RAG(检索增强生成)通过融合外部知识库与LLM生成能力,解决了传统大模型的知识滞后性、幻觉问题。但RAG并非固定架构,而是一套可动态组合的技术体系。本文将拆解三类策略、17种实现方案,并给出工程选型指南。
基础分块(Simple RAG)
原理:文本→向量化→TopK检索→拼接生成
痛点:易割裂语义连续性

语义分块(Semantic Chunking)
使用句法树/NLP模型动态切割,保留完整语义单元
关键技术:Transformer Embedding + 动态窗口

上下文增强(Context Enriched)
为每个块添加前后邻居段落,组成"上下文块"
优势:提升长文档推理连贯性

块头标签(Contextual Headers)
提取标题/章节名作为元数据嵌入向量
适用场景:技术手册、法律文书等结构化文档

文档增强(Augmentation)
构建多视图数据:摘要+正文+元数据
工具推荐:ChunkRAG的多向量索引
# 伪代码示例:多视图向量化 doc_views = [extract_summary(doc), doc.body, doc.metadata] embeddings = [embed(view) for view in doc_views]
查询改写(Query Transformation)
用LLM生成同义问题,扩大检索覆盖面
LangChain实现:MultiQueryRetriever

重排序(Reranker)
对TopK结果用Cross-Encoder二次打分
模型选择:Cohere Reranker (精度↑30%)

相关片段提取(RSE)
在长段落中定位关键句子
技术方案:BERT + Pointer Network
# RSE核心逻辑 relevant_span = pointer_net(question, retrieved_chunk)
上下文压缩(Contextual Compression)
剔除无关文本,降低token消耗
LangChain组件:ContextCompressor

反馈闭环(Feedback Loop)
用户点击数据→训练排序模型
适用场景:智能客服对话日志
自适应路由(Adaptive RAG)
根据问题类型动态选择检索策略
实现方案:LangChain Router

自我决策(Self RAG)
LLM判断是否需外部检索
Prompt设计示例: [系统] 请评估:能否直接回答该问题?若不能,请说明所需信息。
知识图谱融合(Knowledge Graph)
文档→三元组→图谱推理
工具链:Neo4j + TransE嵌入

多级索引(Hierarchical Indices)
构建文档树形索引,分层检索
FAISS优化:Nested Indexing

假设文档嵌入(HyDE)
生成理想答案→反向检索支撑材料
解决碎片化文档难题

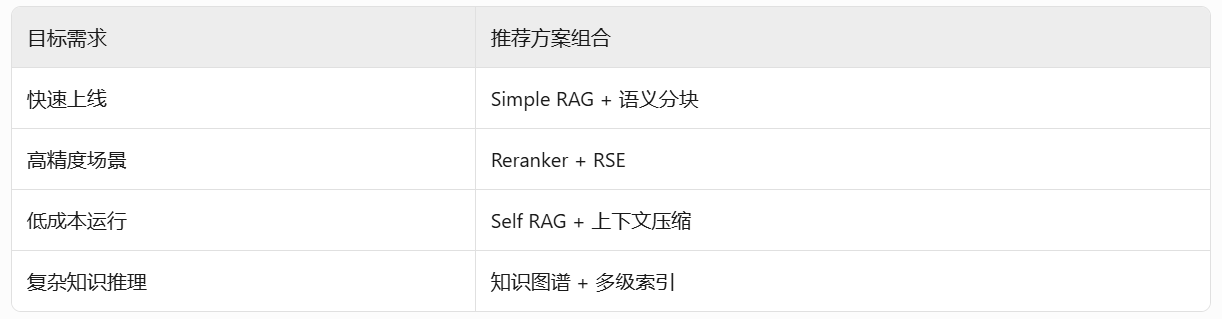
笔者建议:实际需根据数据规模、响应延迟、预算综合设计
RAG系统的核心竞争力在于模块化组合能力:
文档分块决定知识表示质量
检索排序影响信息命中精度
反馈机制驱动系统持续进化




