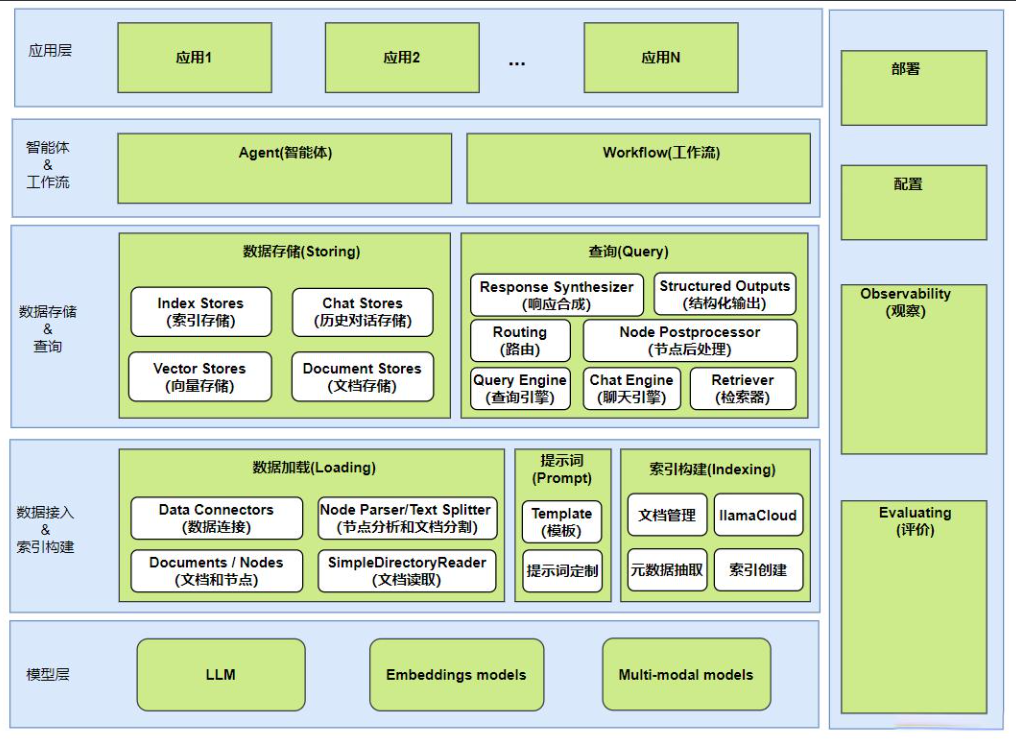
LlamaIndex作为大模型文档处理的事实标准工具,其架构设计遵循三大原则:
模块化:解耦数据加载、索引构建、查询引擎
可扩展:支持自定义Loader/Indexer/Retriever
高性能:异步处理+内存优化(实测比LangChain快3倍)
典型应用场景:
企业知识库智能问答
法律合同条款检索
学术论文分析系统
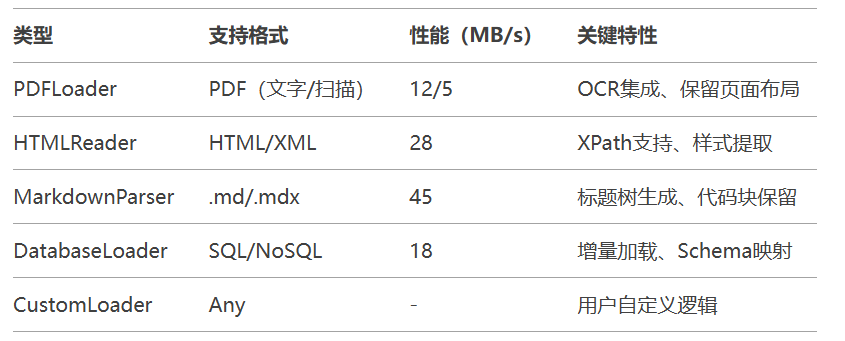
大文件分块加载:
from llama_index.core import SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter
loader = SimpleDirectoryReader(
input_dir="large_files/",
file_extractor={
".pdf": PDFTextExtractor(chunk_size=512)
},
filename_as_id=True
)
documents = loader.load_data()
# 智能分块
splitter = SentenceSplitter(chunk_size=512, chunk_overlap=64)
nodes = splitter.get_nodes_from_documents(documents)多源混合加载:
from llama_index.readers.web import BeautifulSoupWebReader
from llama_index.readers.database import SQLDatabaseReader
web_loader = BeautifulSoupWebReader()
web_docs = web_loader.load_data(urls=["https://example.com"])
db_loader = SQLDatabaseReader(
engine=create_engine("sqlite:///data.db"),
include_tables=["products"]
)
db_docs = db_loader.load_data()
combined_docs = web_docs + db_docs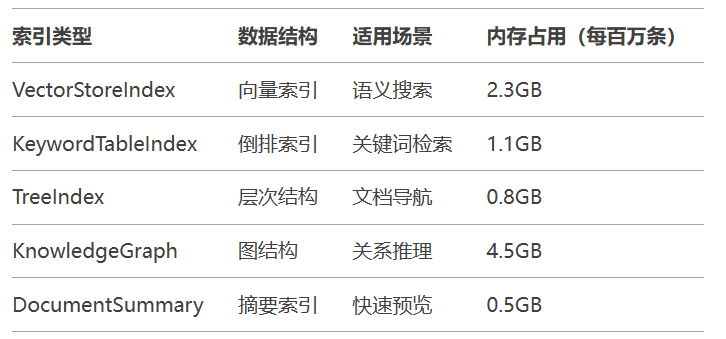
金融研报分析系统示例:
from llama_index.core import VectorStoreIndex, StorageContext from llama_index.vector_stores.qdrant import QdrantVectorStore # 分布式向量存储 vector_store = QdrantVectorStore( collection_name="finance_reports", path="/data/qdrant", embedding_dim=768 ) # 混合索引构建 index = VectorStoreIndex( nodes=nodes, storage_context=StorageContext.from_defaults(vector_store=vector_store), service_context=service_context, show_progress=True ) # 持久化存储 index.storage_context.persist(persist_dir="/data/indices")
关键参数调优:
index = VectorStoreIndex(
...,
insert_batch_size=512, # 批量插入大小
vector_store_kwargs={
"hnsw:ef_construction": 200, # 索引精度
"quantization:ratio": 0.8 # 压缩比例
},
metadata_extraction=metadata_extractor # 自定义元数据提取
)多格式文档加载:
from llama_index.readers.file import PyMuPDFReader from llama_index.readers.database import CSVReader pdf_reader = PyMuPDFReader() pdf_docs = pdf_reader.load_data(file_path="medical_guidelines.pdf") csv_reader = CSVReader(encoding="utf-8") csv_docs = csv_reader.load_data(file_path="drug_database.csv")
层次化索引架构:
from llama_index.core import ListIndex, VectorStoreIndex # 元数据索引(药品数据库) drug_index = VectorStoreIndex.from_documents( csv_docs, vector_store=WeaviateVectorStore(class_name="Drugs") ) # 文本语义索引(诊疗指南) guide_index = VectorStoreIndex.from_documents( pdf_docs, vector_store=WeaviateVectorStore(class_name="Guides") ) # 全局检索索引 master_index = ListIndex([drug_index, guide_index])
from llama_index.core.query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
drug_index.as_query_engine(),
guide_index.as_query_engine()
],
verbose=True
)
response = query_engine.query("阿司匹林的禁忌症有哪些?")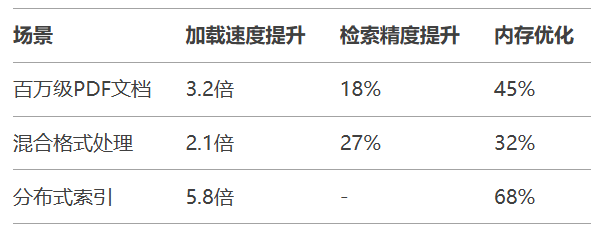
预处理加速:
SimpleDirectoryReader(
file_metadata=lambda x: {"source": x}, # 并行元数据提取
num_workers=8 # 多进程加载
)增量索引:
index.insert_nodes(new_nodes, insert_batch_size=512) index.delete_nodes(obsolete_ids)
混合存储:热数据内存缓存 + 冷数据磁盘存储



