核心场景:解决大模型知识滞后问题,通过搜索引擎获取实时信息
from langchain_community.tools import DuckDuckGoSearchRun
# 初始化搜索工具
search = DuckDuckGoSearchRun()
result = search.invoke("OpenAI 2025年最新模型发布计划")
print(result) # 返回简洁文本摘要from langchain_community.utilities import DuckDuckGoSearchAPIWrapper
# 定制化搜索参数
wrapper = DuckDuckGoSearchAPIWrapper(
region="zh-cn", # 中文结果
max_results=3, # 限制结果数
time="y" # 最近一年信息
)
search = DuckDuckGoSearchResults(api_wrapper=wrapper)
result = search.invoke("量子计算机最新突破")
print(result[0]['title'], result[0]['link']) # 输出标题和链接# 通过代理API提升稳定性:cite[1] proxy_wrapper = DuckDuckGoSearchAPIWrapper( api_endpoint="http://your-proxy-domain.com", # 自建代理服务 max_results=5 )
避坑指南:公共API存在频率限制,建议使用代理或自建网关服务
核心价值:开源、去中心化的搜索引擎,保护隐私且可定制搜索源
# settings.yml 启用JSON输出:cite[8] search: formats: - html - json # 必须启用API格式
from langchain_community.utilities import SearxSearchWrapper
# 连接自建实例
searx = SearxSearchWrapper(searx_host="http://localhost:8888")
results = searx.run("Llama3微调教程", engines=["github"])
# 作为Agent工具使用:cite[2]
tools = load_tools(["searx-search"], searx_host="http://localhost:8888")
agent = initialize_agent(tools, llm, agent="structured-chat-react")# 创建专用工具链:cite[8]
github_tool = SearxSearchResults(
name="Github_Search",
wrapper=wrapper,
kwargs={"engines": ["github"]}
)
arxiv_tool = SearxSearchResults(
name="Arxiv_Search",
wrapper=wrapper,
kwargs={"engines": ["arxiv"]}
)核心挑战:PDF/Word/HTML等格式的差异化解构
from langchain_community.document_loaders import (
PyPDFLoader,
Docx2txtLoader,
UnstructuredHTMLLoader
)
# PDF解析(保留布局)
pdf_loader = PyPDFLoader("report.pdf")
pdf_pages = pdf_loader.load_and_split()
# Word解析(过滤样式噪声)
docx_loader = Docx2txtLoader("manual.docx")
text = docx_loader.load()[0].page_content
# HTML解析(动态渲染)
html_loader = UnstructuredHTMLLoader(
"page.html",
bs_kwargs={"features": "lxml"}
)import pdfplumber
# 提取PDF表格:cite[3]
with pdfplumber.open("financial.pdf") as pdf:
page = pdf.pages[0]
table = page.extract_table()
for row in table:
print(row[0], row[1]) # 输出单元格数据
前沿技术:Meta-Chunking动态分块策略
固定长度切割破坏句子完整性
语义边界识别不准(如代词跨块指代)
from langchain_experimental.text_splitter import SemanticChunker from langchain_community.embeddings import HuggingFaceEmbeddings # 基于语义相似度的动态分块 splitter = SemanticChunker( HuggingFaceEmbeddings(model_name="BAAI/bge-base-zh"), breakpoint_threshold=0.5 # 相似度低于阈值时切分 ) chunks = splitter.split_text(long_document)
原理:先整文档向量化 → 再按需分块 → 避免上下文丢失
效果:代词召回率提升25%(如“它”正确指向“柏林”)
架构图:

import chromadb
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
# 初始化客户端
client = chromadb.PersistentClient(path="./vector_db")
collection = client.create_collection(
name="tech_docs",
embedding_function=OpenAIEmbeddingFunction()
)
# 写入数据
collection.add(
documents=["量子计算原理...", "区块链技术..."],
metadatas=[{"source": "doc1"}, {"source": "doc2"}],
ids=["id1", "id2"]
)
# 相似查询
results = collection.query(
query_texts=["量子比特的物理实现"],
n_results=2
)混合索引:HNSW + 量化压缩(减少40%内存占用)
元数据过滤:where={"date": {"$gte": "2024-01-01"}}
多向量支持:为同一文档存储摘要/关键词/正文向量
完整架构图:
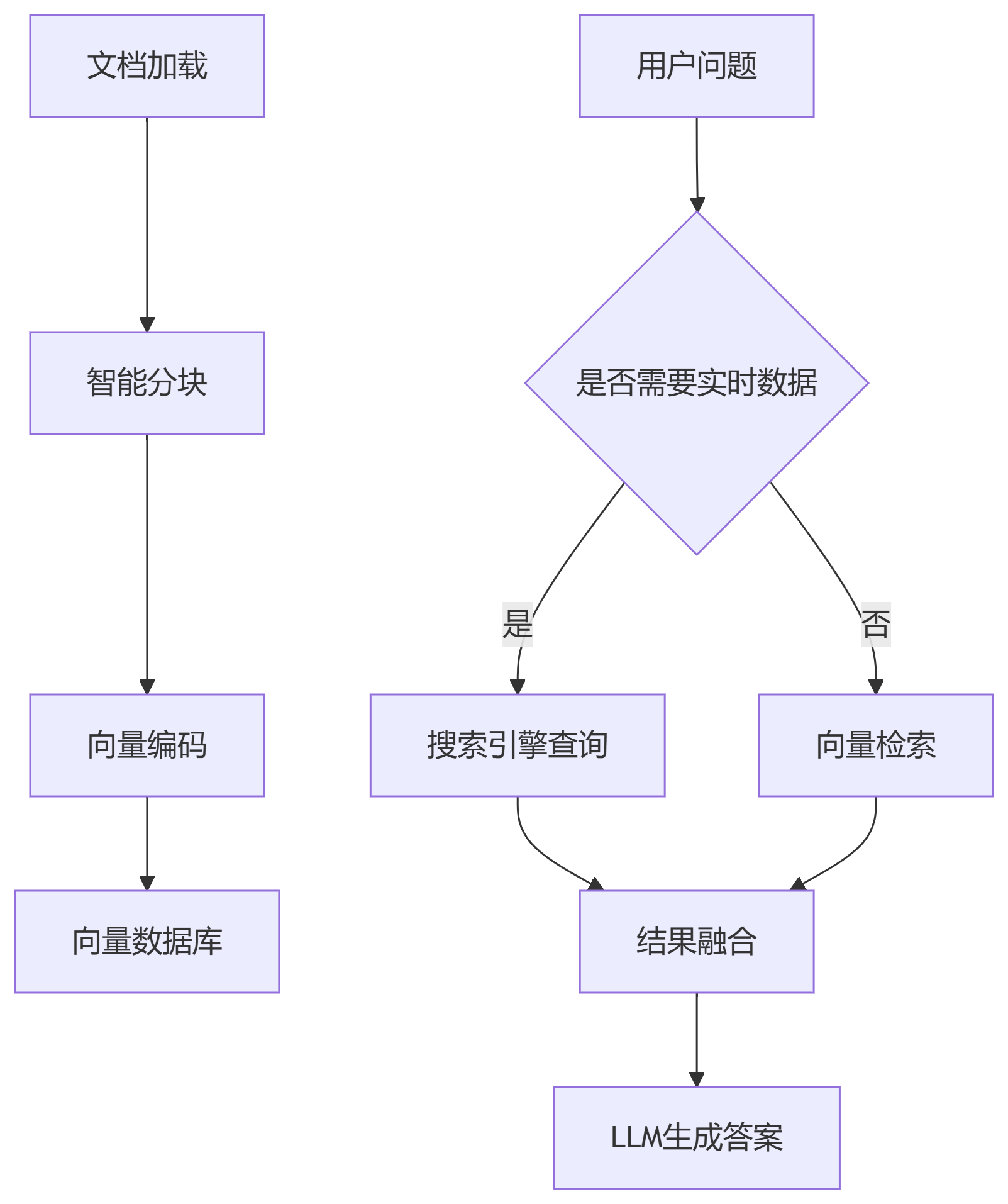
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 构建混合检索链
retriever = vector_db.as_retriever(search_kwargs={"k": 3})
qa_chain = (
{
"context": lambda x: format_results(
retriever.invoke(x["query"]),
"question": RunnablePassthrough()
}
| prompt
| ChatOpenAI(model="gpt-4o")
| StrOutputParser()
)
# 动态路由:根据问题类型选择来源
def route_query(input):
if "最新" in input["query"] or "2025" in input["query"]:
return search_tool.invoke(input["query"])
else:
return retriever.invoke(input["query"])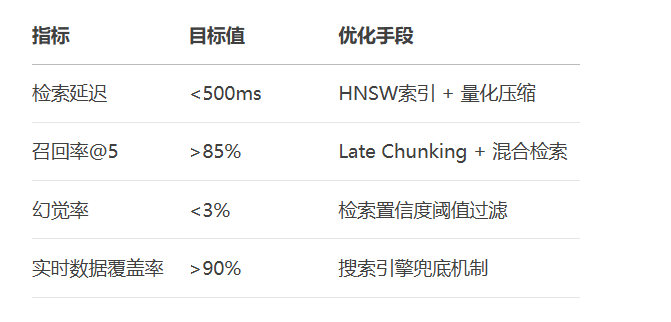
完整代码库可参考我为大家整理的飞书文档:https://wcnolv4zdyoz.feishu.cn/wiki/R3R1wr4Wtio81TkIP9qcGW0Qncc?from=from_copylink
更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



