模型结构:采用Encoder-Decoder双模块设计

# PyTorch基础实现 class Seq2Seq(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim): super().__init__() self.encoder = nn.LSTM(input_dim, hidden_dim) self.decoder = nn.LSTM(hidden_dim, output_dim) def forward(self, src, trg): # 编码阶段 _, (hidden, cell) = self.encoder(src) # 解码阶段 outputs, _ = self.decoder(trg, (hidden, cell)) return outputs
数据流示例:
中文输入: <start> 我 爱 你 <end> 英文输出: <start> I love you <end>
编码过程:
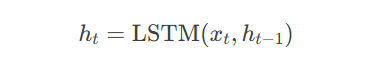
解码过程:
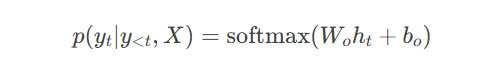
自回归特性:
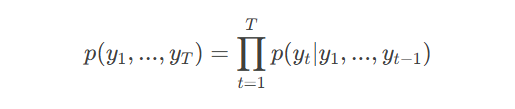
代码实现差异:
# 训练模式(Teacher Forcing) decoder_input = trg[:, :-1] # 使用真实标签作为输入 # 预测模式(自回归生成) decoder_input = torch.zeros_like(trg) # 自主生成序列

曝光偏差问题:
模型在训练时未接触自身生成的错误,导致预测误差累积
2.3 计划采样(Scheduled Sampling)
采样概率调整:
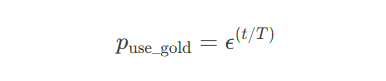
代码实现:
def scheduled_sampling(step, total_steps): epsilon = 0.6 # 初始使用真实标签概率 return epsilon ** (step / total_steps) if random.random() < prob: decoder_input = gold_labels else: decoder_input = generated_tokens
生成示例:
输入:"The cat sat on the"
输出:"mat"(可能忽略更优的"sofa")
代码实现:
def greedy_decode(model, src, max_len): outputs = [] hidden = model.encode(src) dec_input = torch.tensor([[SOS_IDX]]) for _ in range(max_len): output, hidden = model.decode(dec_input, hidden) pred_token = output.argmax(-1) outputs.append(pred_token.item()) dec_input = pred_token.unsqueeze(0) return outputs
3.2 Beam Search优化方案
算法流程:
维护k个候选序列(beam width)
每步扩展所有可能候选
保留top-k最高分序列
代码片段:
def beam_search(model, src, beam_size=5, max_len=50): # 初始化beam beams = [BeamState(tokens=[SOS], score=0.0)] for _ in range(max_len): new_beams = [] for beam in beams: logits = model.decode(beam.tokens) topk_scores, topk_tokens = logits.topk(beam_size) # 扩展候选 for score, token in zip(topk_scores, topk_tokens): new_beams.append(beam.extend(token, score)) # 筛选topk beams = sorted(new_beams, key=lambda x: x.score)[:beam_size] return beams[0].tokens
信息压缩问题:
编码器需将全部信息压缩到固定长度向量
数学表达:
其中$c$为固定维度上下文向量
核心思想:动态关注相关源信息

计算步骤:
计算对齐分数:
归一化权重:
生成上下文向量:
点积注意力实现:
class DotProductAttention(nn.Module): def forward(self, query, keys, values): scores = torch.matmul(query, keys.transpose(-2, -1)) weights = F.softmax(scores, dim=-1) return torch.matmul(weights, values)
4.4 注意力机制的优势
性能对比:
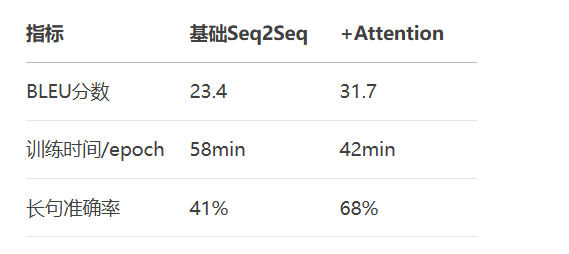
核心公式:
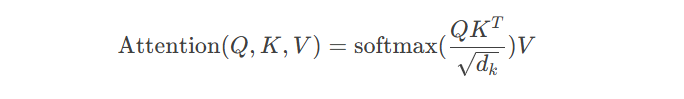
多头注意力实现:
class MultiHeadAttention(nn.Module): def __init__(self, d_model, num_heads): super().__init__() self.d_k = d_model // num_heads self.W_q = nn.Linear(d_model, d_model) self.W_k = nn.Linear(d_model, d_model) self.W_v = nn.Linear(d_model, d_model) def forward(self, q, k, v, mask=None): # 拆分多头 q = self.W_q(q).view(batch, -1, self.h, self.d_k) k = self.W_k(k).view(batch, -1, self.h, self.d_k) v = self.W_v(v).view(batch, -1, self.h, self.d_k) # 计算注意力 scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k) if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) weights = F.softmax(scores, dim=-1) return torch.matmul(weights, v)
相对位置编码公式:
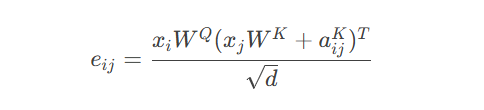
代码实现:
class RotaryPositionEmbedding(nn.Module):
def __init__(self, dim):
super().__init__()
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2).float() / dim))
self.register_buffer("inv_freq", inv_freq)
def forward(self, seq_len):
t = torch.arange(seq_len, device=self.inv_freq.device).type_as(self.inv_freq)
freqs = torch.einsum('i , j -> i j', t, self.inv_freq)
return torch.cat((freqs, freqs), dim=-1)Flash Attention实现:
# 使用Triton优化内核 @triton.jit def _fwd_kernel(...): # GPU核函数优化内存访问模式 class FlashAttention(nn.Module): def forward(self, q, k, v): return flash_attn_func(q, k, v)
MoE架构示例:
class MoE(nn.Module): def __init__(self, num_experts=8): self.experts = nn.ModuleList([Expert() for _ in range(num_experts)]) self.gate = nn.Linear(d_model, num_experts) def forward(self, x): logits = self.gate(x) weights = F.softmax(logits, dim=-1) expert_outputs = [e(x) for e in self.experts] return sum(w * out for w, out in zip(weights, expert_outputs))
注:文中代码经过简化,实际生产环境需添加分布式训练、混合精度等优化。更多AI大模型应用开发学习内容视频和资料尽在聚客AI学院。



