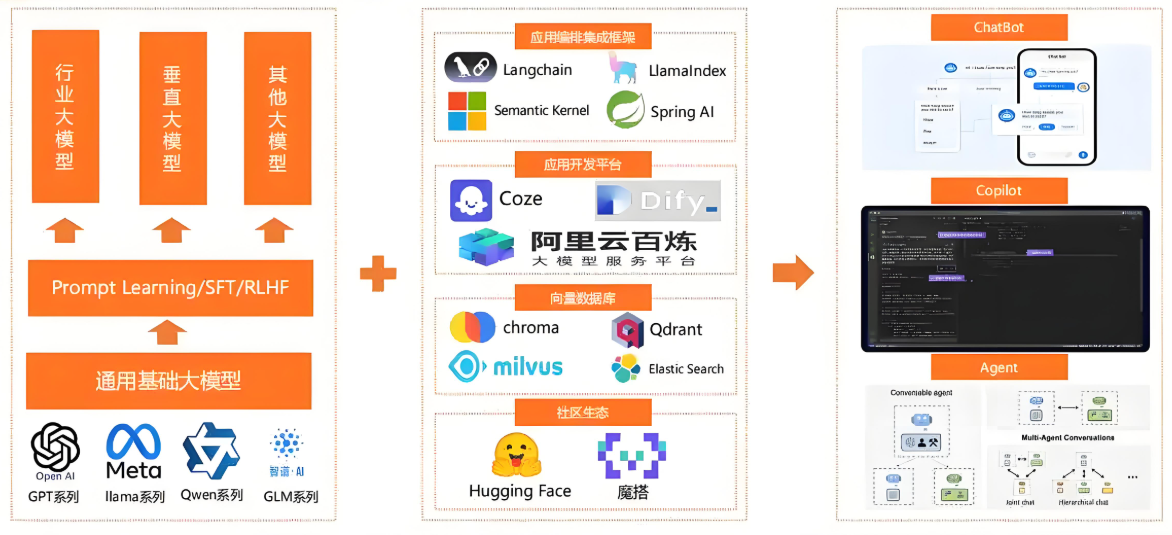
技术突破:
多模态融合:GPT-4o、Gemini 1.5 已实现文本/图像/音频联合推理
上下文扩展:Claude 3支持200K上下文,DeepSeek-R1达128K
推理效率:FlashAttention-3使训练速度提升2.1倍
现存挑战:
幻觉问题:垂直领域错误率仍高达12-15%
长程依赖:超长文档中关键信息召回率不足60%
硬件门槛:千亿模型训练需千卡集群,推理需80GB显存
graph LR A[通用基座] --领域语料注入--> B[领域专家] --人类偏好对齐--> C[行业助手]
模块化推理(MOTIF):马里兰大学提出多轮强化学习框架,通过分层思考突破上下文限制,在数学推理任务上准确率提升3.8%
无向量RAG:OpenAI创新性抛弃向量数据库,采用分层导航策略模拟人类阅读,实现法律文档精准溯源
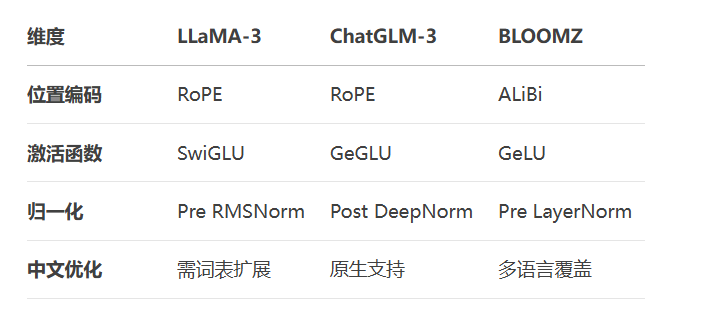
典型场景选型:
金融合规:ChatGLM-3(中文语义理解强)
科研文献:LLaMA-3 + 词表扩展(英文知识密度高)
多语种客服:BLOOMZ(覆盖46种语言)
# Chinese-LLaMA词表扩展示例
from transformers import LlamaTokenizer
new_tokens = ["量化交易", "监管沙盒"] # 添加领域术语
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-3-8B")
tokenizer.add_tokens(new_tokens) # 扩展词表
# 冻结原模型参数,仅训练新token嵌入
for param in model.parameters():
param.requires_grad = False
model.resize_token_embeddings(len(tokenizer))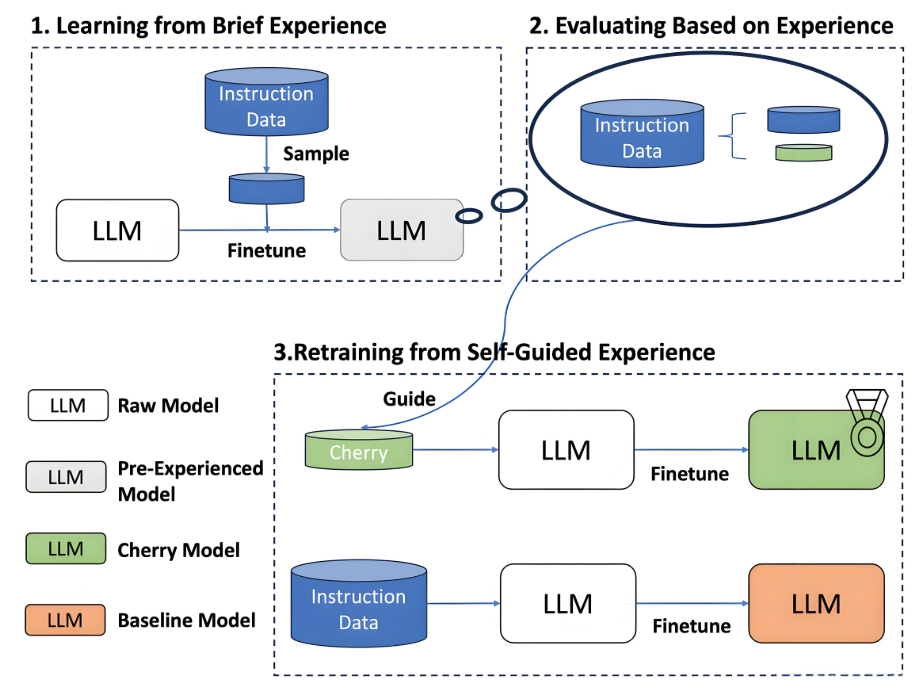
数据构造:指令格式为 {"instruction": "...", "output": "..."}
灾难性遗忘对策:采用LoRA微调,仅更新0.1%参数
偏好数据集:同一问题配对的优质/劣质回答
损失函数设计:
loss = -torch.log(torch.sigmoid(reward_good - reward_bad))
PPO训练四模型协作:
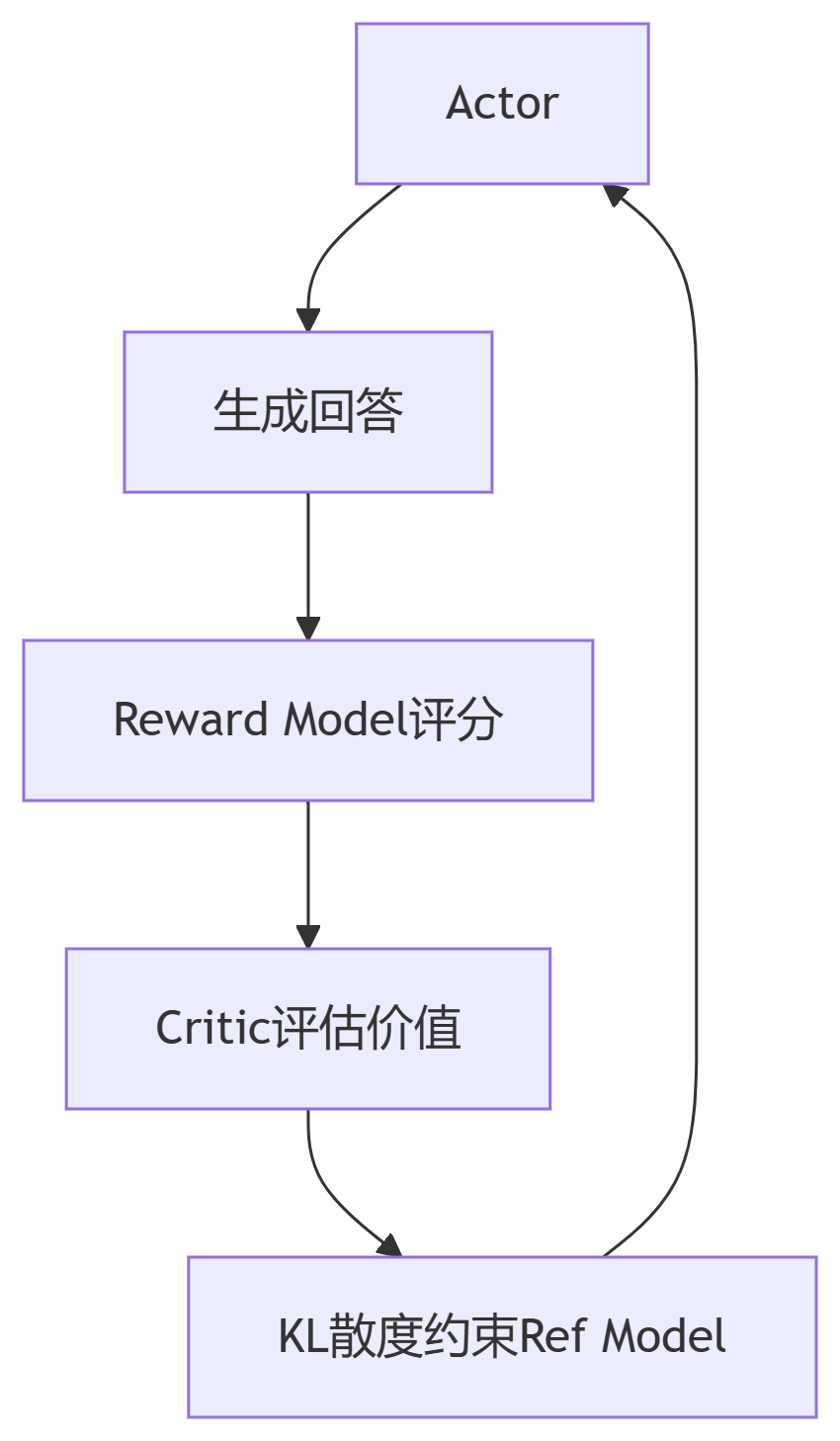
稳定训练技巧:
动态KL系数:初始值0.01,随训练线性增加
Reward归一化:批次内奖励缩放到[-1,1]
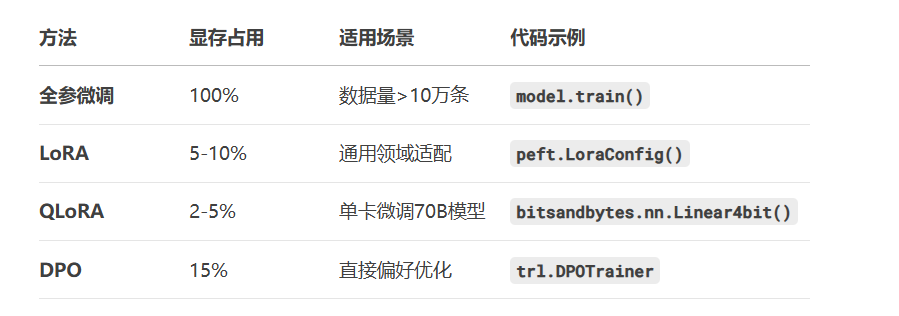
from trl import DPOTrainer dpo_trainer = DPOTrainer( model, args=training_args, train_dataset=dataset, beta=0.1 # 控制偏离强度 ) dpo_trainer.train()
优势:避免RLHF复杂流程,训练速度提升3倍

量化部署:4-bit量化使13B模型可在RTX 4090运行
蒸馏加速:DeepSeek R1 70B→7B蒸馏版精度损失<3%
向量检索在跨段落推理时召回率骤降
文档更新需重建索引,延迟高达数小时
分层导航技术:
def hierarchical_navigation(document, query, layers=3): chunks = split_document(document, 20) # 首层切分20块 for _ in range(layers): selected = llm_select_chunks(chunks, query) chunks = refine_chunks(selected) # 逐层细化 return selected
核心创新:
思考板机制:保存中间决策过程,提升可解释性
强制引用校验:输出必须绑定"0.0.5.0"类源码标识
四库协同架构:
Redis:高频查询缓存(响应<10ms)
Milvus:向量语义检索
ElasticSearch:关键词+向量混合检索
MySQL:事务性数据存储
检索增强:
results = graph.query("MATCH (d:Disease)-[r:TREATS]->(s:Symptom) RETURN d.name")
prompt = f"已知知识:{results}\n问题:{query}"联合训练:将图结构数据注入预训练
推理引擎:Neo4j + LLM实现多跳推理
# 药物相互作用审查
def drug_interaction_check(drug_a, drug_b):
# 知识图谱查询
cyp_pathway = graph.query(f"MATCH path=(a)-[r:METABOLIZED_BY]->(b) RETURN path")
# LLM推理
return llm.generate(f"基于路径{cyp_pathway},分析{drug_a}+{drug_b}风险")作者总结:2025年大模型竞争焦点已从参数量转向推理效率与领域穿透力。记住:没有万能模型,只有与场景共振的系统设计。更多AI大模应用开发学习视频内容和资料,尽在聚客AI学院。



