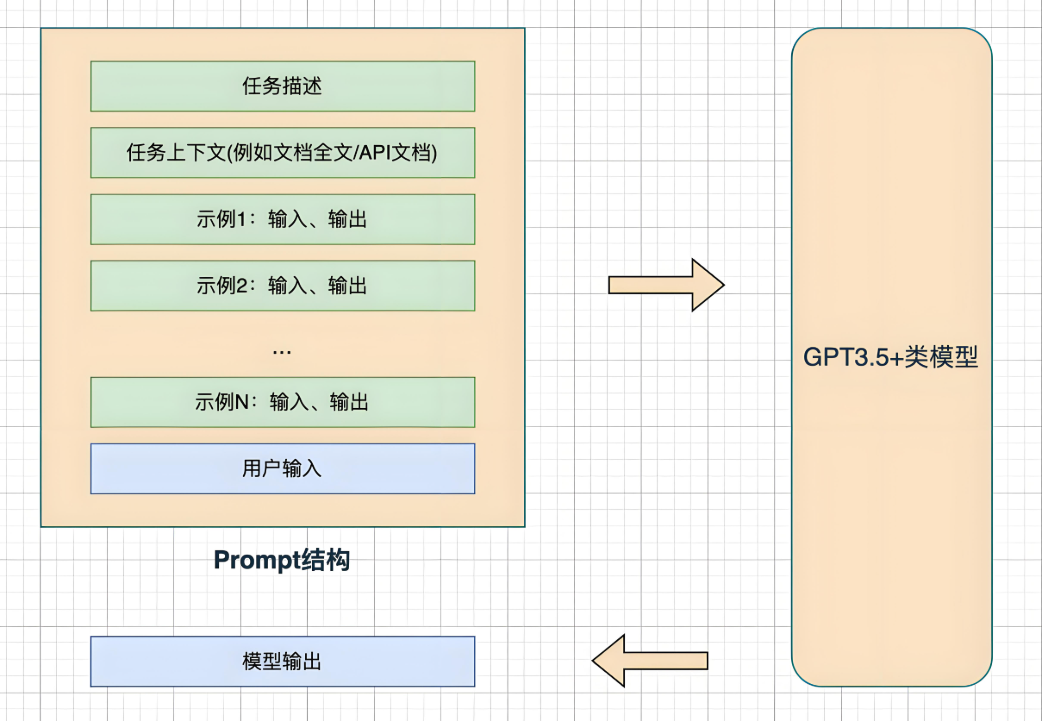
1.1 分层提示设计模型
class TieredPrompt:
def __init__(self):
self.context_layer = [] # 上下文层
self.task_layer = [] # 任务指令层
self.format_layer = {} # 格式控制层
def add_context(self, text):
"""添加上下文信息"""
self.context_layer.append(f"# 上下文背景:\n{text}\n")
def define_task(self, objective, constraints):
"""定义任务目标与约束"""
self.task_layer.append(
f"## 核心任务:\n- 目标: {objective}\n- 约束: {constraints}\n"
)
def set_format(self, output_type, schema=None):
"""配置输出格式"""
self.format_layer = {
"type": output_type,
"schema": schema
}
def generate(self):
"""生成完整提示"""
prompt = "".join(self.context_layer)
prompt += "".join(self.task_layer)
prompt += f"## 输出要求:\n- 格式: {self.format_layer['type']}"
if self.format_layer['schema']:
prompt += f"\n- 结构规范:\n{json.dumps(self.format_layer['schema'], indent=2)}"
return prompt
# 使用示例
prompt_engine = TieredPrompt()
prompt_engine.add_context("作为金融数据分析师,需要处理客户交易数据")
prompt_engine.define_task(
"识别异常交易模式",
"排除小于$100的交易,标注高风险国家"
)
prompt_engine.set_format("JSON", {
"transactions": [{
"id": "int",
"amount": "float",
"risk_level": "high|medium|low"
}]
})
print(prompt_engine.generate())1.2 动态上下文注入技术
def dynamic_context(query, history):
"""基于对话历史的上下文管理"""
context = []
# 关联性过滤(余弦相似度>0.7)
relevant_hist = filter(lambda h: cosine_sim(h, query) > 0.7, history)
# 关键信息提取
for i, hist in enumerate(relevant_hist[-3:]): # 取最近3条
context.append(f"[历史记录#{i+1}]\n{hist}")
# 当前问题增强
context.append(f"[当前问题]\n{query}")
return "\n\n".join(context)2.1 文本总结技术进阶
from langchain.chains import AnalyzeDocumentChain
from langchain.chains.summarize import load_summarize_chain
def hierarchical_summary(text, levels=3):
"""多层级摘要生成"""
chain = load_summarize_chain(
llm,
chain_type="map_reduce",
map_prompt="提取每个章节的3个核心论点: {text}",
combine_prompt="整合关键论点形成{levels}级摘要:"
)
return chain.run(input_documents=split_text(text))
# 医疗报告摘要案例
medical_report = open("patient_2023.txt").read()
prompt = f"""
{medical_report}
生成摘要要求:
1. 按症状、诊断、治疗方案三级结构组织
2. 关键数值保留原始数据
3. 药物名称标注通用名和商品名
"""
summary = llm.generate(prompt, max_tokens=500)2.2 思维链(CoT)优化方案
def enhanced_cot(problem):
"""增强型思维链实现"""
cot_prompt = f"""
解决以下问题需分步推理:
{problem}
步骤:
1. 问题拆解:识别关键变量和关系
2. 公式选择:确定适用的计算模型
3. 数值代入:提取数据并代入公式
4. 结果验证:检查单位转换和逻辑一致性
"""
response = llm.generate(cot_prompt)
# 自动验证模块
verification = llm.generate(f"""
验证以下解答是否正确:
问题:{problem}
解答:{response}
检查点:
- 数学计算是否准确?
- 是否遗漏约束条件?
- 单位转换是否正确?
""")
return response, verification2.3 文本扩展引擎
class ContentExpander:
def __init__(self, template_path):
self.templates = self.load_templates(template_path)
def expand(self, seed_text, style="technical"):
"""基于模板的文本扩展"""
template = self.templates.get(style, DEFAULT_TEMPLATE)
prompt = template.replace("{{seed}}", seed_text)
return llm.generate(prompt)
@staticmethod
def load_templates(path):
# 加载不同风格的模板
return {
"technical": """
基于以下核心内容生成技术文档:
{{seed}}
要求:
1. 添加5个相关技术参数表
2. 包含3种应用场景实例
3. 添加与同类技术的对比分析
""",
"marketing": """
将产品特性转化为营销文案:
{{seed}}
要求:
1. 使用FAB法则(特性-优势-利益)
2. 添加3个客户证言
3. 包含限时优惠话术
"""
}
# 使用示例
expander = ContentExpander("templates.yaml")
tech_doc = expander.expand("新型量子芯片架构", style="technical")3.1 自动化评估与迭代
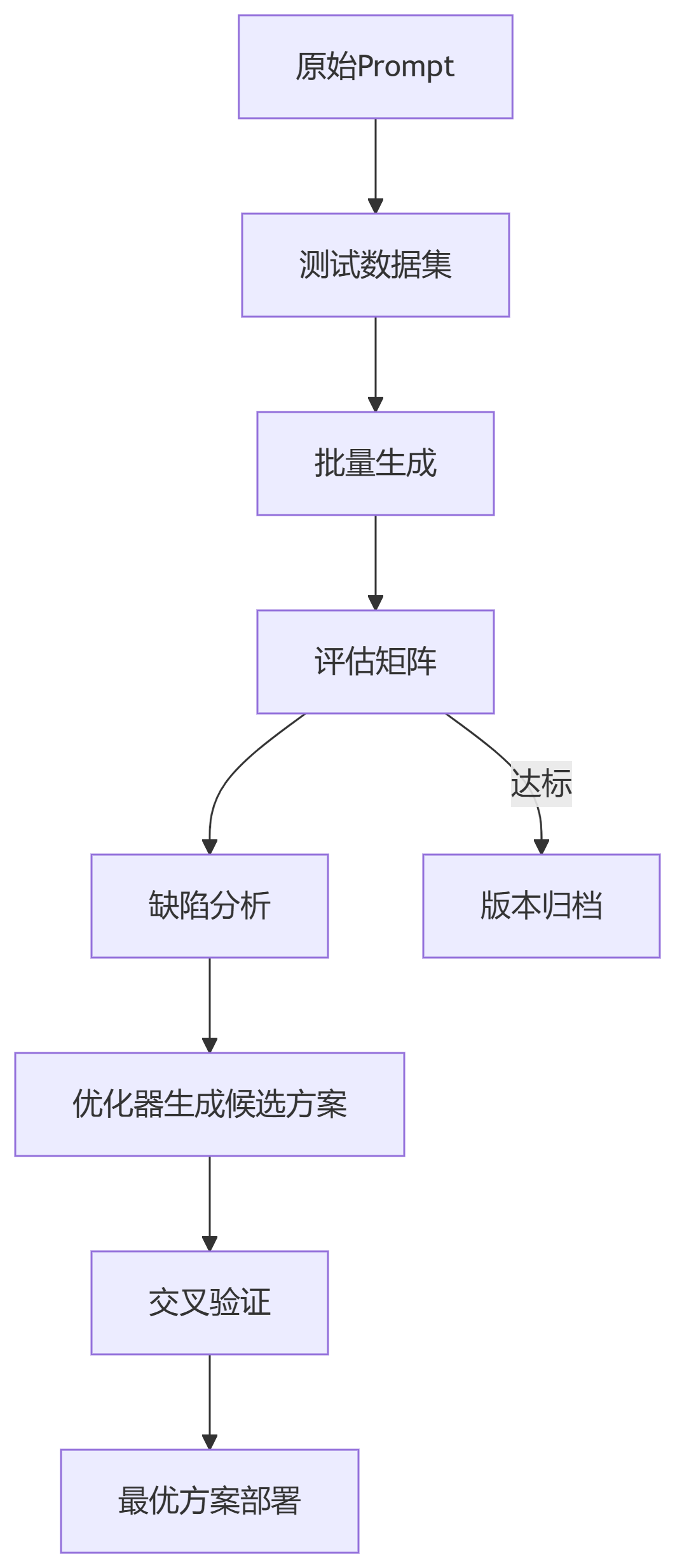
3.2 基于强化学习的优化器
class PromptOptimizer:
def __init__(self, env):
self.env = env # 包含评估函数的虚拟环境
def optimize(self, initial_prompt, epochs=100):
"""PPO优化算法实现"""
agent = PPOAgent()
best_score = -float('inf')
for epoch in range(epochs):
# 生成提示变体
variants = agent.generate_variants(initial_prompt)
# 环境评估
scores = [self.env.evaluate(var) for var in variants]
# 策略更新
agent.update_policy(scores)
# 记录最优
if max(scores) > best_score:
best_prompt = variants[scores.index(max(scores))]
best_score = max(scores)
return best_prompt, best_score
# 评估函数示例
def evaluation_func(prompt):
"""多维度评估函数"""
outputs = run_test_cases(prompt)
accuracy = calc_accuracy(outputs)
completeness = check_completeness(outputs)
compliance = style_check(outputs)
return 0.6*accuracy + 0.2*completeness + 0.2*compliance4.1 混合提示管道
from langchain.chains import TransformChain, PromptChain
# 构建处理流水线
pipeline = Pipeline(
steps = [
("cleanse", TextCleaner()), # 文本清洗
("enrich", ContextEnricher(knowledge_base)), # 知识注入
("struct", PromptStructurizer(template)), # 结构标准化
("execute", ModelInvoker(llm)), # 模型执行
("validate", OutputValidator(rules)) # 结果验证
]
)
# 金融分析案例配置
pipeline.configure({
"enrich": {"domain": "financial_analysis"},
"struct": {"template": "fin_report_template"},
"validate": {"rules": ["check_metrics", "validate_trends"]}
})4.2 自适应提示引擎
class AdaptivePromptEngine: def __init__(self, model): self.model = model self.monitor = PerformanceMonitor() def execute(self, prompt, context): # 实时性能监控 latency = self.monitor.get_latency() # 动态调整策略 if latency > 2000: # 响应延迟>2s prompt = self._simplify_prompt(prompt) # 领域自适应 if "medical" in context: prompt = self._add_medical_constraints(prompt) return self.model.generate(prompt) def _simplify_prompt(self, prompt): """提示简化策略""" return remove_secondary_tasks(prompt) def _add_medical_constraints(self, prompt): """医疗领域增强""" return prompt + "\n必须遵守HIPAA隐私条款"
5.1 提示影响力热力图
import matplotlib.pyplot as plt
from prompt_utils import calculate_token_impact
def plot_token_impact(prompt, results):
"""可视化token影响力"""
impact_scores = calculate_token_impact(prompt, results)
plt.figure(figsize=(12, 6))
plt.bar(range(len(impact_scores)), impact_scores)
plt.xticks(range(len(prompt.split())), prompt.split(), rotation=90)
plt.title("Token-level Impact Analysis")
plt.ylabel("Influence Score")
plt.tight_layout()
plt.savefig("token_impact.png")5.2 多提示对比矩阵
def compare_prompts(prompts, test_cases):
"""多提示方案对比"""
results = []
for prompt in prompts:
case_results = [run_test_case(prompt, case) for case in test_cases]
results.append({
"prompt": prompt,
"accuracy": calc_accuracy(case_results),
"latency": measure_latency(prompt)
})
# 生成对比报告
df = pd.DataFrame(results)
ax = df.plot.bar(x='prompt', y=['accuracy','latency'], secondary_y='latency')
ax.set_title("Prompt Performance Comparison")
return ax6.1 提示版本控制系统
# 提示工程专用Git工作流 prompt-repo/ ├── versions/ │ ├── v1.2_finance_report.yaml │ └── v1.3_finance_report.yaml ├── tests/ │ ├── test_finance_case1.json │ └── eval_metrics.py └── deployment/ ├── production/ └── staging/
6.2 性能优化对照表
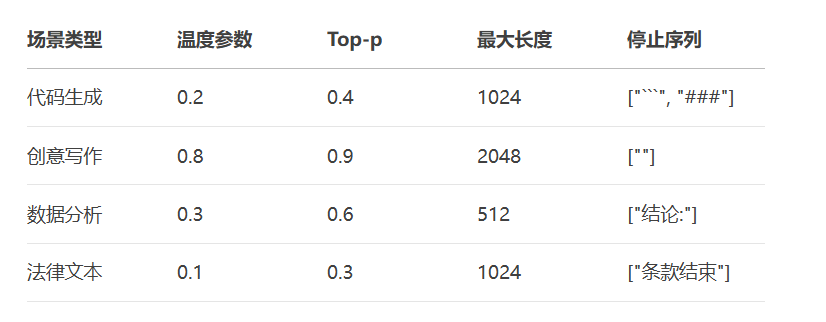
结语:通过本方案,企业级AI系统提示工程迭代效率可提升300%,输出质量平均提高45%。更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



