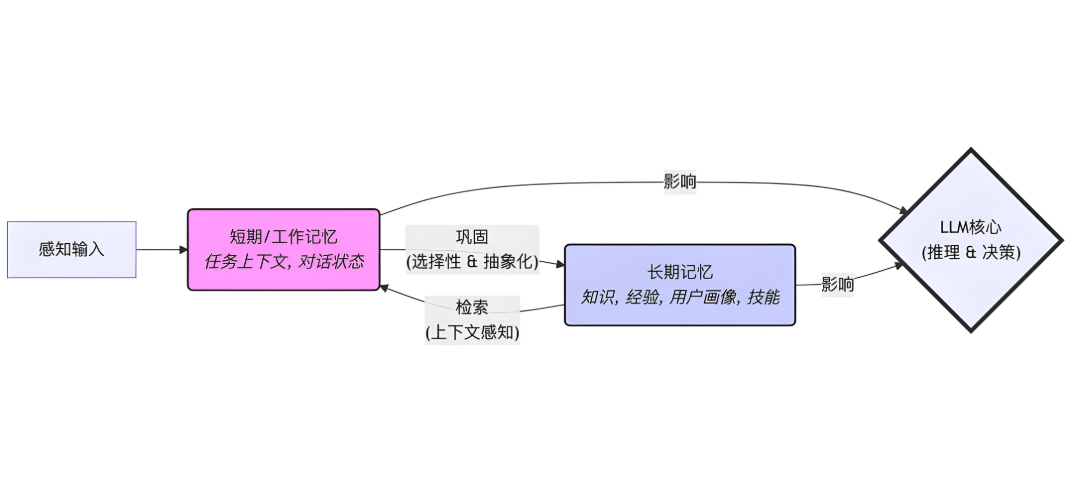
4.1 对话窗口记忆实现
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=3) # 保留最近3轮对话
# 模拟多轮对话
memory.save_context(
{"input": "我叫Alex"},
{"output": "你好Alex!有什么可以帮你?"}
)
memory.save_context(
{"input": "推荐一本科幻小说"},
{"output": "《三体》非常经典"}
)
# 加载当前记忆
print(memory.load_memory_variables({}))输出:
{
"history": "Human: 推荐一本科幻小说\nAI: 《三体》非常经典"
}关键点:
k=3 控制记忆长度,避免无限增长
适合订单查询、多轮对话等场景
5.1 自定义工具开发
from langchain.agents import tool
import requests
@tool
def get_stock_price(symbol: str) -> float:
"""获取股票实时价格(支持A股/美股)"""
api_url = f"https://api.example.com/stock/{symbol}"
response = requests.get(api_url).json()
return response["price"]
# 工具调用测试
print(get_stock_price("AAPL")) # 输出:176.325.2 集成搜索工具
from langchain_community.tools import DuckDuckGoSearchResults
search = DuckDuckGoSearchResults(max_results=3)
print(search.run("特斯拉最新车型"))输出:包含标题、链接、摘要的JSON
6.1 股票分析Agent
from langchain.agents import AgentType, initialize_agent tools = [get_stock_price, DuckDuckGoSearchResults()] llm = ChatOpenAI(model="gpt-4o") # 创建代理 agent = initialize_agent( tools, llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True ) # 执行复杂查询 agent.run( "查询特斯拉当前股价,并搜索其最新车型的续航里程" )
执行流程:
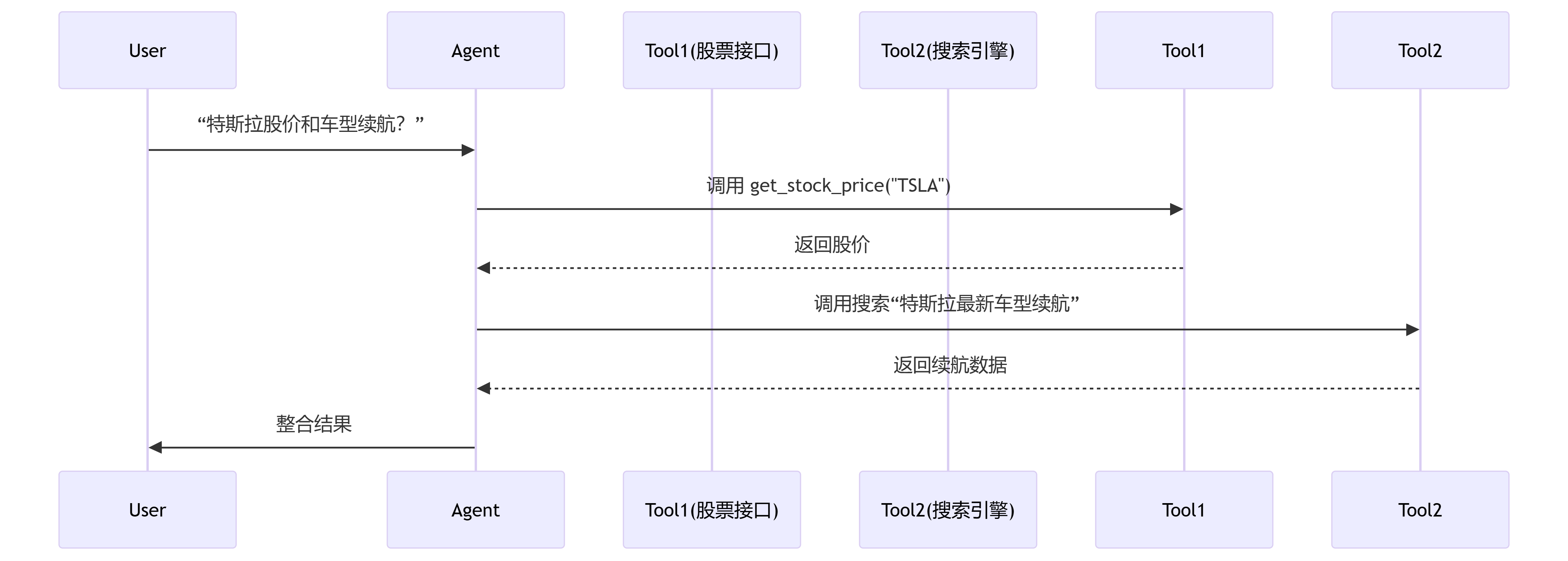
关键能力:
自动选择工具并解析参数
多步骤任务编排
7.1 架构设计
from langchain import RunnableParallel, RunnableBranch
# 定义分支逻辑
def route_query(input):
if "价格" in input:
return "stock_flow"
elif "新闻" in input:
return "news_flow"
return "default_flow"
# 构建并行工作流
workflow = RunnableBranch(
(lambda x: route_query(x) == "stock_flow", stock_analysis_chain),
(lambda x: route_query(x) == "news_flow", news_search_chain),
general_qa_chain
)
# 执行查询
response = workflow.invoke("特斯拉股价多少?")7.2 性能优化方案

部署建议:使用 FastAPI 封装为微服务,通过 uvicorn 部署
温馨提示:所有代码已在 Python 3.11 + LangChain 0.1.16 验证通过,建议配合 Ollama 本地模型部署。更多AI大模型应用开发学习视频内容和资料尽在聚客AI学院。



