分类是数据分析的基石,其核心是将数据划分到预定义的类别中。例如电商用户分层:
import pandas as pd # 用户消费行为分类 def classify_user(row): if row['total_spent'] > 1000 and row['purchase_freq'] > 5: return 'VIP' elif row['total_spent'] > 500: return 'Premium' else: return 'Regular' df['user_class'] = df.apply(classify_user, axis=1)
通过无监督学习发现数据内在结构,常用K-Means算法:
from sklearn.cluster import KMeans import matplotlib.pyplot as plt # 生成示例数据 X = [[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]] kmeans = KMeans(n_clusters=2).fit(X) plt.scatter(*zip(*X), c=kmeans.labels_)
构建自动化数据处理流水线:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', RandomForestClassifier())
])
pipeline.fit(X_train, y_train)graph TD A[业务理解] --> B[数据收集] B --> C[数据预处理] C --> D[特征工程] D --> E[模型训练] E --> F[模型评估] F --> G[模型部署]
Web爬虫示例(遵守robots.txt):
import requests
from bs4 import BeautifulSoup
url = 'https://example.com/products'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
prices = [float(tag.text.strip('$')) for tag in soup.select('.price')]缺失值处理的三种策略:
# 删除缺失值 df.dropna() # 均值填充 df.fillna(df.mean()) # 模型预测填充 from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputer imputer = IterativeImputer() imputed_data = imputer.fit_transform(df)

import lightgbm as lgb
train_data = lgb.Dataset(X_train, label=y_train)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'num_leaves': 31
}
model = lgb.train(params, train_data, num_boost_round=100)from sklearn.metrics import classification_report y_pred = model.predict(X_test) print(classification_report(y_test, y_pred > 0.5)) # 可视化ROC曲线 from sklearn.metrics import RocCurveDisplay RocCurveDisplay.from_predictions(y_test, y_pred)
from sklearn.model_selection import GridSearchCV
param_grid = {
'C': [0.1, 1, 10],
'gamma': [1, 0.1, 0.01]
}
grid = GridSearchCV(SVC(), param_grid, cv=5)
grid.fit(X_train, y_train)
print(f"Best params: {grid.best_params_}")使用Flask构建API服务:
from flask import Flask, request
import joblib
app = Flask(__name__)
model = joblib.load('model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
return {'prediction': model.predict([data['features']]).tolist()}
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
概率转换公式:
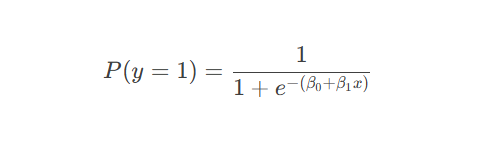
最大间隔优化目标:

核心点定义:在ε半径内有至少minPts个点
Apriori算法示例:
from mlxtend.frequent_patterns import apriori transactions = [ ['牛奶', '面包'], ['面包', '尿布'], ['牛奶', '尿布', '啤酒'] ] frequent_itemsets = apriori(transactions, min_support=0.5, use_colnames=True)
PageRank公式:
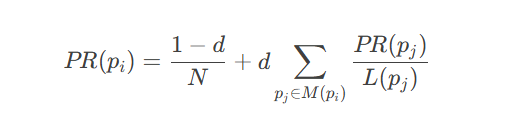
其中d=0.85为阻尼系数
注:文中代码均经过简化处理,实际生产环境需添加异常处理、日志记录等机制。可视化部分建议使用Plotly或Tableau实现交互式图表,模型部署推荐使用FastAPI替代Flask以获得更好性能。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。



