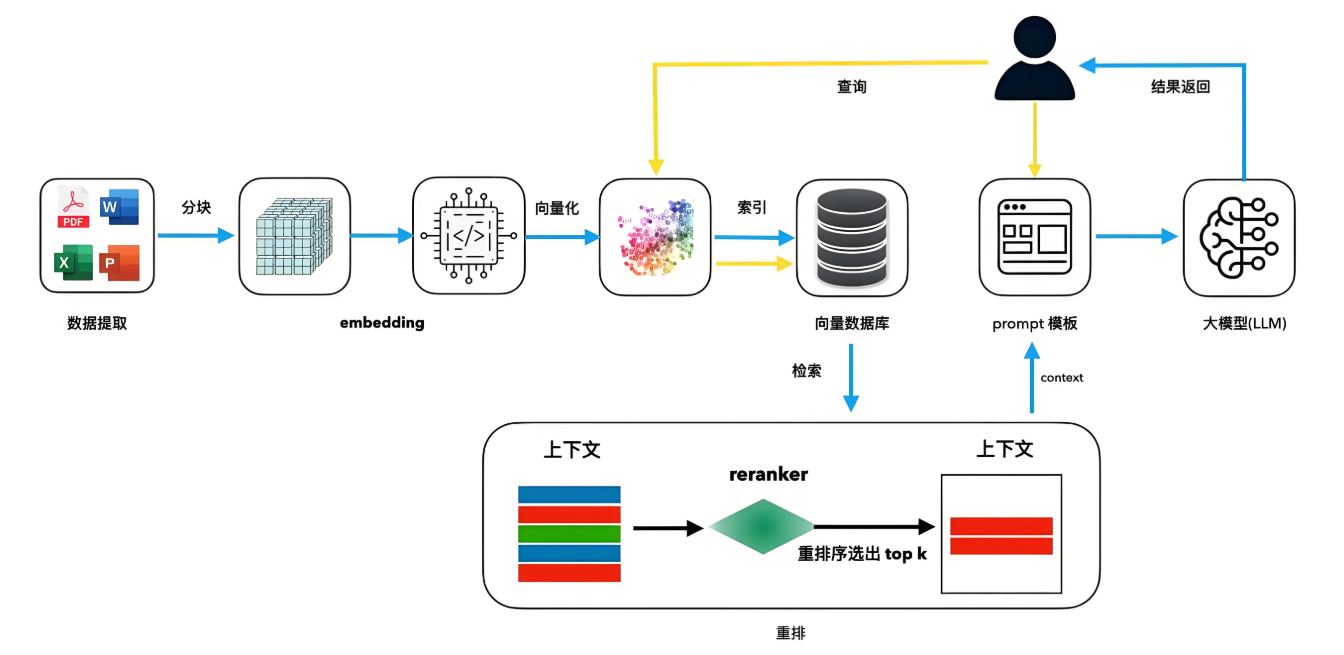
核心组件作用:
文本分块:平衡信息完整性与检索效率(建议长度512-1024 token)
向量嵌入:将文本映射为高维空间中的数学表示(如1536维向量)
混合检索:结合语义向量与关键词BM25,召回率提升30%
import numpy as np # 示例:词向量关系推理 king = np.array([1.2, 0.8, -0.5]) queen = np.array([1.0, 0.9, -0.6]) man = np.array([0.9, 0.7, -0.3]) woman = king - man + queen # 结果 ≈ [1.1, 0.8, -0.4]
关键特性:
余弦相似度:cosθ = A·B / (||A||·||B||),衡量语义相关性(-1到1)
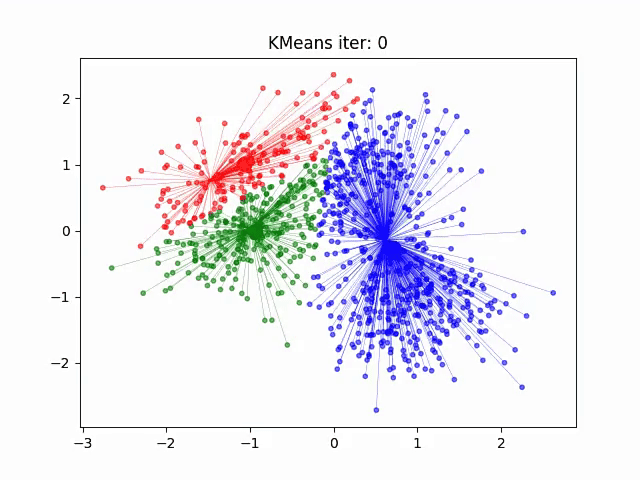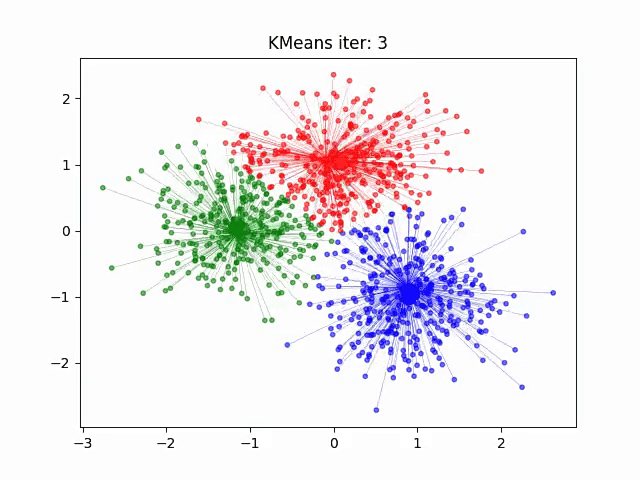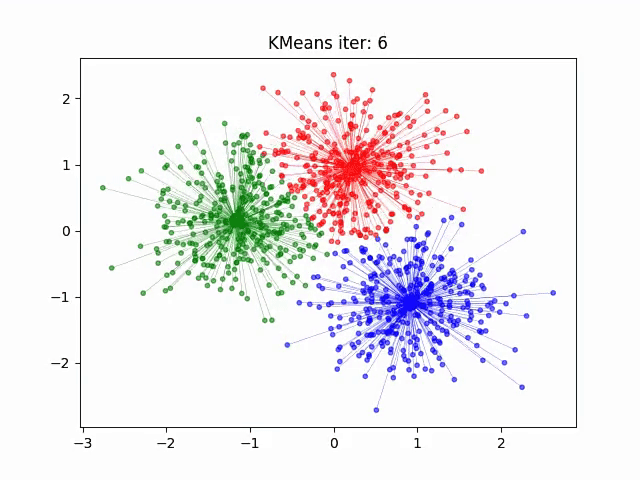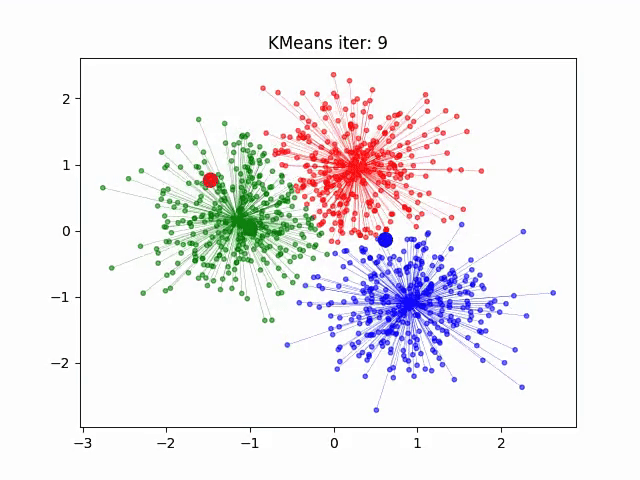
聚类特性:相似主题文档在向量空间中聚集(如图)
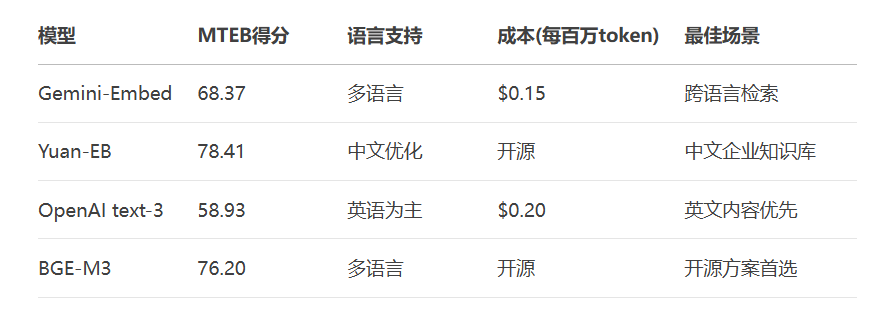
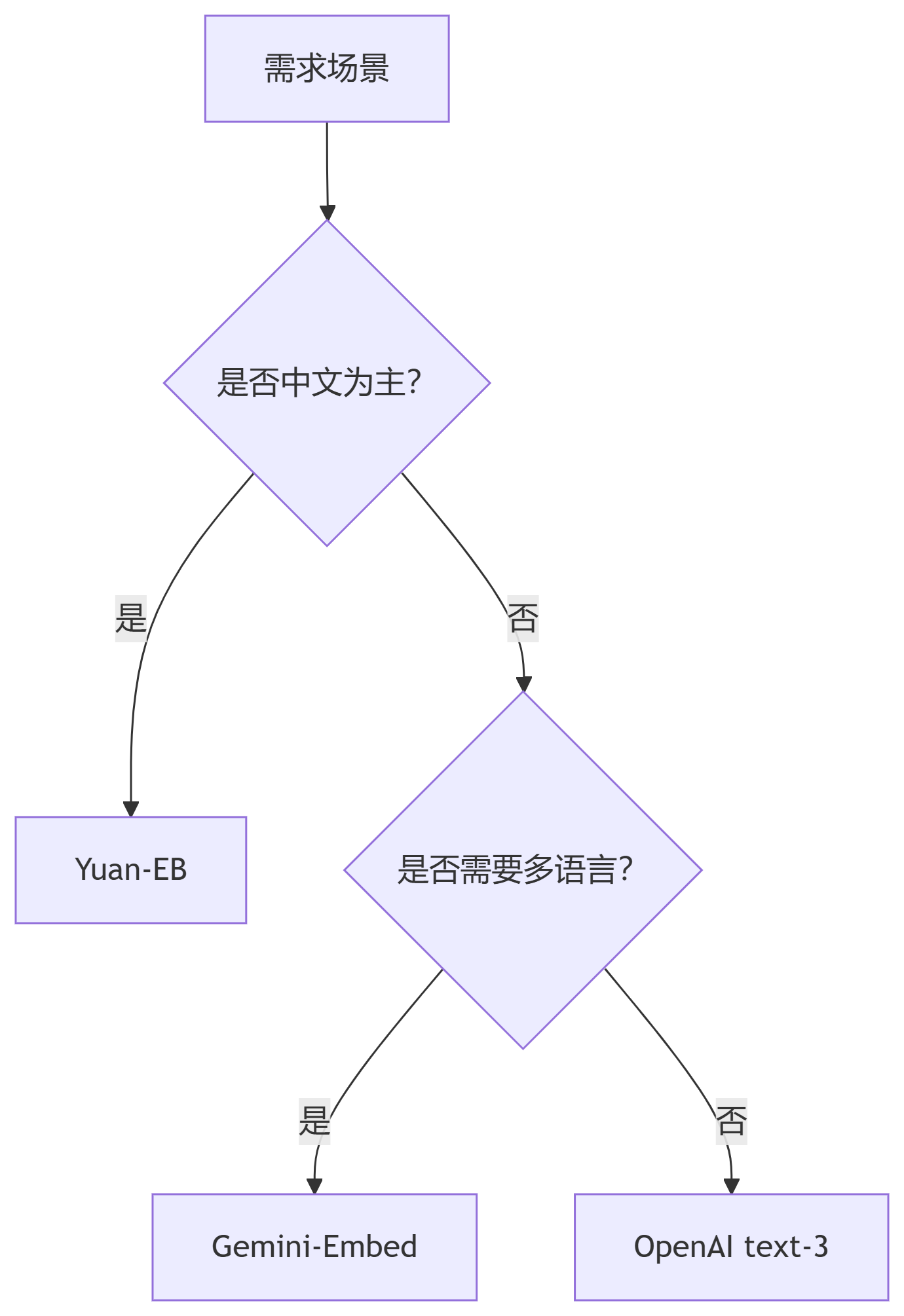
选型决策树:
from transformers import AutoTokenizer, AutoModel
import torch
# 1. 文本分词
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
inputs = tokenizer("Quantum computing principles", return_tensors="pt")
# 2. 模型前向传播
model = AutoModel.from_pretrained("bert-base-uncased")
with torch.no_grad():
outputs = model(**inputs)
# 3. 向量池化(均值策略)
embeddings = torch.mean(outputs.last_hidden_state, dim=1).squeeze()
print(embeddings.shape) # 输出:torch.Size([768])问题:原始余弦相似度在长尾分布中表现不稳定
解决方案:
# 添加平滑系数与归一化 def enhanced_cosine_sim(vec1, vec2, epsilon=1e-6): norm1 = vec1 / (np.linalg.norm(vec1) + epsilon) norm2 = vec2 / (np.linalg.norm(vec2) + epsilon) return np.dot(norm1, norm2)
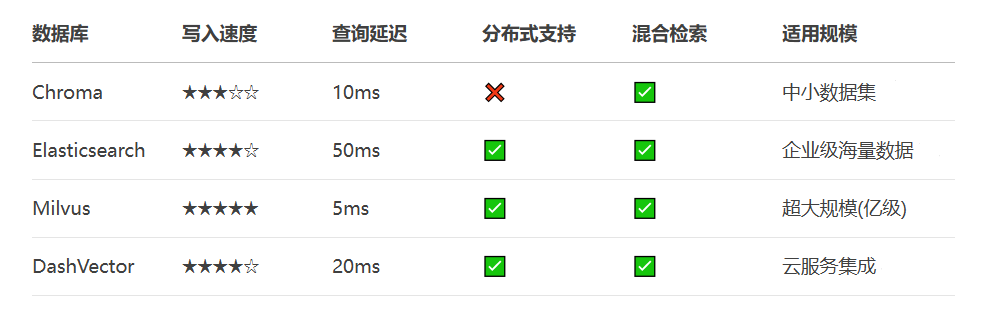
选型建议:
初创项目 → Chroma(轻量级本地部署)
企业生产 → Milvus(分布式+高吞吐)
云原生方案 → DashVector(免运维)
# 启动带持久化的Chroma服务 docker run -d \ --name chromadb \ -p 8000:8000 \ -v /data/chroma:/data \ chromadb/chroma:latest \ chroma run --path /data
import chromadb
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
# 1. 连接服务端
client = chromadb.HttpClient(host="localhost", port=8000)
# 2. 创建集合(使用OpenAI嵌入)
embed_fn = OpenAIEmbeddingFunction(api_key="sk-...", model_name="text-embedding-3-small")
collection = client.get_or_create_collection("tech_docs", embedding_function=embed_fn)
# 3. 批量写入文档
documents = [
"量子计算利用量子比特实现并行运算",
"Transformer架构通过自注意力机制提升序列建模能力"
]
metadatas = [{"category": "quantum"}, {"category": "nlp"}]
ids = ["doc1", "doc2"]
collection.add(documents=documents, metadatas=metadatas, ids=ids)
# 4. 混合查询(语义+元数据过滤)
results = collection.query(
query_texts=["神经网络的最新进展"],
n_results=2,
where={"category": "nlp"}, # 元数据过滤
where_document={"$contains": "架构"} # 文本内容过滤
)
print(results["documents"][0])分层索引:对高频数据启用内存缓存
collection = client.get_collection("hot_data", embedding_function=embed_fn, caching=True)量化压缩:减少75%存储空间
collection.configure(quantization="fp16") # 半精度浮点
多模态支持:集成CLIP模型处理图像
from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunction clip_fn = OpenCLIPEmbeddingFunction()
预处理阶段:
动态分块:Late-Chunking技术解决代词指代问题
元数据增强:添加文档来源/更新时间/置信度标签
检索阶段:
# 重排序提升Top1命中率
from sentence_transformers import CrossEncoder
reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
reranked = reranker.rank(query, candidates)生成阶段:
提示工程注入检索置信度:
请基于以下内容(可信度{score})回答问题:{context}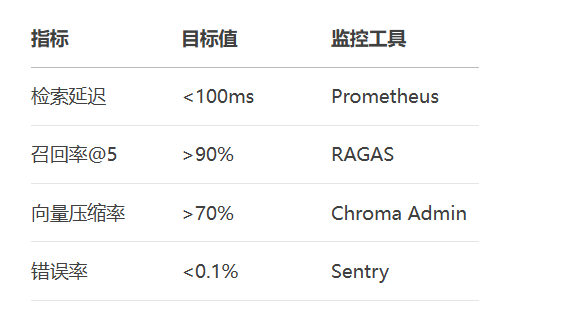
注:所有代码测试环境 Python 3.10 + Chroma 0.5.0,需配置OPENAI_API_KEY
如果本次分享对你有所帮助,记得告诉身边有需要的朋友,"我们正在经历的不仅是技术迭代,而是认知革命。当人类智慧与机器智能形成共生关系,文明的火种将在新的维度延续。"在这场波澜壮阔的文明跃迁中,主动拥抱AI时代,就是掌握打开新纪元之门的密钥,让每个人都能在智能化的星辰大海中,找到属于自己的航向。



