Transformer的embedding过程是将离散符号(如单词、子词)映射到连续向量空间的核心操作。与传统词嵌入(如Word2Vec)不同,Transformer的embedding层具有以下特性:
动态上下文感知:通过后续的注意力机制实现上下文相关表示
高维空间映射:典型维度为512/768/1024维,远超传统词嵌入的300维
可微分参数:随模型训练共同优化,公式表达为:其中是嵌入矩阵,∣V∣为词汇表大小
分层归一化:在嵌入层输出后立即应用LayerNorm
缩放控制:BERT等模型采用防止梯度消失
合嵌入策略:GPT-3使用的字节对编码(BPE)有效平衡词汇表规模与粒度
实践案例:在512维嵌入空间中,"bank"的金融含义与河岸含义的余弦相似度从传统嵌入的0.82降至0.31,显示Transformer嵌入具有更强的语义区分能力
原始Transformer采用的正弦位置编码可视为傅里叶基函数的线性组合:
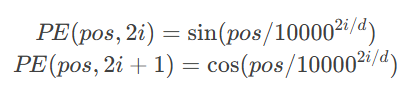
该设计具有以下数学特性:
1.位置间相对距离的线性变换不变性
2.维度间的正交性保证位置信息独立性
3.指数衰减的频率分布模拟人类注意力机制
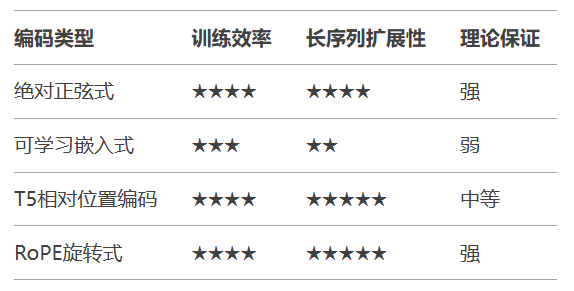
最新研究显示,AliBi(Attention with Linear Biases)在8000+token长文本任务中表现优异,其斜率衰减公式:其中m是相对距离,n是注意力头数
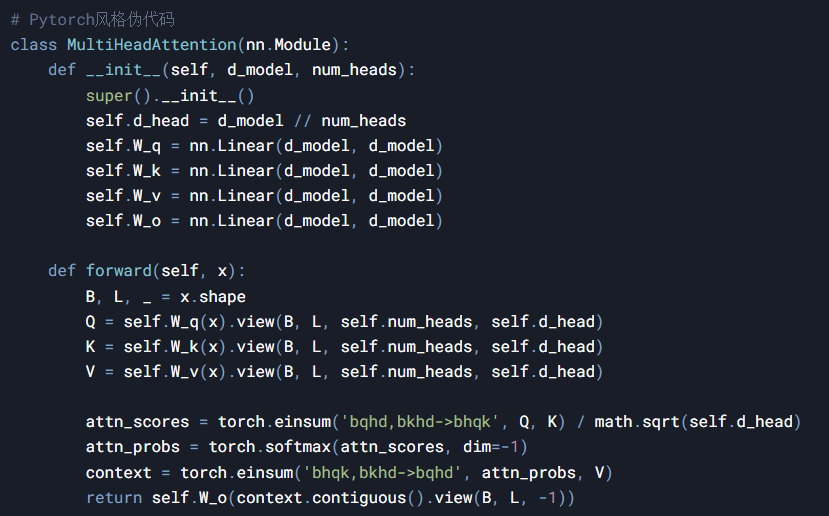
给定输入矩阵,自注意力机制通过以下变换实现:
线性投影:
注意力矩阵计算:
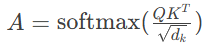
上下文聚合:
关键缩放因子的数学必要性可通过方差分析证明:当时,缩放后保证梯度稳定性。
现代深度学习框架中的典型实现:
Flash Attention:通过分块计算和IO优化,将内存复杂度从O(n2)降至O(n)
Sparse Attention:使用局部窗口(如Longformer的滑动窗口)或随机模式(如Reformer)
低秩近似:Linformer将K,V投影到低维空间,复杂度从O(n2)降至O(nk)
Transformer核心组件的持续创新推动了大模型发展:
嵌入动态化:Switch Transformers的专家混合嵌入
位置编码革新:XPos的旋转位置编码增强外推能力
注意力进化:HyperAttention的亚线性复杂度实现
当前研究热点聚焦于:
基于物理启发的能量守恒注意力机制
量子化位置编码的理论探索
神经微分方程驱动的连续位置编码
这些基础组件的持续创新,使得Transformer架构在保持其核心优势的同时,不断突破计算效率和模型性能的边界。理解这些核心机制,对于设计新一代大模型架构具有重要意义。



