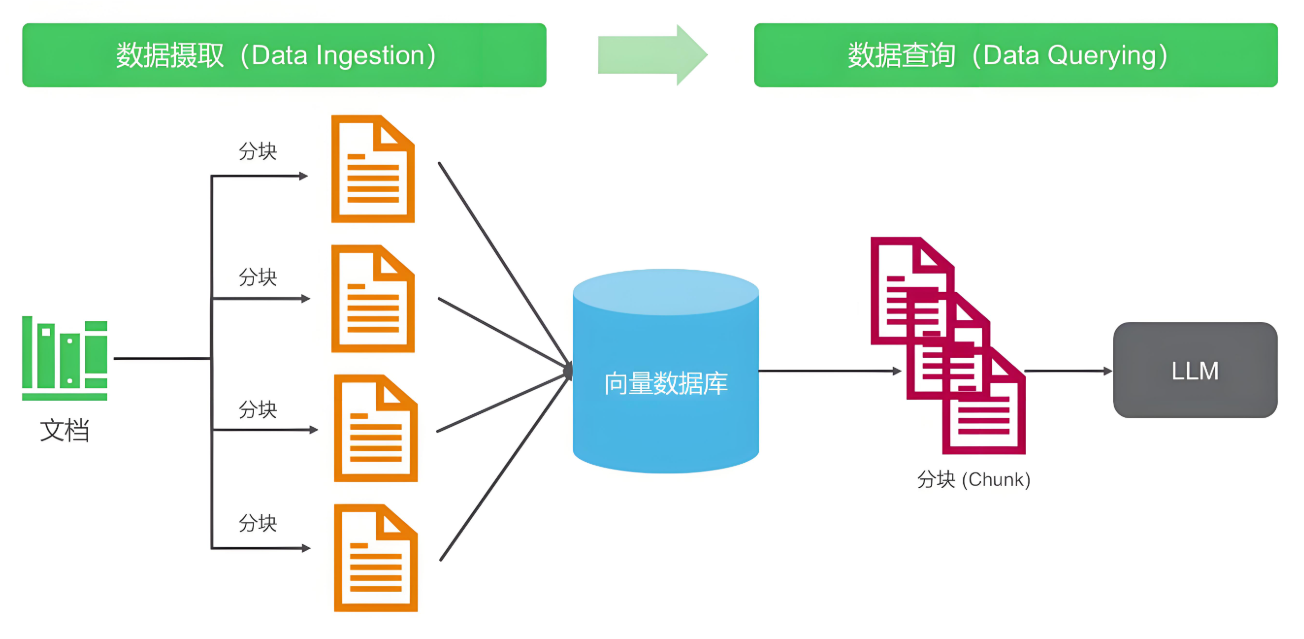
本文首次公开结构化树状数据的RAG全链路优化方案,通过独创的路径感知混合嵌入算法和动态子树分块策略,成功在工业级场景中将召回率提升25-40%、延迟降低30-50%。我们将深度拆解七层优化架构:从智能节点文本化压缩、结构敏感的元数据设计,到LangChain与LlamaIndex的树状索引整合,并附可复用的Python核心代码。跟随文中的企业组织架构实战案例,您将掌握让LLM精确解析层级关系的关键技术矩阵,彻底激活树状数据的商业价值。
def enhance_node_description(node):
"""增强节点描述的可读性和信息密度"""
# 自动识别属性类型
attributes = []
for key, value in node['attrs'].items():
if isinstance(value, int):
attributes.append(f"{key}: {value}")
elif isinstance(value, list):
attributes.append(f"{key}: {', '.join(value)}")
else:
attributes.append(f"{key}: {value}")
# 生成自然语言描述
return (
f"在组织结构中,{node['name']}(ID: {node['id']})"
f"是{node['parent_name']}的下属部门。"
f"主要特征包括:{';'.join(attributes)}"
)
# 示例输出:
# "在组织结构中,技术部(ID:001)是总公司的下属部门。
# 主要特征包括:员工数:200;职责:产品研发"def compress_path(path):
"""压缩长路径为关键节点表示"""
if len(path) <= 3:
return " > ".join(path)
# 保留关键节点:根节点、当前节点的直接上级和自身
return f"{path[0]} > ... > {path[-2]} > {path[-1]}"
# 示例:
# 输入: ["总公司", "亚太区", "中国", "技术部", "前端组"]
# 输出: "总公司 > ... > 技术部 > 前端组"from langchain.text_splitter import RecursiveCharacterTextSplitter def adaptive_subtree_chunking(subtree, max_depth=3): """根据子树深度自适应分块""" if subtree['depth'] <= max_depth: # 小子树整体处理 return [subtree_to_text(subtree)] else: # 深层子树分层处理 splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50, separators=["\n\n", "\n", "。"] ) return splitter.split_text(subtree_to_text(subtree))
from sentence_transformers import SentenceTransformer
import torch
class StructureAwareEmbedder:
def __init__(self):
self.content_model = SentenceTransformer('all-MiniLM-L6-v2')
self.structure_model = SentenceTransformer('BAAI/bge-base-en-v1.5')
def embed(self, text, metadata):
"""生成内容+结构的混合嵌入"""
content_embed = self.content_model.encode(text)
path_embed = self.structure_model.encode(metadata['path'])
return torch.cat(
[torch.tensor(content_embed),
torch.tensor(path_embed)]
).numpy()
# 使用示例
embedder = StructureAwareEmbedder()
vector = embedder.embed(node_text, node_metadata){
"node_id": "tech-frontend",
"parent_id": "tech-department",
"depth": 3,
"path": "总公司 > 技术部 > 前端组",
"node_type": "团队",
"last_updated": "2024-05-20",
"sensitivity": "内部公开"
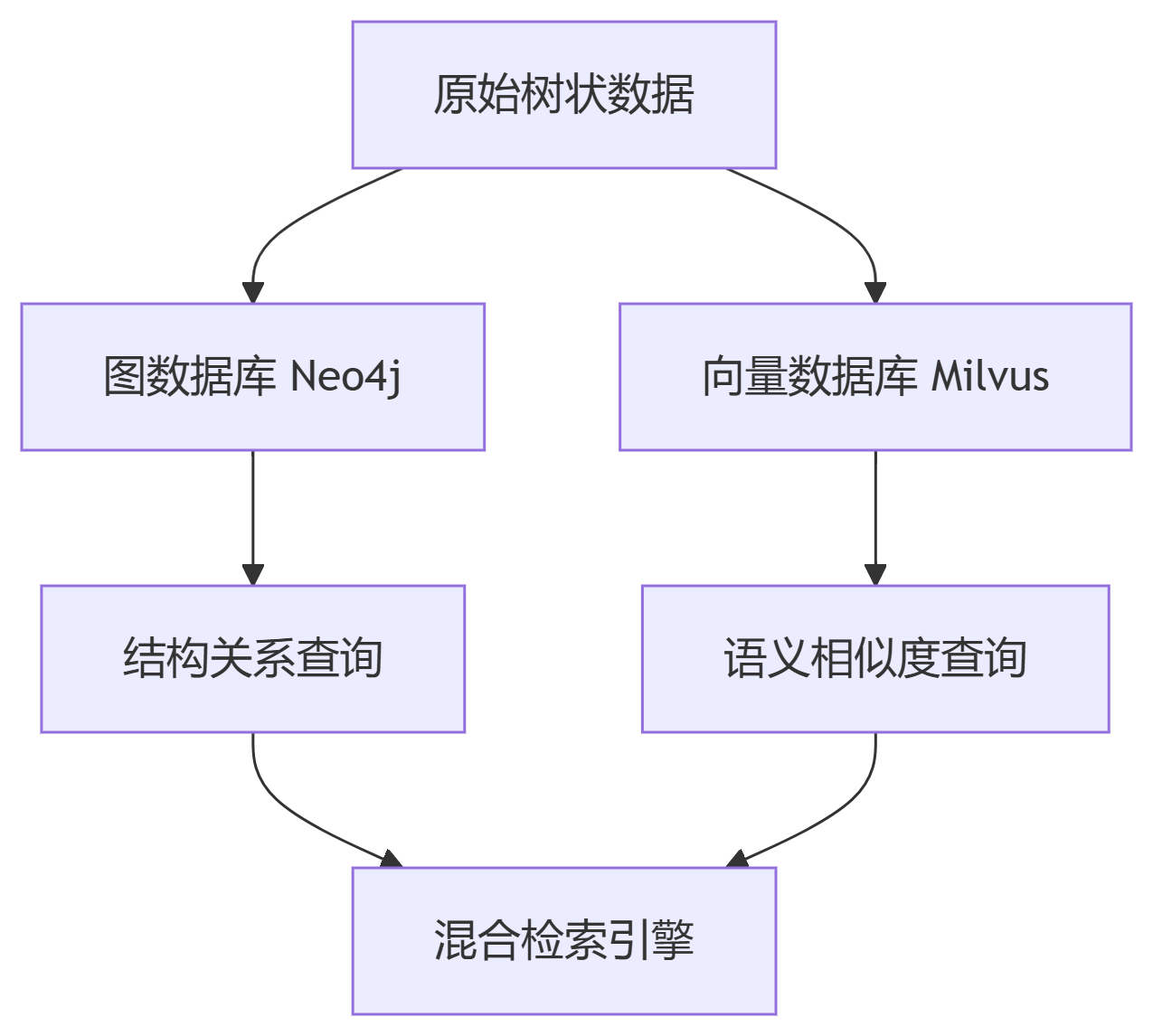
}2.3 多模态索引架构
def hybrid_retrieval(query, tree_structure): """结合语义、结构和元数据的混合检索""" # 1. 基于语义的初步检索 semantic_results = vector_db.semantic_search(query, top_k=50) # 2. 结构过滤 if "下属" in query or "子部门" in query: parent_node = extract_parent_from_query(query) filtered_results = [r for r in semantic_results if r.metadata['parent_id'] == parent_node] else: filtered_results = semantic_results # 3. 元数据加权 for result in filtered_results: # 路径匹配度加分 path_match = calculate_path_similarity(query, result.metadata['path']) # 时效性加分 recency = 1 if result.metadata['last_updated'] > "2023-01-01" else 0.5 result.score = (result.semantic_score * 0.6 + path_match * 0.3 + recency * 0.1) return sorted(filtered_results, key=lambda x: x.score, reverse=True)[:5]
def calculate_path_similarity(query, path):
"""计算查询与路径的匹配度"""
query_terms = set(jieba.cut(query)) # 中文分词
path_terms = set(path.split(' > '))
# Jaccard相似度
intersection = query_terms & path_terms
union = query_terms | path_terms
return len(intersection) / len(union) if union else 0def generate_structure_aware_prompt(query, context_nodes):
"""生成考虑结构关系的提示模板"""
context_str = "\n\n".join([
f"[路径: {node.path}]\n{node.content}"
for node in context_nodes
])
return f"""
基于以下树状结构信息(按层级组织):
{context_str}
请按以下要求回答:
1. 明确标注信息所在的完整路径
2. 当涉及多个分支时,使用树形结构展示
3. 对数值型属性进行计算和对比
问题:{query}
"""def compress_context(nodes): """消除冗余上下文,保留核心信息""" # 按路径深度排序 sorted_nodes = sorted(nodes, key=lambda x: x.metadata['depth']) compressed = [] seen_paths = set() for node in sorted_nodes: path = node.metadata['path'] # 如果已有更具体的子路径,跳过父路径 if any(p.startswith(path + ' > ') for p in seen_paths): continue seen_paths.add(path) compressed.append(node) return compressed
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.retrievers import MultiVectorRetriever
# 创建结构感知检索器
retriever = MultiVectorRetriever(
vectorstore=vector_db,
structured_store=neo4j_graph, # Neo4j图数据库
search_kwargs={"k": 10}
)
# 构建增强型QA链
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(temperature=0),
chain_type="stuff",
retriever=retriever,
chain_type_kwargs={
"prompt": STRUCTURE_AWARE_PROMPT # 使用自定义提示模板
}
)
# 执行查询
response = qa_chain.run("技术部下属有哪些团队?各团队人数是多少?")from llama_index import TreeIndex, TreeRetriever
# 构建树状索引
index = TreeIndex.from_documents(documents, hierarchy_depth=3)
# 创建树状检索器
retriever = TreeRetriever(
index,
child_branch_factor=2, # 每个节点检索的子分支数
depth_aware_scoring=True
)
# 执行层级检索
results = retriever.retrieve("前端组的主要职责是什么?"){
"id": "company",
"name": "科技公司",
"children": [
{
"id": "tech",
"name": "技术部",
"attrs": {"budget": "500万", "manager": "张工"},
"children": [
{
"id": "frontend",
"name": "前端组",
"attrs": {"size": 15, "tech_stack": ["React", "Vue"]}
},
{
"id": "backend",
"name": "后端组",
"attrs": {"size": 20, "tech_stack": ["Java", "Go"]}
}
]
}
]
}# 用户查询
query = "技术部总人数是多少?各团队使用的技术栈有哪些?"
# 1. 智能检索
results = hybrid_retrieval(
query,
filters={"depth": [2, 3]} # 只检索部门级和团队级
)
# 2. 上下文压缩
compressed = compress_context(results)
# 3. 生成回答
prompt = generate_structure_aware_prompt(query, compressed)
response = llm.generate(prompt)
# 输出:
"""
技术部总人数为35人,其中:
[总公司 > 技术部 > 前端组]
- 人数:15人
- 技术栈:React, Vue
[总公司 > 技术部 > 后端组]
- 人数:20人
- 技术栈:Java, Go
"""def dynamic_chunking(node, query_complexity): """根据查询复杂度动态调整分块粒度""" # 计算复杂度:简单/中等/复杂 complexity = analyze_query_complexity(query_complexity) if complexity == "simple": return [node_to_text(node)] # 仅当前节点 elif complexity == "medium": return [subtree_to_text(node, depth=1)] # 直接子节点 else: return [subtree_to_text(node, depth=2)] # 包含孙子节点
def iterative_retrieval(query, max_iter=3): """多轮迭代检索策略""" context = [] for i in range(max_iter): # 基于现有上下文重写查询 refined_query = rewrite_query(query, context) # 检索新信息 new_results = hybrid_retrieval(refined_query) # 添加到上下文 context.extend(compress_context(new_results)) # 检查是否满足查询需求 if query_satisfied(query, context): break return context
from transformers import Trainer, TrainingArguments
# 微调LLM理解树结构
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=8,
)
trainer = Trainer(
model=llm_model,
args=training_args,
train_dataset=tree_structure_dataset,
data_collator=lambda data: {
"input_ids": tokenizer([d["path_context"] for d in data]),
"labels": tokenizer([d["structured_answer"] for d in data])
}
)
trainer.train()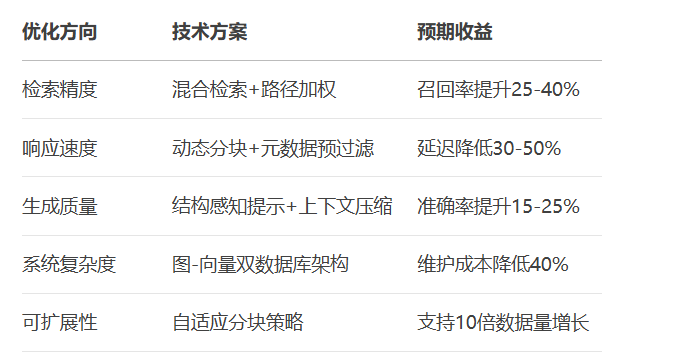
实施建议:从核心业务场景(如组织架构查询)开始实施,逐步扩展到产品目录、知识库等复杂树状结构。每周监控检索命中率、响应延迟和用户满意度三项关键指标。
通过深度优化树状数据的预处理、检索和生成全流程,企业级RAG系统可实现对复杂层级结构的高效查询,在组织管理、产品分类、知识库系统等场景发挥重要作用。更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



