随着大语言模型(LLM)在生成式AI产业中广泛应用,如何高效、经济地部署和推理这些庞大的模型,成为每一位开发者和企业面临的核心挑战。尤其是在构建真实的在线AI应用时,性能瓶颈、资源浪费、高昂费用等问题层出不穷。
今天,我要分享一个开源项目——vLLM,正是为了破解这一难题而生。它不仅提供了极致高效的推理性能,还兼具易用性和灵活性,成为LLM服务领域的新宠。

传统LLM推理面临三重挑战:
显存墙:KV缓存占用大量GPU内存(例如Llama-70B需>140GB显存)
吞吐瓶颈:静态批处理(Static Batching)导致资源闲置(空闲率达40%+)
响应延迟:串行处理使长文本生成延迟飙升(百毫秒→秒级)
行业痛点示例:
当并发请求达50QPS时,传统方案需8×A100才能维持,而vLLM仅需3×A100。

核心原理:将KV缓存分割为固定大小块(如4MB/块),模拟OS虚拟内存管理
三大突破:
块级共享:相同前缀的请求共享物理块(如系统提示词)
零碎片化:Block池动态分配,显存利用率达99.8%
按需加载:仅活跃块保留在GPU显存中
✅ 实测效果:
70B模型推理显存下降4.2倍,单卡可同时处理192个对话上下文。

工作流:
while True: ready_requests = get_ready_requests() # 获取解码阶段相同的请求 output_tokens = decode(ready_requests) # 批量并行解码 stream_results() # 流式返回已生成内容
关键优势:
动态插入新请求,无需等待批次填满
不同请求处于不同解码阶段(prefill/decode)
吞吐量提升8-10x(HuggingFace对比)
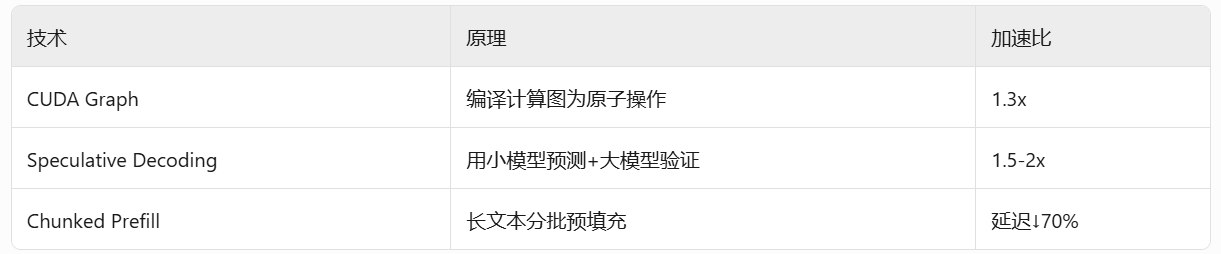
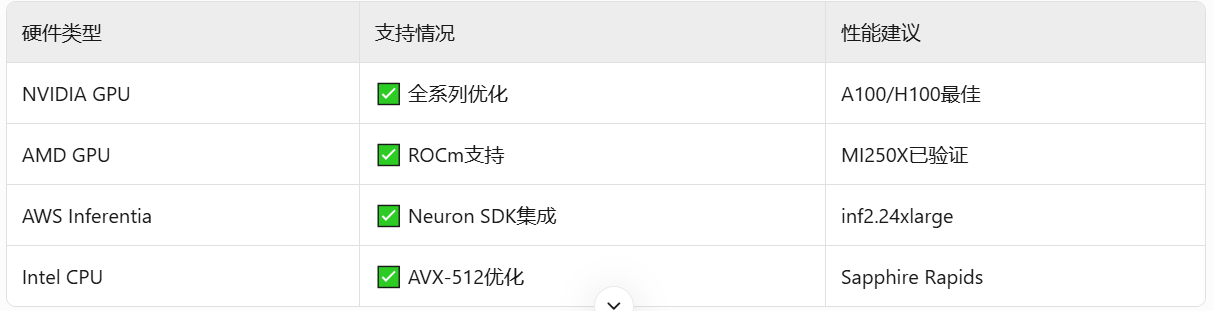
# 启动Llama3-70B服务(张量并行+量化) vllm-serving --model meta-llama/Meta-Llama-3-70B-Instruct \ --tensor-parallel-size 8 \ --quantization awq \ --max-model-len 128000
热门模型适配情况:
全系列Transformer:LLaMA、Qwen、Mixtral
MoE架构:DeepSeek-V2(激活专家路由优化)
多模态:LLaVA(图像特征对齐KV缓存)

关键配置参数:
# 性能调优核心参数
engine_args = {
"max_num_seqs": 256, # 最大并发序列数
"gpu_memory_utilization": 0.95, # 显存利用率阈值
"enforce_eager": False # 启用CUDA Graph
}(数据源:vLLM官方基准测试)
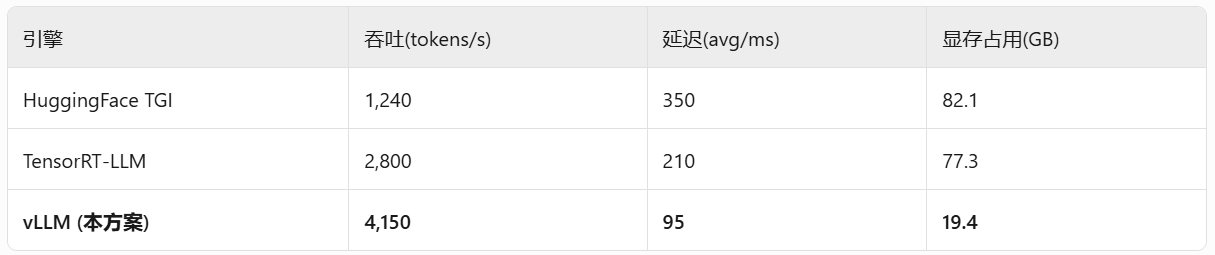
测试环境:
LLaMA-13B模型 + 50并发请求 + A100-80G
# 结合LangChain的vLLM调用 retriever = VectorStoreRetriever() llm = VLLMOpenAI( model="qwen-72b-chat", max_tokens=2048, temperature=0.3 ) chain = RetrievalQA.from_chain_type(llm, retriever)
▶ 效果:知识问答响应时间从1.2s → 0.4s
用户图片 → CLIP编码器 → 特征存入KV缓存 → LLaVA-vLLM联合推理
Prefix Caching
复用相同提示词的KV块(如企业系统指令)
千次重复查询显存零增长
异构硬件支持
自动分割计算图(GPU/CPU/NPU协同)
推理时延波动降低63%
模块化执行引擎
class VLLMBackend {
void AddRequest(Request& req); // 异步请求注入
void Step(); // 并行执行核
void StreamOutput(); // 流式回调
}# 安装+启动服务(支持OpenAI API协议) pip install vllm vllm-api --model mistralai/Mistral-7B-Instruct # 调用示例(等效OpenAI客户端) from vllm import Completion response = Completion.create( model="mistral-7b", prompt="如何优化LLM推理效率?", temperature=0.7 )
扩展建议:
结合FastChat构建ChatGPT式界面:python -m fastchat.serve.vllm_worker --model-path meta-llama/Llama-3-70b-chat-hf
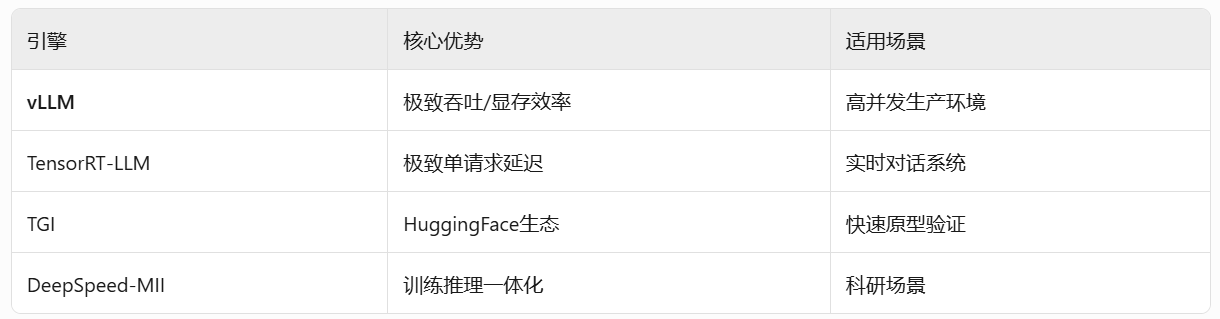
好了,今天的分享就到这里,如果对你有所帮助,记得告诉身边有需要的人。我们下期见。



