核心作用:解决传统情感分析中“上下文缺失”和“动态场景适应”难题
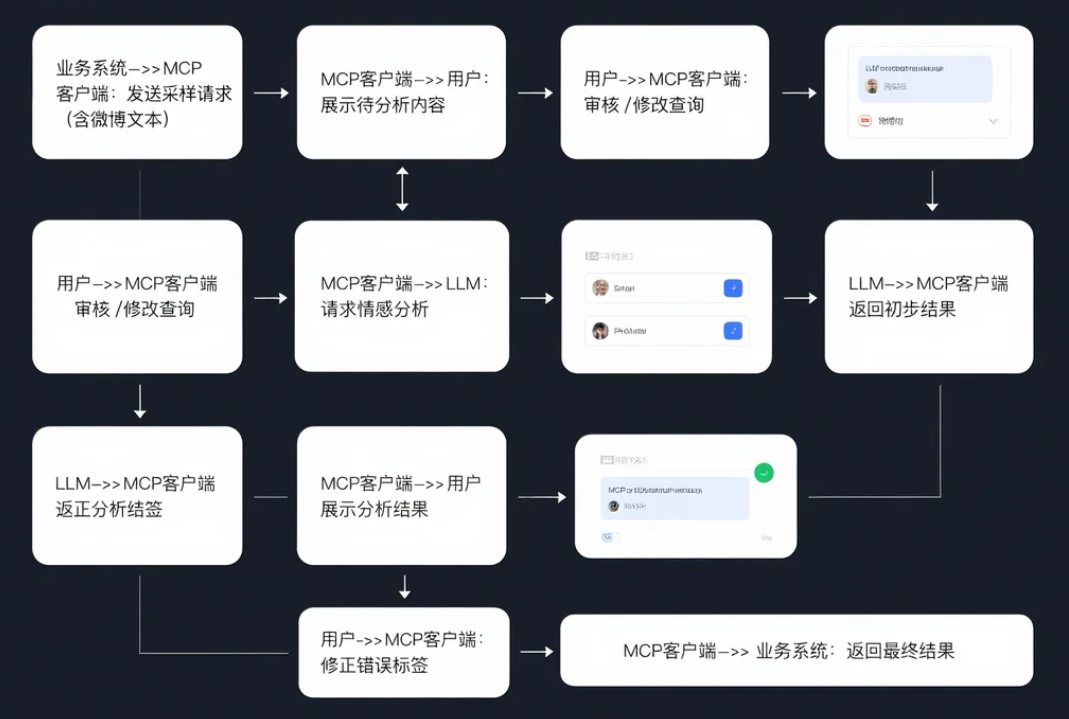
关键优势:
人工审核机制:拦截敏感内容(如政治言论)
动态上下文注入:自动关联历史舆情数据
{
"method": "sampling/createMessage",
"params": {
"messages": [{
"role": "user",
"content": {
"type": "text",
"text": "分析微博情感:'新疆棉事件中品牌声明太让人失望了!'"
}
}],
"systemPrompt": "你是一名舆情分析师,请判断情感倾向(正面/负面/中立)并标注依据",
"maxTokens": 150,
"temperature": 0.3 // 低随机性保证稳定性
}
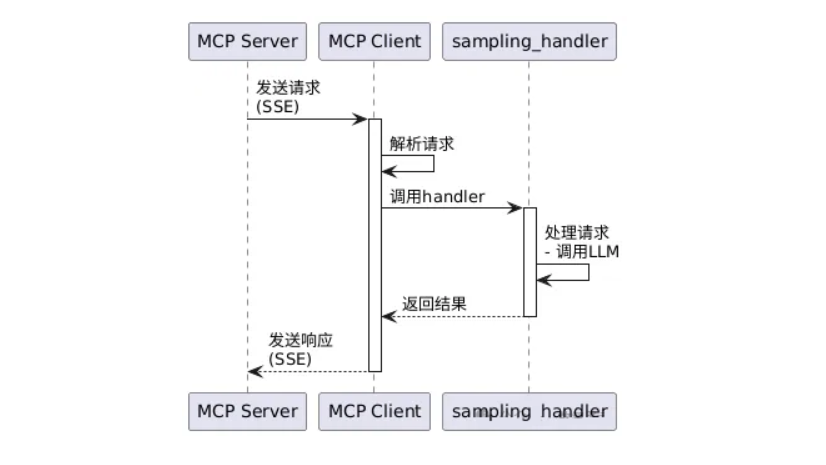
}def safe_sampling(request):
# 1. 敏感词过滤
if contains_sensitive_word(request["text"]):
return {"error": "内容包含敏感词"}
# 2. 权限校验 (2025-06-18协议要求:cite[6])
if not user_has_permission(request["user_id"], "sentiment_analysis"):
return {"error": "权限不足"}
# 3. 成本控制
if estimate_token(request) > MAX_TOKEN:
return {"error": "超出token限额"}
# 转发至LLM处理
return call_llm_api(request)上下文压缩:仅加载相关历史数据
"includeContext": "thisServer" // 避免全量上下文拖慢速度
模型选择策略
"modelPreferences": {
"costPriority": 0.8,
"speedPriority": 0.9,
"intelligencePriority": 0.7
}结果缓存机制:对热门话题分析结果缓存24小时
import jieba from sklearn.feature_extraction.text import TfidfVectorizer # 微博特有清洗规则 def clean_weibo_text(text): text = re.sub(r"#\S+#", "", text) # 移除话题标签 text = re.sub(r"@\S+", "", text) # 移除@用户 return text # 结合情感词典的分词 emotion_dict = load_emotion_dict() # 加载"好/烂/赞/呸"等情感词 jieba.load_userdict(emotion_dict)
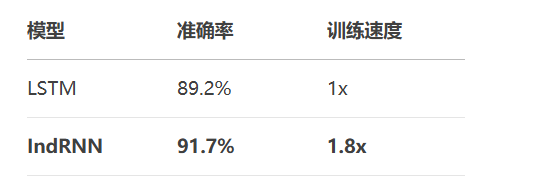
from tensorflow.keras.models import Sequential from ind_rnn import IndRNNCell # 独立循环神经网络 model = Sequential([ Embedding(input_dim=5000, output_dim=128), RNN(IndRNNCell(128), return_sequences=True), GlobalMaxPooling1D(), Dense(64, activation='relu'), Dense(3, activation='softmax') # 负面/中立/正面 ])
性能对比:
def analyze_sentiment(text):
# 构造MCP请求
request = {
"method": "sampling/createMessage",
"params": {
"messages": [{"role": "user", "content": text}],
"systemPrompt": "情感分析专家,输出JSON格式: {sentiment: -1~1, reason: str}"
}
}
# 发送至本地MCP服务器
response = requests.post("http://localhost:8000/mcp", json=request)
return parse_response(response)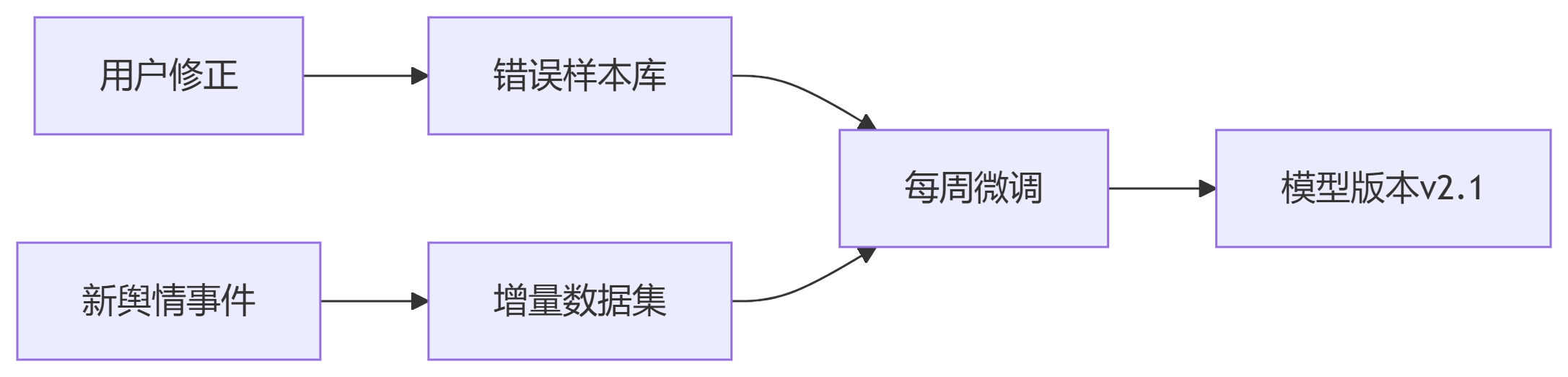
python finetune.py \ --model WeiboEmotionClassifier \ --lora_r 8 \ --lora_alpha 16 \ --target_modules "query,value" \ --dataset new_comments.json
资源对比:

安全增强
POST /v1/complete HTTP/1.1 Resource: https://api.your-company.com # 资源指示器防令牌滥用 MCP-Protocol-Version: 2025-06-18
结构化输出:直接生成可解析JSON
{
"tool": "sentiment_analysis",
"output": {
"sentiment_score": -0.82,
"key_phrases": ["品牌声明", "失望"]
}
}Elicitation交互:
# 当信息不足时主动询问
if "brand" not in request:
return {"elicitation": {"prompt": "请指定要分析的品牌名称"}}移除批处理:用异步请求替代旧批处理代码
生命周期强制:必须实现 terminate 事件上报
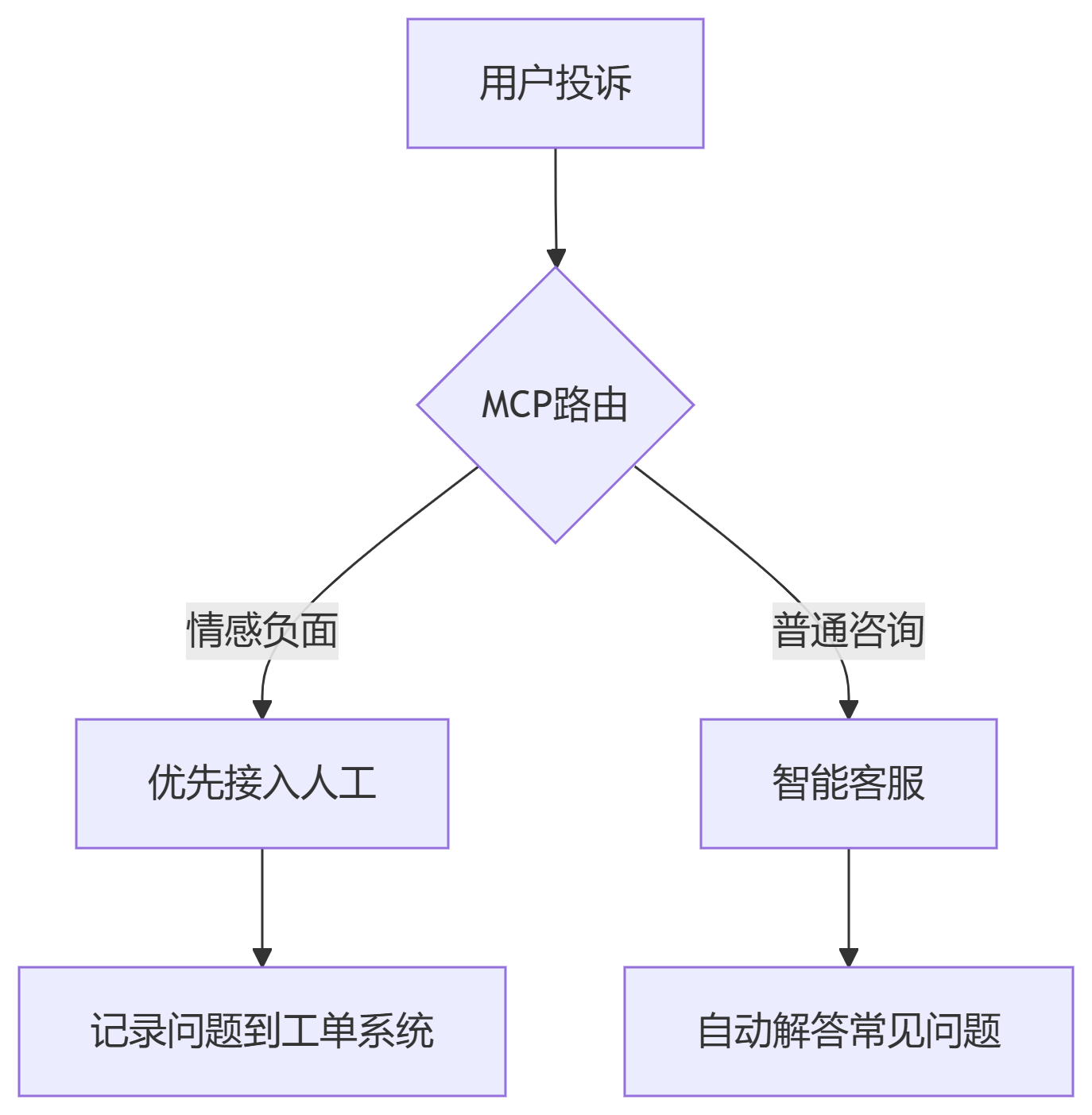
成效:
负面情绪客户响应速度提升3倍
人工客服工作量减少40%
工具封装:将业务API包装为MCP Tool
@mcp.tool(name="query_order")
def get_order_info(order_id: str):
return db.query("SELECT * FROM orders WHERE id=?", order_id)权限隔离:
# mcp_permissions.yaml - tool: query_order roles: [customer_service, supervisor] - tool: refund_order roles: [supervisor]
渐进式接入:从内部问答系统开始试点
监控看板:实时追踪情感分析准确率

MCP技术文档:https://wcnolv4zdyoz.feishu.cn/wiki/RBrLwVdogiT14FkE8YscoWyKnWf?from=from_copylink
结语:真正的AI红利属于能解决实际问题的人——当你用三行MCP调用替代了某业务2000行传统代码时,你就是无可替代的下一代开发者!更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



