技术栈配置方案:
# 核心依赖安装 pip install openai==1.3.0 pip install langchain==0.1.0 pip install pydantic==2.5.0 pip install tiktoken==0.5.0 # Token计算工具
工程化项目结构:
project/ ├── prompts/ │ ├── system/ # 系统级提示词模板 │ ├── domain/ # 领域专用提示词 │ └── utils.py # 提示词工具函数 ├── agents/ # 智能体模块 ├── tools/ # 外部工具集成 └── config.py # API密钥管理
密钥安全方案:
# config.py from pydantic import BaseSettings class Settings(BaseSettings): OPENAI_API_KEY: str = "sk-***" SERPAPI_KEY: str = "***" settings = Settings(_env_file=".env")
最小可用示例:
from openai import OpenAI
client = OpenAI(api_key=settings.OPENAI_API_KEY)
def basic_prompt(prompt: str) -> str:
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=500
)
return response.choices[0].message.content
# 调用示例
print(basic_prompt("用Python实现快速排序算法"))响应结构化处理:
from pydantic import BaseModel
class CodeResponse(BaseModel):
code: str
explanation: str
time_complexity: str
def structured_prompt() -> CodeResponse:
prompt = """
生成Python快速排序代码,要求:
1. 包含详细注释
2. 说明时间复杂度
3. 给出测试用例
返回JSON格式:
{"code": "...", "explanation": "...", "time_complexity": "..."}
"""
response = basic_prompt(prompt)
return CodeResponse.model_validate_json(response)模板引擎实现:
from string import Template
class PromptEngine:
def __init__(self):
self.templates = {
"code_review": Template("""
作为${language}资深工程师,审查以下代码:
${code}
要求:
1. 找出至少${min_issues}个潜在问题
2. 按严重性分级(Critical/Major/Minor)
3. 给出优化方案
输出格式:Markdown表格
""")
}
def generate(self, name: str, **kwargs) -> str:
return self.templates[name].substitute(**kwargs)
# 使用示例
engine = PromptEngine()
prompt = engine.generate("code_review",
language="Python",
code="def func(): pass",
min_issues=3)多步骤对话管理:
class ConversationManager:
def __init__(self, max_history=5):
self.history = []
self.max_history = max_history
def add_message(self, role: str, content: str):
self.history.append({"role": role, "content": content})
if len(self.history) > self.max_history:
self.history = self.history[-self.max_history:]
def get_messages(self):
return self.history.copy()
# 使用示例
manager = ConversationManager()
manager.add_message("system", "你是有10年经验的Django开发专家")
manager.add_message("user", "如何优化数据库查询性能?")
response = client.chat.completions.create(
model="gpt-4",
messages=manager.get_messages()
)特征分析流水线:
import tiktoken
class InputAnalyzer:
def __init__(self):
self.encoder = tiktoken.encoding_for_model("gpt-4")
def analyze(self, text: str) -> dict:
return {
"length": len(text),
"tokens": len(self.encoder.encode(text)),
"keywords": self._extract_keywords(text),
"intent": self._classify_intent(text)
}
def _extract_keywords(self, text: str) -> list:
# 使用TF-IDF提取关键词
pass
def _classify_intent(self, text: str) -> str:
# 意图分类模型预测
pass
# 使用示例
analyzer = InputAnalyzer()
print(analyzer.analyze("如何用PyTorch实现Transformer?"))参数自适应策略:
def dynamic_prompt(text: str) -> dict:
analysis = analyzer.analyze(text)
config = {
"temperature": 0.3,
"max_tokens": 500
}
if analysis['intent'] == 'code_generation':
config.update({
"temperature": 0.2,
"stop": ["\n\n"]
})
elif analysis['intent'] == 'creative_writing':
config.update({
"temperature": 0.8,
"presence_penalty": 0.5
})
return config
# 调用示例
response = client.chat.completions.create(
model="gpt-4",
messages=[...],
**dynamic_prompt(user_input)
)工作流引擎实现:
from langchain_core.runnables import RunnableParallel
workflow = RunnableParallel({
"step1": lambda x: {"subtask1": x["input"][:100]},
"step2": lambda x: {"subtask2": x["input"][100:200]},
"step3": lambda x: {"subtask3": x["input"][200:]}
})
def process_complex_task(input_text: str):
return workflow.invoke({"input": input_text})
# 使用示例
result = process_complex_task("长文本输入...")搜索引擎整合:
from langchain_community.utilities import GoogleSerperAPIWrapper
class ResearchAgent:
def __init__(self):
self.search = GoogleSerperAPIWrapper()
def run(self, query: str) -> str:
results = self.search.results(query)
context = "\n".join([r['snippet'] for r in results[:3]])
prompt = f"""
基于以下搜索结果:
{context}
回答:{query}
"""
return basic_prompt(prompt)
# 使用示例
agent = ResearchAgent()
print(agent.run("2024年LLM领域最新技术突破"))数据库连接示例:
from sqlalchemy import create_engine
class DBAgent:
def __init__(self, db_url: str):
self.engine = create_engine(db_url)
def query_to_sql(self, question: str) -> str:
prompt = f"""
将自然语言转换为SQL:
问题:{question}
表结构:users(id, name, age)
要求:使用SQLite语法
"""
return basic_prompt(prompt)
def execute(self, question: str):
sql = self.query_to_sql(question)
with self.engine.connect() as conn:
return conn.execute(sql)
# 使用示例
agent = DBAgent("sqlite:///mydb.db")
print(agent.execute("查询年龄大于30的用户"))
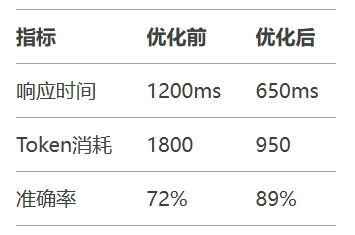
推荐工具链:
调试工具:Promptfoo(提示词AB测试)
监控平台:LangSmith(全链路追踪)
部署框架:FastAPI + Docker



