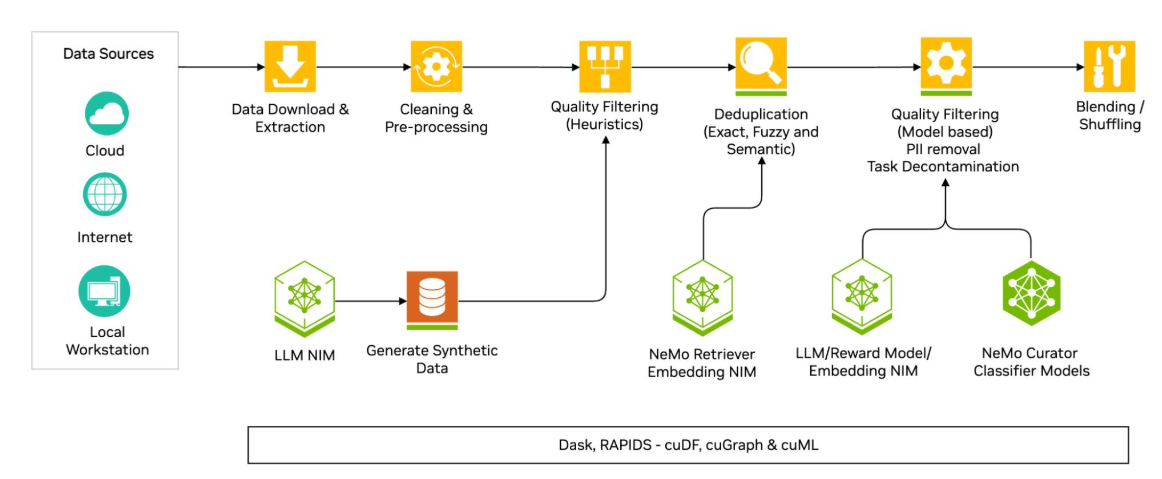
文档分块(Chunking)是将长文本分割为语义连贯的片段的过程,是构建高效检索系统的基础。其核心价值体现在:
上下文保留:确保每个分块包含完整语义单元(如段落、章节)
处理效率:将GB级文档转化为可管理的处理单元(通常512-1024 tokens)
检索精度:提升向量搜索的相关性(分块质量直接影响召回率)
工业级案例:某法律AI系统通过优化分块策略,合同条款检索准确率从68%提升至92%
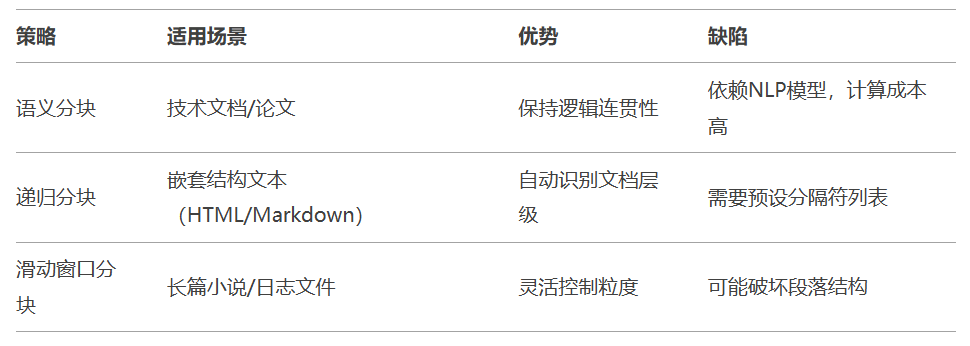
递归分块代码示例:
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, # 目标块大小 chunk_overlap=64, # 块间重叠 separators=["\n\n", "\n", "。", "!", "?"] # 分割符优先级 ) chunks = text_splitter.split_text(long_text)
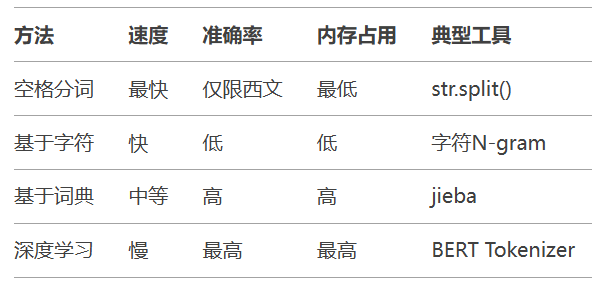
原始文本 → 字符级处理 → 词典匹配 → 统计模型 → 深度学习
中文分词难点:
无显式分隔符(对比英文空格分词)
歧义切分(如"研究生命"可切分为"研究/生命"或"研究生/命")
Jieba实战示例:
import jieba
jieba.load_userdict("custom_dict.txt") # 加载领域词典
text = "自然语言处理是人工智能的核心领域"
print(jieba.lcut(text))
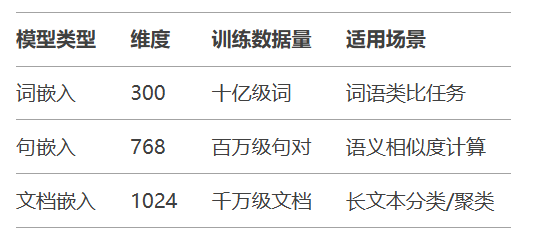
# 输出:['自然语言', '处理', '是', '人工智能', '的', '核心', '领域']Word2Vec → GloVe → BERT → Sentence-BERT → LLM Embeddings
技术指标对比:
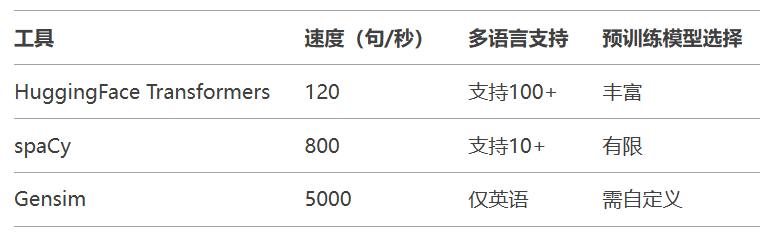
BERT向量提取示例:
from transformers import AutoTokenizer, AutoModel
import torch
model = AutoModel.from_pretrained("BAAI/bge-large-zh")
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-large-zh")
inputs = tokenizer("自然语言处理", return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)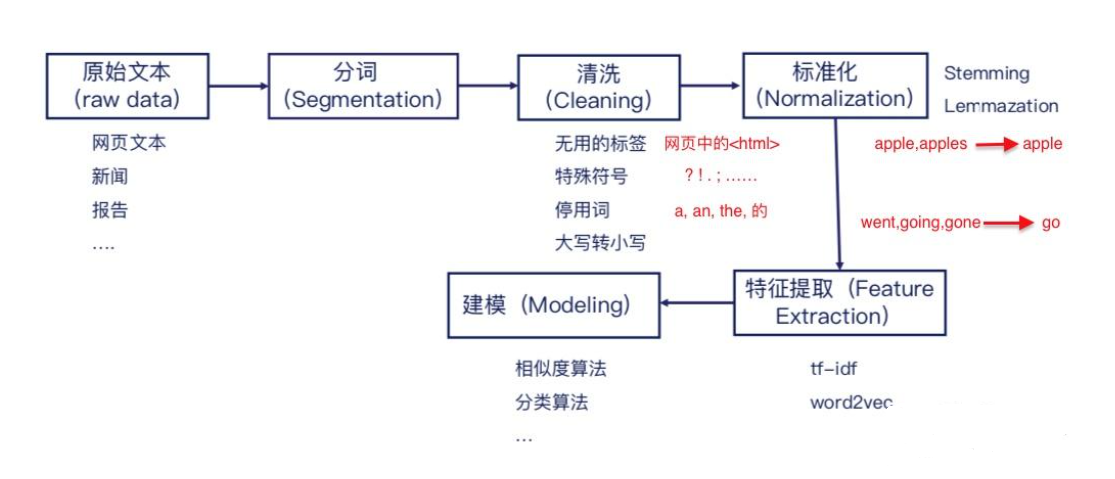
文档解析:PDF/Word/HTML格式转换
分块处理:滑动窗口+语义分块混合策略
文本清洗:去除噪音字符、标准化表达
分词优化:领域词典+深度学习联合切分
向量生成:动态选择嵌入模型
并行处理:
量化加速:FP32 → FP16使推理速度提升1.8倍 缓存机制:高频查询结果缓存命中率>85% 掌握文档分块、分词与向量嵌入技术,是构建高效NLP系统的关键基础。from multiprocessing import Pool
with Pool(8) as p:
chunks = p.map(split_func, doc_list)



