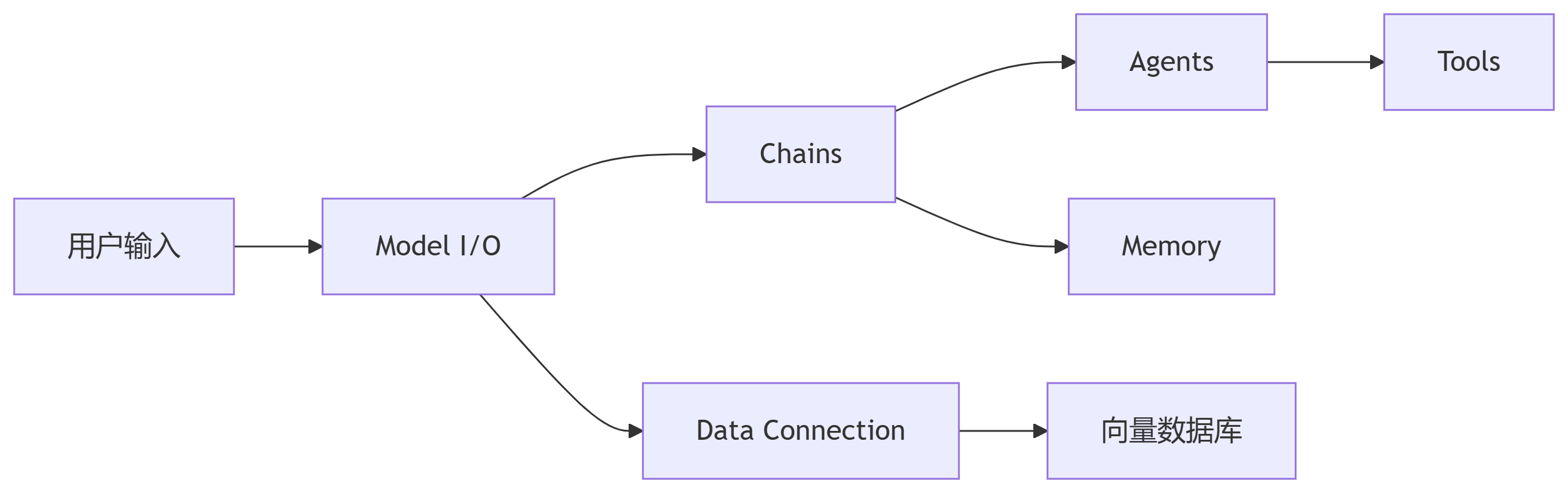
LangChain 通过模块化组件连接大语言模型(LLM)与外部系统,解决LLM的三大局限:
无状态性:通过 Memory 管理上下文
知识滞后:通过 Data Connection 接入实时数据
功能单一:通过 Agents 调用工具链
LangChain 0.1.x 引入声明式链构建语法:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_template("翻译 {text} 到{target_language}")
model = ChatOpenAI(model="gpt-4o")
chain = prompt | model | StrOutputParser() # 管道运算符组合组件
print(chain.invoke({"text": "Hello World", "target_language": "法语"}))
# 输出: Bonjour le monde文档总结链(融合检索与生成):
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Chroma
# 1. 构建向量库
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings())
# 2. 创建总结链
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
retriever=vectorstore.as_retriever(),
chain_type="stuff" # 简单文档拼接
)
response = qa_chain.run("量子计算的主要挑战是什么?")💡 关键技巧:chain_type="map_reduce" 处理长文档时避免上下文丢失
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
# 1. 加载文档
loader = WebBaseLoader("https://example.com/tech-article")
docs = loader.load()
# 2. 智能分块(保留上下文)
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "。", "!"]
)
chunks = splitter.split_documents(docs)
# 3. 向量化存储
vectorstore = FAISS.from_documents(chunks, OpenAIEmbeddings())⚠️ 分割参数建议:技术文档用 chunk_size=500-800,对话数据用 chunk_size=300
prompt_template = """
你是一位{role},请根据历史对话回答问题:
{history}
当前问题:{input}
"""
prompt = ChatPromptTemplate.from_messages([
("system", "你正在扮演{role}"),
("human", "{user_query}")
])
from langchain.agents import create_tool_calling_agent
from langchain.tools import TavilySearchResults
# 1. 工具定义
search_tool = TavilySearchResults(max_results=2)
tools = [search_tool]
# 2. 代理创建
agent = create_tool_calling_agent(
llm=ChatOpenAI(model="gpt-4-turbo"),
tools=tools,
prompt=hub.pull("hwchase17/openai-functions-agent")
)
# 3. 执行查询
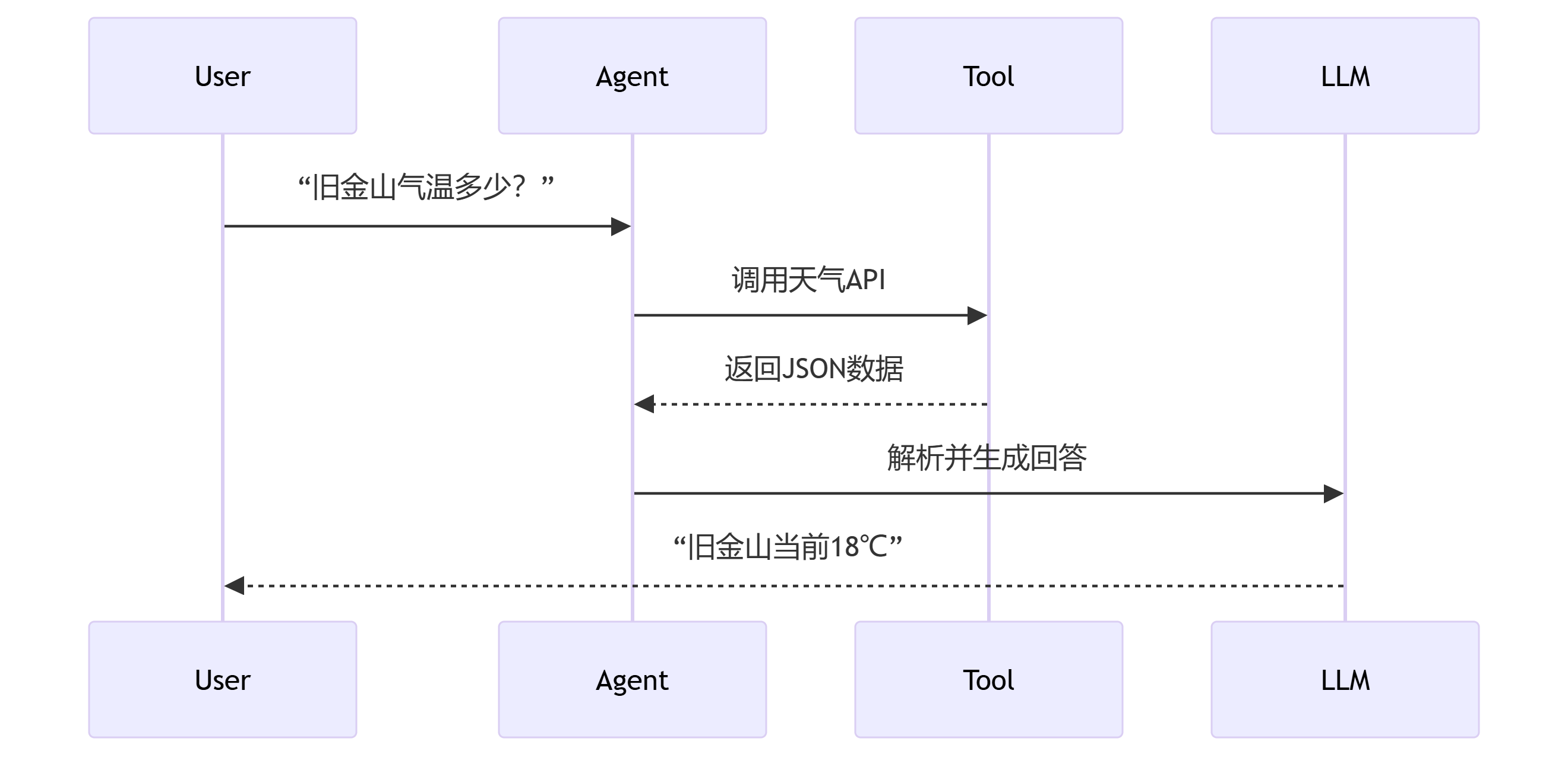
agent_executor.invoke({"input": "特斯拉2025年Q1营收增长率是多少?"})✅ 输出示例:
思考:需要查询特斯拉最新财报
动作:调用Tavily搜索工具
参数:{"query": "Tesla 2025 Q1 revenue growth"}
结果:同比增长28.5%
回答:特斯拉2025年第一季度营收同比增长28.5%from langchain.chains import TransformChain
def translate_pipeline():
# 1. 输入处理链
input_chain = TransformChain(
input_variables=["text", "target_lang"],
output_variables=["cleaned_text"],
transform=preprocess_text # 清理特殊字符
)
# 2. 翻译链
prompt = ChatPromptTemplate.from_template("将{text}翻译成{target_lang},保持专业术语准确")
llm_chain = prompt | ChatAnthropic(model="claude-3-sonnet") | StrOutputParser()
# 3. 后处理链
output_chain = TransformChain(...) # 术语校正
return input_chain | llm_chain | output_chain# 术语库向量检索
def retrieve_terms(query):
term_db = FAISS.load_local("glossary_vec")
return term_db.similarity_search(query)
# 翻译链增强
llm_chain = prompt | {
"context": lambda x: retrieve_terms(x["text"]),
"question": itemgetter("text")
} | llm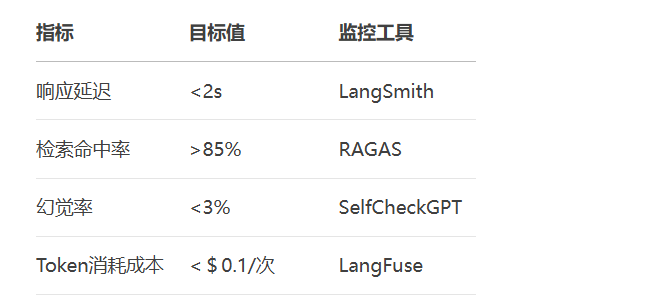
# 使用LangChain CLI部署 langchain deploy --app my_agent.py --name translation-agent # 启用实时追踪 export LANGCHAIN_TRACING_V2=true export LANGCHAIN_API_KEY="your_api_key"
结语:“LangChain 的真正力量在于将孤立的AI能力转化为可编排的工作流” ,更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



