嵌入(Embedding)是将离散对象(单词、句子等)映射到连续向量空间的数学过程。给定文本对象 x,嵌入函数 f 满足:
f:x→v∈Rd
其中 d 为嵌入维度。语义相似性通过余弦相似度衡量:
sim(v1,v2)=∥v1∥∥v2∥v1⋅v2
核心特性:
稠密向量:每个维度编码文本的潜在语义特征
距离敏感:语义相似的文本在向量空间中距离更近
可计算性:支持向量加减实现语义组合(如“国王 - 男人 + 女人 ≈ 女王”)
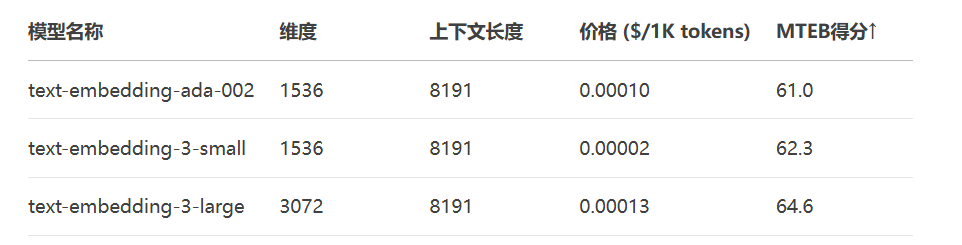
维度可调技术:通过API参数动态降维
from openai import OpenAI client = OpenAI() # 将3072维嵌入压缩至512维 response = client.embeddings.create( model="text-embedding-3-large", input="量子计算的理论基础", dimensions=512 # 自定义输出维度 )
性能-成本平衡:
256维的text-embedding-3-large性能 > 1536维的ada-002
存储成本降低80%,推理速度提升3倍
分词器:cl100k_base(支持多语言)
训练数据:万亿级token混合语料(截止2021年9月)
归一化输出:所有向量自动归一化为单位长度
位置编码:改进的旋转位置编码(RoPE)
层次化训练策略:
基础层:通用语义表示
微调层:针对检索任务优化
多语言增强:
MIRACL基准成绩从31.4%→54.9%
经济性突破:
# 成本对比计算
ada002_cost = 0.0001 * (tokens/1000)
v3small_cost = 0.00002 * (tokens/1000)
print(f"百万token节省: ${(ada002_cost - v3small_cost)*1000:.2f}")
# 输出:百万token节省 $80.00import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from openai.embeddings_utils import get_embedding
# 加载亚马逊食品评论数据集
df = pd.read_csv("fine_food_reviews_1k.csv")
df["combined"] = "标题: " + df.Summary + "; 内容: " + df.Text
# 生成嵌入向量
df["embedding"] = df.combined.apply(
lambda x: get_embedding(x, model="text-embedding-3-small")
)
# 训练分类器
X_train, X_test, y_train, y_test = train_test_split(
list(df.embedding.values), df.Score, test_size=0.2
)
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
# 输出评估报告
print(classification_report(y_test, preds))性能对比:
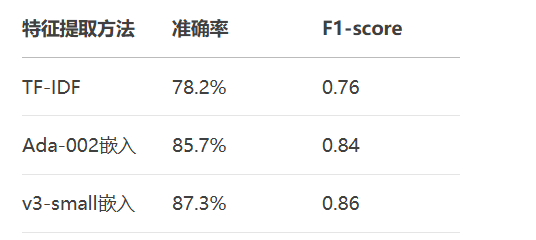
# 心脏病预测数据集特征工程
medical_df["text_desc"] = (
f"年龄:{Age} 性别:{Gender} 胆固醇:{Chol} "
f"最大心率:{Thalach} 胸痛类型:{Cp}"
)
# 生成医学特征嵌入
medical_df["embedding"] = medical_df.text_desc.apply(
lambda x: get_embedding(x, model="text-embedding-3-large")
)
# 融合传统特征与嵌入
X_combined = np.hstack([X_tabular, np.vstack(medical_df.embedding)])效果提升:
随机森林AUC从0.82→0.89
逻辑回归AUC从0.78→0.85
# 基于SNLI数据集优化嵌入矩阵 def optimize_embedding_matrix(train_embeddings: torch.Tensor, labels: torch.Tensor) -> torch.Tensor: W = torch.eye(1536, requires_grad=True) # 初始化单位矩阵 optimizer = torch.optim.Adam([W], lr=0.001) for epoch in range(1000): transformed = train_embeddings @ W cos_sim = F.cosine_similarity(transformed, transformed) loss = F.binary_cross_entropy_with_logits(cos_sim, labels) optimizer.zero_grad() loss.backward() optimizer.step() return W.detach() # 应用优化矩阵 custom_embedding = original_embedding @ W_optimized
优势:在特定领域任务中错误率降低50%
from sklearn.decomposition import PCA # 降维加速检索 pca = PCA(n_components=128) reduced_embeds = pca.fit_transform(all_embeddings) # 分层检索流程 def hybrid_retrieval(query): coarse_results = faiss_index.search(reduced_embeds, k=100) # 粗筛 fine_results = [ (id, cosine_similarity(full_embed[id], query_embed)) for id in coarse_results ] return sorted(fine_results, key=lambda x: x[1], reverse=True)[:10]
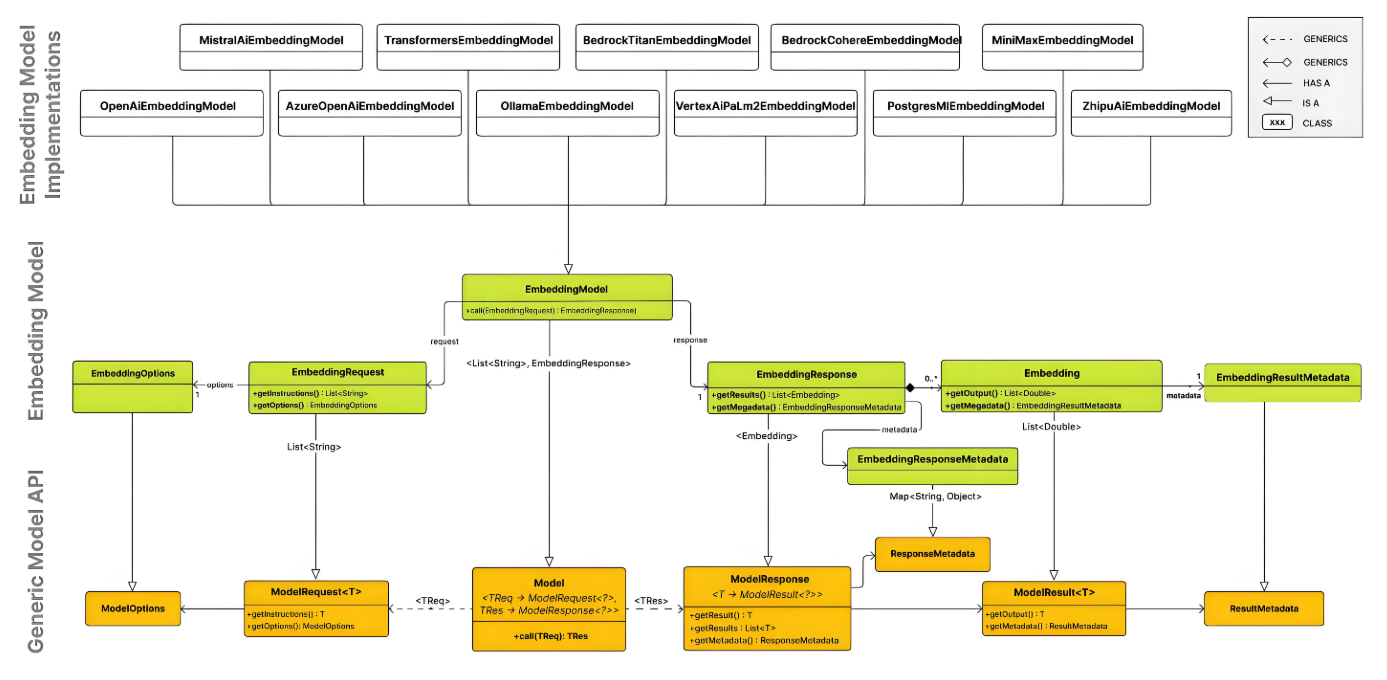
笔者建议:优先采用text-embedding-3-small平衡成本与性能,在检索关键场景使用text-embedding-3-large并启用维度压缩。更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



