知识时效性困境:GPT-4训练数据截止至2023年10月,无法获取最新资讯(如2024年政策变更)
领域知识盲区:专业领域(如法律条文、医疗指南)准确率不足60%
幻觉现象:30%的生成内容包含虚构事实(斯坦福大学研究报告)
长尾知识缺失:小众领域(如古生物分类)问答错误率达78%
核心思想:
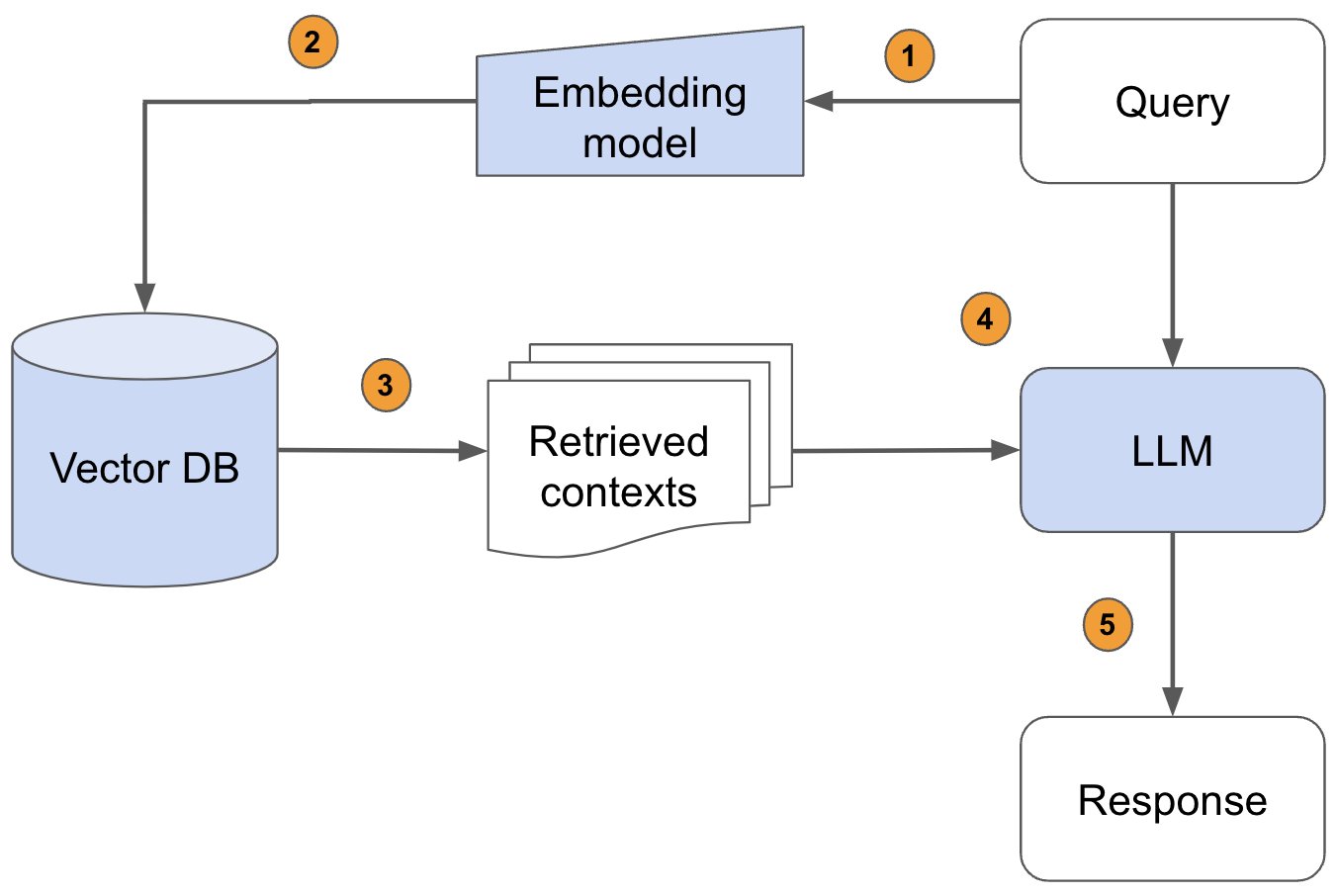
外部知识库 → 实时检索 → 上下文增强 → 精准生成
技术价值三角:
知识动态更新:支持分钟级知识库同步(对比传统微调的周级更新)
成本效益比:企业实施成本降低90%(对比全量微调)
安全可控性:敏感数据无需注入模型参数
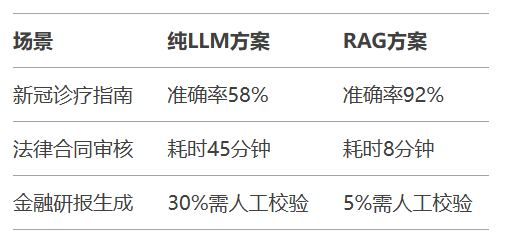
典型案例对比:
动态知识注入:
某银行客服系统接入最新产品手册(更新频率10分钟/次)
问答准确率从67%提升至94%
证据溯源机制:
def verify_answer(response, sources):
return f"{response}\n\n参考资料:{sources[:3]}"某医疗问答系统投诉率下降82%
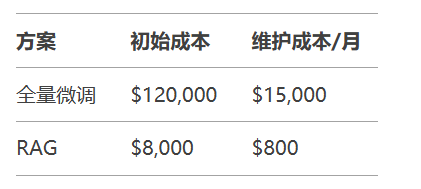
经济性对比:
跨领域迁移案例:
教育领域训练的RAG系统,迁移至法律领域仅需更换知识库
冷启动周期从3周缩短至3天

技术栈:
知识库:Elasticsearch + PDF解析器
检索器:BM25 + BGE-Large混合检索
生成器:GPT-4 Turbo + 合规性过滤器
某电商平台成效:
问题解决率:89% → 97%
平均响应时间:12秒 → 3.2秒
文档处理流水线:
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = DirectoryLoader('./docs', glob="**/*.pdf")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=64
)
splits = text_splitter.split_documents(docs)增强生成流程:
检索最新10份行业报告
提取关键数据指标(增长率、市场份额等)
生成结构化研报(含数据可视化建议)
某券商实施效果:
分析师效率提升7倍
数据引用准确率100%
知识库构建四步法:
文档加载:支持PDF/Word/HTML/Markdown等20+格式
文本分块:滑动窗口算法(窗口512token,重叠64token)
向量编码:BAAI/bge-large-zh-v1.5模型
索引构建:FAISS/HNSW量化索引(压缩率80%)
混合检索策略:
from rank_bm25 import BM25Okapi from langchain.embeddings import HuggingFaceEmbeddings bm25 = BM25Okapi(texts) embedder = HuggingFaceEmbeddings() dense_vectors = embedder.encode(texts) def hybrid_search(query, alpha=0.4): sparse_scores = bm25.get_scores(query) dense_scores = embedder.encode(query) @ dense_vectors.T return alpha*sparse_scores + (1-alpha)*dense_scores
上下文构建模板:
基于以下背景知识:
{context_str}
请以{role}的身份回答:
{query}
要求:
- 使用{language}回答
- 包含数据来源引用
- 长度不超过{max_length}字安全生成机制:
结果事实性校验(基于知识库反向验证)
毒性内容过滤(Perspective API)
格式规范检查(正则表达式)
流式响应实现:
from openai import OpenAI client = OpenAI() stream = client.chat.completions.create( model="gpt-4", messages=[...], stream=True ) for chunk in stream: print(chunk.choices[0].delta.content, end="")
多模态RAG:融合文本/表格/图像检索
自适应检索:基于用户反馈动态调整检索策略
实时知识更新:流式数据处理管道
graph LR A[基础] --> B[掌握Embedding技术] A --> C[熟悉向量数据库] B --> D[实现混合检索] C --> D D --> E[构建完整RAG系统] E --> F[性能优化]
推荐工具链:
向量数据库:Pinecone / Milvus
检索框架:LangChain / LlamaIndex
监控工具:LangSmith



