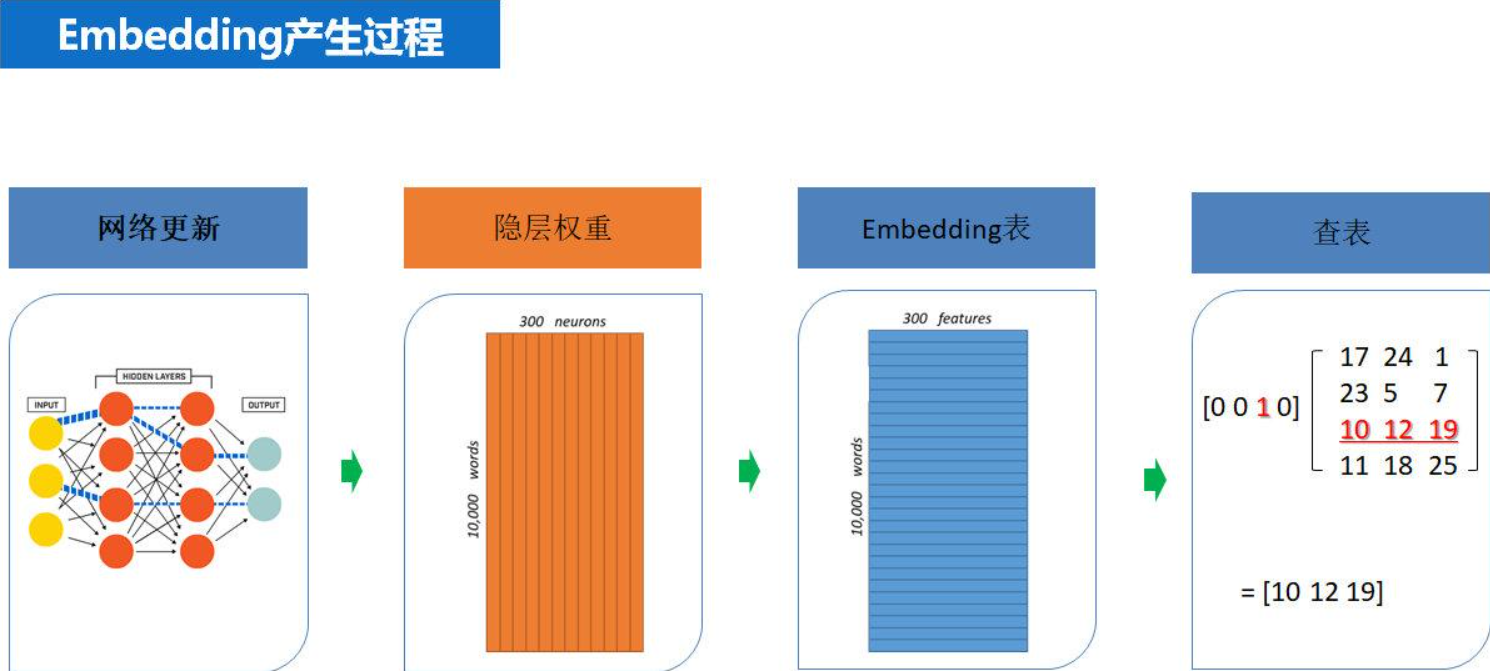
Embeddings是将高维离散数据映射到低维连续向量空间的技术。其核心思想是让相似对象在向量空间中距离更近,如"king"和"queen"的向量距离应小于"king"和"apple"的距离。
数学表达:
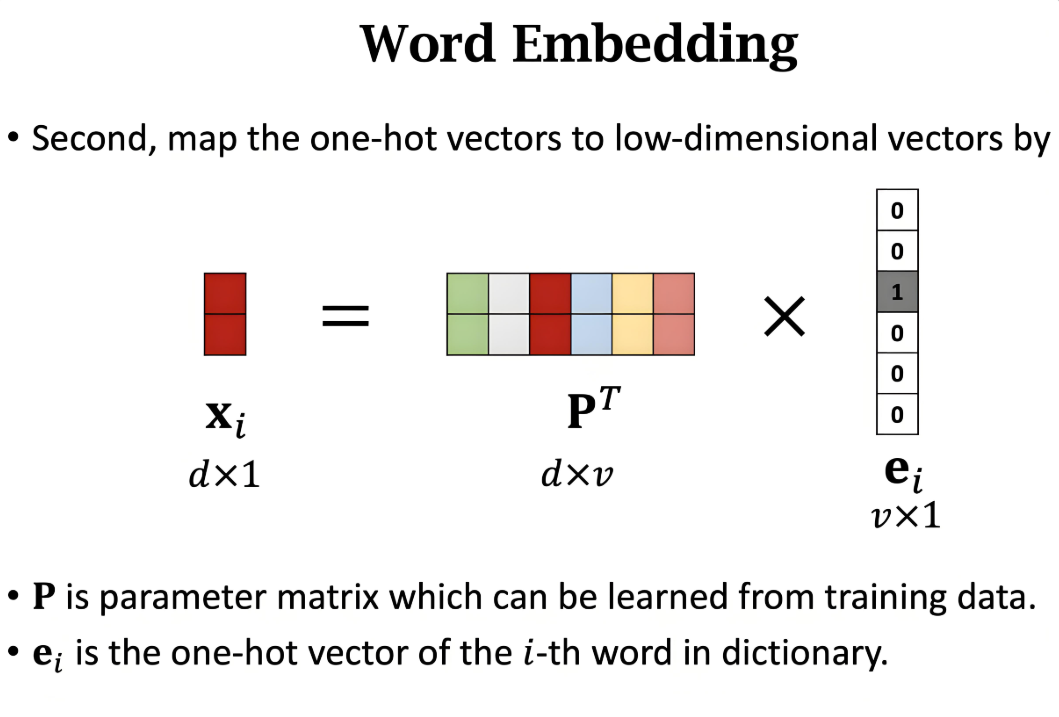
给定原始数据点 x∈RD,通过嵌入函数 f:RD→Rd 得到:
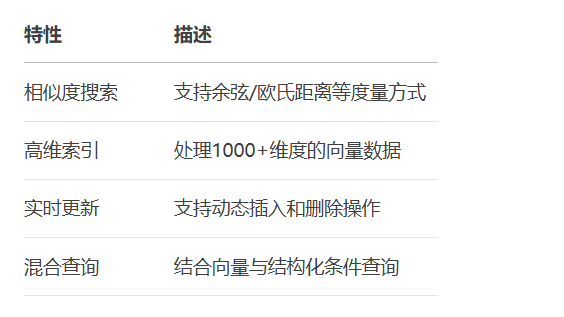
N-Gram通过滑动窗口捕捉局部词序特征:
from nltk import ngrams
text = "natural language processing"
bigrams = list(ngrams(text.split(), 2))
# 输出:[('natural', 'language'), ('language', 'processing')]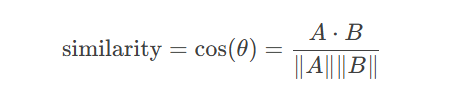
Python实现:
import numpy as np def cosine_similarity(a, b): return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
from gensim.models import Word2Vec sentences = [["natural", "language", "processing"], ["deep", "learning"]] model = Word2Vec(sentences, vector_size=100, window=5, min_count=1) print(model.wv["natural"]) # 输出100维词向量
通过Skip-Gram模型学习词间关系:
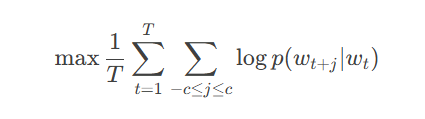
其中上下文概率计算:
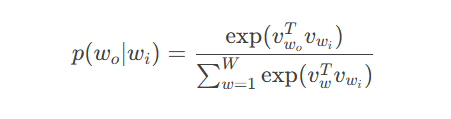
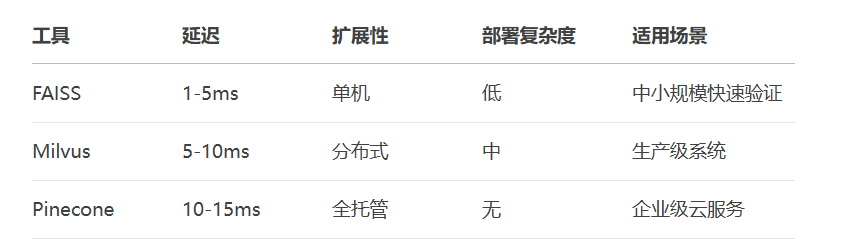
# 传统SQL查询 SELECT * FROM products WHERE category='electronics' # 向量数据库查询 db.query(vector=user_vector, top_k=10)
from transformers import AutoTokenizer, AutoModel
import faiss
# 生成文本向量
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs).last_hidden_state.mean(dim=1)
# 构建Faiss索引
dimension = 768
index = faiss.IndexFlatIP(dimension)
index.add(text_vectors)
# 相似度搜索
D, I = index.search(query_vector, 5)from deepseek import DeepseekEmbedding # 知识库初始化流程 class KnowledgeBase: def __init__(self): self.encoder = DeepseekEmbedding() self.index = faiss.IndexHNSWFlat(1024, 32) def add_document(self, text): vector = self.encoder.encode(text) self.index.add(vector) def search(self, query, top_k=3): q_vec = self.encoder.encode(query) return self.index.search(q_vec, top_k)
graph LR A[Embedding基础] --> B[文本特征工程] B --> C[向量索引优化] C --> D[混合检索系统] D --> E[分布式向量数据库]
更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。



