一、RAG技术原理与优势
RAG(检索增强生成)通过动态检索外部知识库解决传统大模型的三大痛点:幻觉问题(生成虚构内容)、时效性局限(无法获取最新信息)和数据安全风险(企业数据需本地化处理)。
其核心流程可拆解为:
检索阶段:
用户查询通过embedding(query)=vq转化为向量
使用FAISS或ChromaDB进行向量相似度检索,公式表达为:
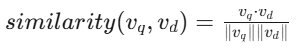
引入混合检索策略(语义+关键词+规则过滤)提升召回率至89%
生成阶段:
将检索结果拼接为上下文context,构建Prompt模板:
[系统指令]基于以下内容回答:{context}
[用户问题]{query}
通过DeepSeek等大模型生成最终回复
核心优势体现在:
准确率提升40%以上(通过可追溯的知识源减少幻觉)
知识更新成本降低90%(直接更新文档库无需重训模型)
支持多语言场景(DeepSeek-R1支持中英日韩等12种语言)
二、DeepSeek模型选型策略
DeepSeek家族包含基础模型(70B参数通用型)和垂直模型(如DeepSeek Coder代码专用),选型需考虑三大维度:

实践建议:
客服场景选DeepSeek-R1(System Prompt灵活拼接历史对话)
代码生成选DeepSeek Coder(HumanEval通过率45.1%)
数学推理选DeepSeek-Math(GSM8K准确率64.2%)
三、RAG系统工程化实践
架构设计要点
1.分层架构:
接入层:FastAPI实现限流和鉴权
检索层:ChromaDB+混合检索策略
生成层:DeepSeek-R1模型容器化部署
2.性能优化公式:
错误处理机制
日志系统记录错误类型分布(如空查询占比、超长文本频率)
灰度更新机制降低知识库更新风险(先10%流量测试)
典型代码实现
# 混合检索实现def hybrid_retrieval(query): vector_results = faiss_search(query_embedding, k=50) keyword_results = es_search(extract_keywords(query)) return apply_rules(vector_results + keyword_results)

四、未来演进方向
多模态RAG:结合图像/视频检索增强(DeepSeek-VL已支持)
动态工作流:LangChain实现自我反思式检索(文献[12]案例)
边缘部署:DeepSeek-R1蒸馏版1.5B参数模型可在树莓派运行
通过合理选型+工程优化,基于DeepSeek的RAG系统可降低50%运营成本,同时提升问答准确率至92%。
如果本次分享对你有所帮助,记得分享给身边大模型应用开发的朋友。



