检索增强生成(Retrieval-Augmented Generation) 通过将外部知识库与大模型结合,彻底解决了传统智能体的三大痛点:
知识时效性:实时接入最新数据(如股票行情/政策文件)
领域专业性:连接企业私有数据库(如医疗病例/法律条文)
可信度验证:基于检索结果生成,降低模型"幻觉"风险
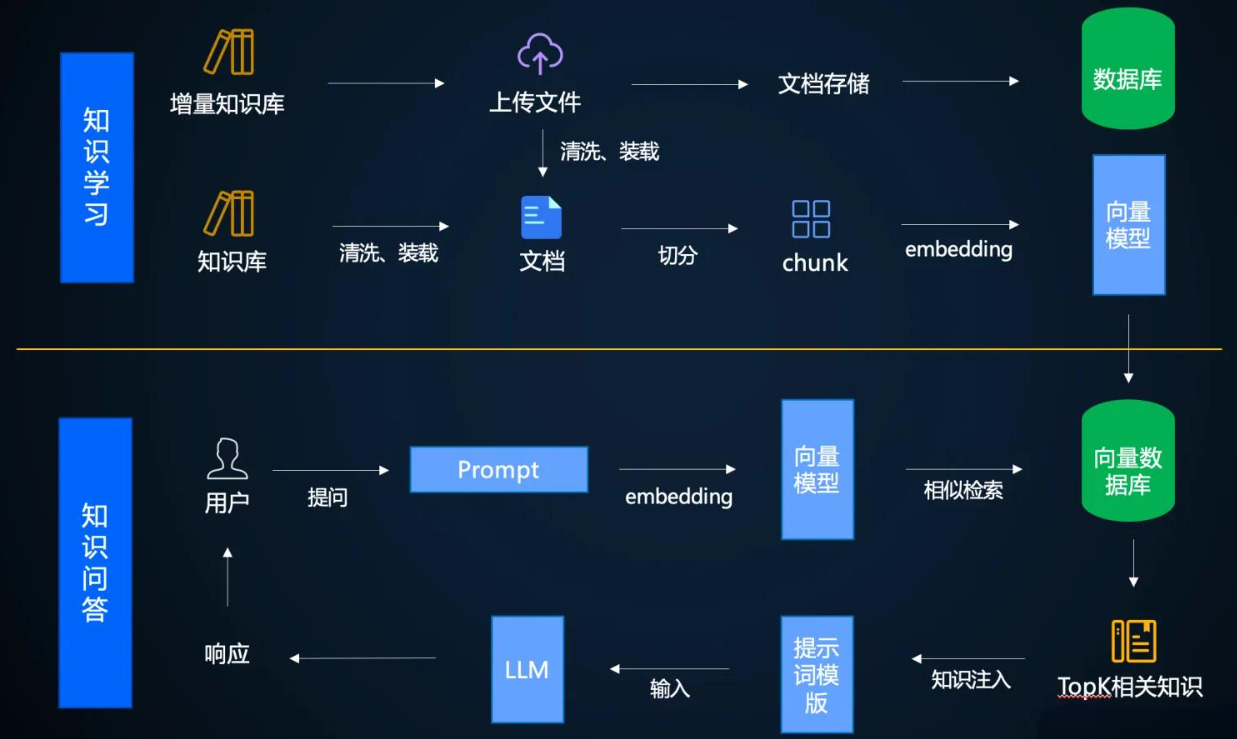
核心原则:数据质量 > 数据数量
# 文本预处理标准化流程 from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=50, separators=["\n\n", "\n", "。", "!"] ) documents = text_splitter.split_documents(raw_docs)
关键技巧:
添加元数据过滤标签(如{source: "财务报告", year: 2023})
对表格/公式采用混合分块策略
混合检索策略:
# 混合检索实现(关键词+向量) from langchain.retrievers import BM25Retriever, EnsembleRetriever from langchain_community.vectorstores import Chroma bm25_retriever = BM25Retriever.from_documents(docs) vector_retriever = Chroma.from_documents(docs, embeddings).as_retriever() ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, vector_retriever], weights=[0.4, 0.6] )
进阶功能:
时间衰减因子:优先返回近期文档
权限过滤器:根据用户角色过滤敏感内容
动态上下文注入模板:
prompt_template = """ 基于以下知识片段回答问题,若信息不足则明确告知: {context} 当前时间:{current_time} 用户身份:{user_role} 问题:{question} """核心技巧:
添加否定指令:若文档未提及,切勿虚构答案
支持多文档引用:【据2023年报第5章】数据显示...
自动化评估体系:
# RAG三元组评估指标 def evaluate_rag(qa_pair): # 检索相关性 retrieval_score = calculate_similarity(query, retrieved_docs) # 生成准确性 answer_accuracy = cross_check_with_golden_data(answer) # 逻辑一致性 consistency = check_factual_consistency(answer) return weighted_score([0.3, 0.5, 0.2])
优化方向:
Bad Case分析:建立错误类型标签体系
热更新机制:实时监控知识库变动
输入:企业名称/行业动态
输出:风险评估报告+预警建议
数据源:工商信息库、舆情数据库、财报PDF
模块1:多源数据加载
# PDF表格提取 from unstructured.partition.pdf import partition_pdf pdf_elements = partition_pdf( "financial_report.pdf", strategy="hi_res", extract_tables=True )
模块2:风控决策链
from langchain_core.runnables import RunnableLambda risk_chain = ( RunnableLambda(detect_risk_factors) | RunnableLambda(retrieve_regulations) | RunnableLambda(generate_warning) )
模块3:可视化报告生成
# 结合Matplotlib自动绘图 def create_risk_chart(data): plt.figure(figsize=(10,6)) sns.barplot(x='factor', y='score', data=data) plt.savefig('risk_analysis.png') return ""分层索引架构
热数据:内存级向量库(Redis)
温数据:分布式检索引擎(Elasticsearch)
冷数据:对象存储按需加载
向量量化压缩
# 使用SQ8量化压缩 model.encode(text, quantization='sq8', device='cuda')
异步并行管道
# 并行执行检索与生成 async with asyncio.TaskGroup() as tg: retrieval_task = tg.create_task(retrieve_docs(query)) generation_task = tg.create_task(generate_draft(query))
缓存加速机制
from langchain.cache import SQLiteCache llm = OpenAI(cache=SQLiteCache("rag_cache.db"))硬件级优化
使用FlashAttention加速Transformer
部署Triton推理服务器
混合精度训练
trainer = Trainer( precision='bf16-mixed', deepspeed_config=deepspeed_config )
动态知识图谱:实时构建实体关系网络
多模态检索:支持图文混合问答
自优化系统:基于用户反馈自动调整检索策略
边缘智能:本地化轻量部署方案



