RAG系统的标准工作流包含三个关键阶段:
知识库构建:将文档分割为语义块 → 生成向量嵌入 → 存储至向量数据库
实时检索:将用户查询向量化 → 检索Top-K相关文本块
生成响应:将检索结果与查询拼接 → 输入LLM生成最终答案



# LangChain实现示例 from langchain.text_splitter import CharacterTextSplitter splitter = CharacterTextSplitter( chunk_size=500, chunk_overlap=50, # 关键重叠区 separator="\n" ) chunks = splitter.split_documents(docs)

假设我从第一个片段及其嵌入开始。
如果第一个段的嵌入与第二个段的嵌入具有较高的余弦相似度,则这两个段形成一个块。
这种情况一直持续到余弦相似度显著下降。
一旦发生这种情况,我们就开始新的部分并重复。
输出可能如下所示:

# 基于SBERT的语义边界检测
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
def semantic_chunking(sentences, threshold=0.85):
chunks = []
current_chunk = [sentences[0]]
for i in range(1, len(sentences)):
emb1 = model.encode(current_chunk[-1])
emb2 = model.encode(sentences[i])
sim = cosine_similarity(emb1, emb2)
if sim > threshold:
current_chunk.append(sentences[i])
else:
chunks.append(" ".join(current_chunk))
current_chunk = [sentences[i]]
return chunks

如上图:
首先,我们定义两个块(紫色的两个段落)。
接下来,第 1 段被进一步分成更小的块。
与固定大小的块不同,这种方法还保持了语言的自然流畅性并保留了完整的想法。然而,在实施和计算复杂性方面存在一些额外的消耗。


# 基于BeautifulSoup的HTML结构解析 from bs4 import BeautifulSoup def html_chunking(html): soup = BeautifulSoup(html, 'html.parser') chunks = [] for section in soup.find_all(['h1', 'h2', 'h3']): chunk = section.text + "\n" next_node = section.next_sibling while next_node and next_node.name not in ['h1','h2','h3']: chunk += str(next_node) next_node = next_node.next_sibling chunks.append(chunk) return chunks

# GPT-4提示词设计
你是一位专业文本分析师,请根据语义完整性将以下文档分割为多个段落块:
要求:
1. 每个块包含完整语义单元
2. 最大长度不超过512token
3. 输出JSON格式:{"chunks": ["text1", "text2"]}
文档内容:{{document_text}}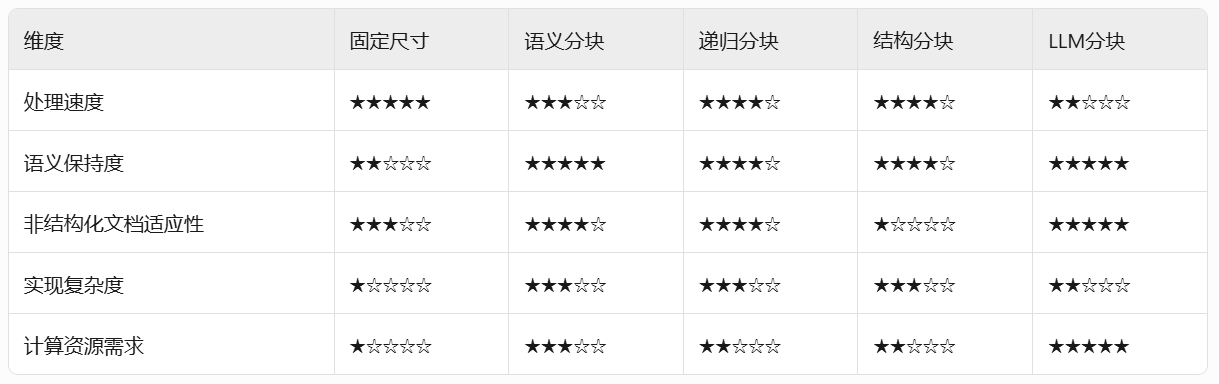
好了,相信你们对RAG分块策略有了一个更深的认识,如果本文对你有所帮助,记得分享给身边有需要的朋友,我们下期见。



