
DeepSeek V3:
通用型模型:基于MoE架构,支持文本/图像/音频多模态处理,长文本生成能力突出
成本优势:训练成本仅为闭源模型的1/20(557.6万美元),API费用$0.14/百万tokens
DeepSeek R1:
推理专家:强化学习驱动,MATH-500测试准确率97.3%,支持思维链输出
行业突破:金融量化场景API成本仅为OpenAI的1/50,支持蒸馏至14B参数小模型
数据安全:企业敏感数据无需上云(如银行信贷风险评估场景)
成本优化:长期使用成本降低80%(对比云API调用)
定制扩展:支持模型微调与业务系统深度集成(如医疗影像诊断辅助)
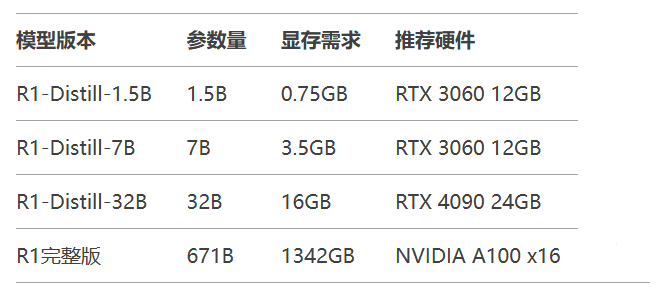
显存占用 = 参数量 × (量化位数/8) × 1.2(缓存系数) 例:FP16量化7B模型 → 7×10^9 × (16/8) × 1.2 = 16.8GB
量化策略:
FP32 → FP16:显存减半,精度损失<1%
FP16 → INT8:显存再减半,适合端侧部署
curl -fsSL https://ollama.com/install.sh | sh ollama -v # 验证安装
加载模型:
ollama run deepseek-r1:7b # 下载7B蒸馏版
可视化配置:
下载ChatBox客户端,设置模型提供方为Ollama API
环境变量配置:
OLLAMA_HOST=0.0.0.0 OLLAMA_ORIGINS=* ```:cite[6]:cite[10]
功能特性:
支持私有知识库接入
多模型并行管理
审计日志与权限控制
部署命令:
docker run -d -p 3000:3000 \ -v ~/anythingllm:/app/server/storage \ mintplexlabs/anything-llm
from llama_cpp import Llama
llm = Llama(
model_path="deepseek-r1-q4_0.gguf",
n_ctx=4096,
n_gpu_layers=20
)
print(llm("你好"))量化等级对比:

4.2 vLLM部署方案
# 安装环境 pip install vllm==0.3.0 # 启动服务 python -m vllm.entrypoints.api_server \ --model deepseek/r1-7b \ --tensor-parallel-size 2 \ --quantization awq
性能指标:RTX 4090单卡可达78 tokens/s
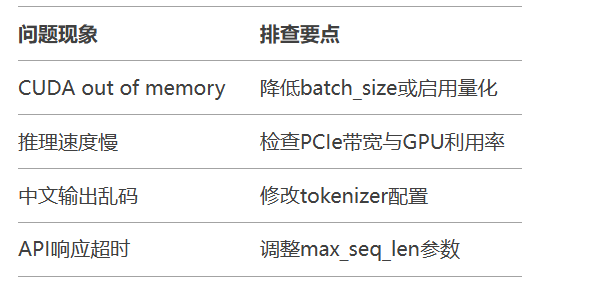
检查NVIDIA驱动≥535.86.05
CUDA 12.1环境配置
模型获取:
git lfs install git clone https://huggingface.co/deepseek/r1-7b
启动服务:
python -m fastchat.serve.controller \ --model-path ./r1-7b \ --device cuda \ --num-gpus 2
import requests
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": "deepseek-r1:7b",
"prompt": "解释量子纠缠现象",
"stream": False
}
)
print(response.json()["response"])动态批处理:合并多个请求减少IO开销
KV缓存复用:会话保持时重用历史缓存
算子融合:使用TensorRT优化计算图
本地化部署正经历三大变革:
硬件平民化:RTX 4090单卡可运行32B模型
工具标准化:Ollama+vLLM形成完整工具链
场景深化:从代码生成向医疗诊断等专业领域渗透



