RAG(检索增强生成)通过结合外部知识检索与生成模型,显著提升大模型在专业场景的准确性。其核心流程包括知识加载、分块处理、向量化存储、语义检索和生成增强五大模块。以DB-GPT框架为例,知识加工流水线支持Markdown/PDF/HTML等格式解析,通过多粒度分片策略(按段落/页/语义单元)和元数据提取(如知识图谱三元组)构建结构化知识库。
分块策略对比:
固定窗口分块:简单高效但可能割裂语义
语义分块:基于句间相似度动态划分,需配合NLP模型
层级分块:构建树状结构支持多粒度检索
# 基于语义分块的实现示例 from langchain.text_splitter import SemanticChunker splitter = SemanticChunker(embeddings) chunks = splitter.create_documents([text])
传统RAG存在上下文冗余问题,Self-RAG通过引入**反思标记(Retrieve/Critique)**实现动态检索控制。模型在生成过程中自主判断是否需要检索,并对检索结果进行相关性评分,仅保留高置信度内容。训练时通过GPT-4生成反思标记数据,蒸馏到轻量化Critic模型中。
关键步骤:
按需检索:生成过程中动态触发检索请求
多候选评估:并行处理多个检索片段生成候选结果
反思过滤:基于Critic分数筛选最优响应

Embedding模型通过将高维离散数据映射到低维连续向量空间,捕捉语义关联性。例如"king - man + woman ≈ queen"的向量运算证明其具备语义代数能力。主流模型可分为:
静态嵌入:Word2Vec/GloVe(词级固定表示)
动态嵌入:BERT/GPT(上下文敏感表示)
多模态嵌入:CLIP(跨文本/图像对齐)
模型选择建议:
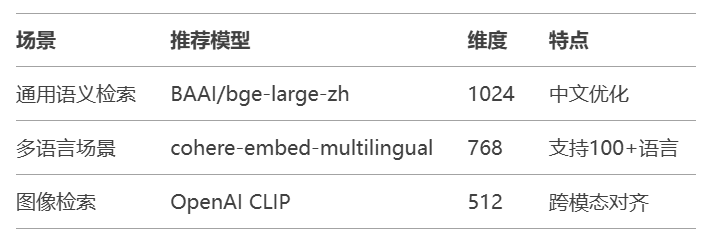
通过对比学习微调可提升垂直领域表现。以Spring AI框架为例,支持通过Adapter机制在预训练模型基础上注入领域知识:
// Spring AI微调配置示例
@Bean
public EmbeddingModel embeddingModel() {
return new BertEmbeddingModel()
.withAdapter(new DomainAdapter("medical"))
.withFineTuneDataset("medical_corpus.json");
}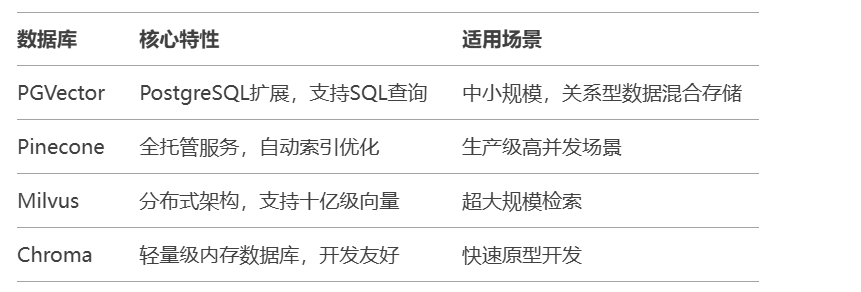
PostgreSQL+PGVector实战:
CREATE TABLE documents ( id SERIAL PRIMARY KEY, content TEXT, embedding VECTOR(1536) ); CREATE INDEX ON documents USING ivfflat (embedding vector_l2_ops);
结合稠密向量检索与稀疏关键词检索,通过Reranker模型(如BGE-Reranker)对初筛结果重排序,提升召回率与准确率平衡。
LlamaIndex提供从数据接入到评估的完整RAG解决方案,其核心组件包括:
Data Connectors:支持200+数据源接入
Node Parser:实现语义分块与元数据抽取
Query Engine:支持多跳推理与混合检索
典型开发流程:
from llama_index.core import VectorStoreIndex
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 数据加载
documents = SimpleDirectoryReader("./data").load_data()
# 索引构建
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
index = VectorStoreIndex.from_documents(documents, embed_model=embed_model)
# 查询引擎配置
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("RAG的核心价值是什么?")多模态RAG:通过Unstructured工具解析图文混合文档,分别生成文本摘要与图像特征向量5
知识图谱增强:利用Neo4j存储实体关系,与向量检索结果融合提升推理能力
增量索引:通过DocumentManagement模块实现数据动态更新
Dify提供从数据标注、模型训练到监控的全生命周期管理:
数据版本控制:跟踪训练集迭代过程
AB测试平台:对比不同模型版本效果
监控看板:实时追踪响应质量与延迟指标
关键配置项:
pipeline: data_collection: sources: [user_feedback, log_analysis] model_training: trigger: daily hyperparameters: learning_rate: 2e-5 batch_size: 32 deployment: canary_release: 10%
内置四维评估指标:
忠实度(Faithfulness):检测幻觉内容
相关性(Relevance):结果与问题匹配度
流畅度(Fluency):语言自然程度
多样性(Diversity):避免模板化响应
分级缓存:对高频查询结果建立多级缓存(内存+Redis)
量化压缩:使用GPTQ/4-bit量化减小Embedding模型体积
异步流水线:实现检索与生成的并行化处理




