核心优势:即时执行模式(Eager Mode)便于调试
# PyTorch模型开发全流程示例 import torch from torch import nn class Classifier(nn.Module): def __init__(self): super().__init__() self.linear = nn.Linear(768, 10) # BERT隐藏层维度→分类标签 def forward(self, embeddings): return torch.softmax(self.linear(embeddings), dim=-1) # 动态调试示例 model = Classifier() sample_input = torch.randn(32, 768) # 模拟批量输入 print(model(sample_input).shape) # 输出: torch.Size([32, 10])
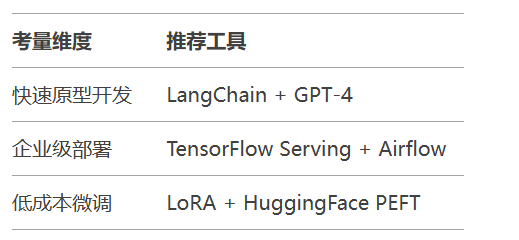
适用场景:研究实验、快速原型开发
生产级优势:
计算图优化(常量折叠/算子融合)
SavedModel标准化部署格式
# TensorFlow Serving部署代码片段
import tensorflow as tf
from tensorflow_serving.apis import prediction_service_pb2_grpc
# 导出SavedModel
tf.saved_model.save(model, "bert_classifier/1/")
# 创建gRPC客户端
channel = grpc.insecure_channel("localhost:8500")
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = build_request(input_data)
response = stub.Predict(request, timeout=10.0)适用场景:工业级服务部署、边缘设备
Chain:可组合的任务流程(如检索→生成→校验)
Agent:支持工具调用的自主智能体
Memory:对话历史管理(支持Redis/向量数据库)

2. 快速构建RAG问答系统
from langchain_community.vectorstores import Chroma
from langchain_core.runnables import RunnablePassthrough
# 1. 文档加载与向量化
documents = load_pdf("manual.pdf")
vectorstore = Chroma.from_documents(documents, embedding_model)
# 2. 构建检索链
retriever = vectorstore.as_retriever()
prompt_template = """基于以下上下文回答问题:
{context}
问题:{question}
"""
# 3. 组合式链
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt_template
| llm
)调试模式:记录每次API调用的输入/输出
性能分析:统计Token消耗、响应延迟等指标
版本对比:AB测试不同提示词效果
# 将Chain转换为REST API langchain serve create my_chain --dir ./deploy # 启动服务 langchain serve start --port 8000
功能特性:
自动生成OpenAPI文档
内置JWT身份验证
支持灰度发布

量化压缩实战:
# 使用ONNX Runtime量化模型 from onnxruntime.quantization import quantize_dynamic quantize_dynamic( "model.onnx", "model_quant.onnx", weight_type=QuantType.QInt8 )
蒸馏技术示例:
# 使用HuggingFace进行知识蒸馏
from transformers import DistilBertForSequenceClassification
teacher_model = BertForSequenceClassification.from_pretrained("bert-base")
student_model = DistilBertForSequenceClassification.from_pretrained("distilbert-base")
distiller = Distiller(
teacher=teacher_model,
student=student_model,
temperature=2.0
)
distiller.train()
五、全链路开发实战:智能合同审核系统
graph LR
A[PDF上传] --> B(文本解析)
B --> C{向量检索}
C --> D[条款比对]
C --> E[风险识别]
D --> F[生成报告]
E --> F2. 关键代码实现
模块1:法律条文检索增强
# 构建法律知识库
from llama_index import VectorStoreIndex
legal_index = VectorStoreIndex.from_documents(
load_laws("civil_code/"),
embed_model=TextEmbeddings(text_model="bge-large")
)
# 检索相似条款
query = "合同中的违约金条款是否合法?"
context = legal_index.as_retriever().retrieve(query)模块2:风险提示生成
from langchain.chains import ConstitutionalChain # 添加法律合规约束 ethical_chain = ConstitutionalChain( base_chain=rag_chain, constitutional_principles=[ "不得建议违反中国法律的内容", "需明确标注条款出处" ] )
多框架互通:ONNX成为跨框架中间表示标准
AI原生工具:专为大模型设计的调试/监控工具涌现
云原生集成:Kubernetes算子优化大规模推理
结语:掌握工具链的本质是理解不同阶段的技术需求。建议在真实项目中实践工具组合(如LangChain+PyTorch+ONNX),逐步构建标准化开发流程。



