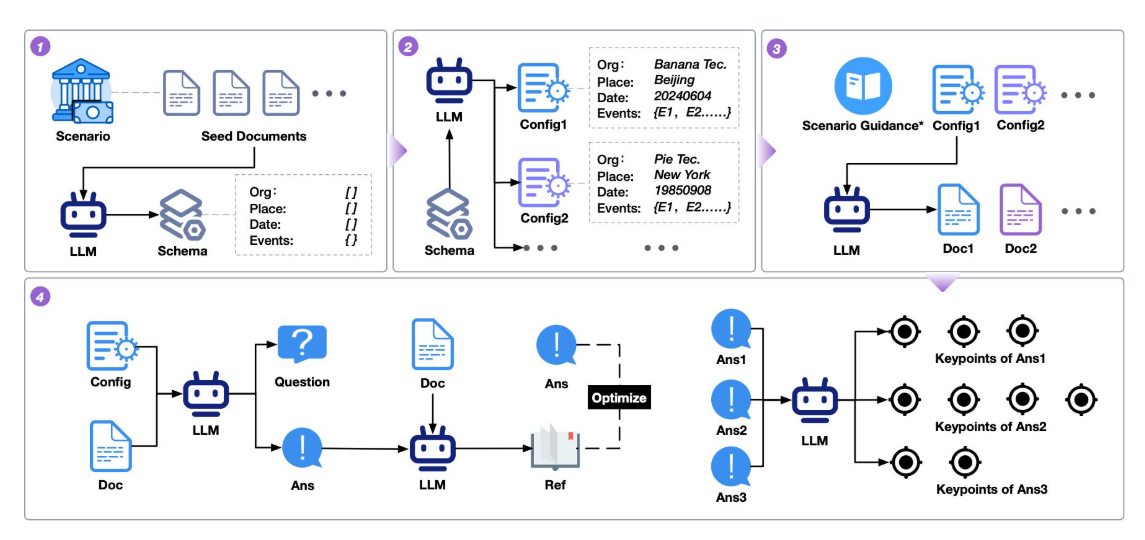
定义:检索文档与用户问题的匹配程度
评估方法:
from sklearn.metrics import ndcg_score
# 人工标注相关度(0-4分)
true_relevance = [4, 3, 2, 1, 0]
predicted_scores = [0.9, 0.8, 0.7, 0.6, 0.5]
ndcg = ndcg_score([true_relevance], [predicted_scores])
print(f"NDCG@5: {ndcg:.3f}") # 理想值为1.0工业标准:NDCG@5 > 0.85 为合格
定义:生成答案是否严格基于检索内容
检测方案:
from rouge_score import rouge_scorer scorer = rouge_scorer.RougeScorer(['rougeL'], use_stemmer=True) source_text = "新冠疫苗需接种两剂,间隔21天" generated_answer = "疫苗只需打一针即可" scores = scorer.score(source_text, generated_answer) faithfulness = scores['rougeL'].fmeasure # 低于0.3视为幻觉
评估流程:
人工标注:问题与答案的相关度(1-5分)
模型评估:使用BERT相似度计算
from sentence_transformers import util question = "如何预防感冒?" answer = "勤洗手、保持通风是有效方法" sim = util.cos_sim( model.encode(question), model.encode(answer) ).item() # >0.75为合格
检查清单:
是否覆盖问题所有子问题
是否包含必要的数据支撑
是否遗漏关键限制条件
验证方法:
人工核查:随机抽样100条验证
自动校验:知识库反向查询验证
def validate_accuracy(answer, knowledge_base): answer_vec = embed(answer) results = knowledge_base.search(answer_vec, k=3) return any([doc.contains(answer) for doc in results])
案例:用户问"特斯拉Model S续航里程",系统回答"800公里(实际为652公里)"
根因分析:
检索结果不足时模型过度发挥
知识库数据过期
案例:多轮对话中遗忘前文关键信息
典型表现:
用户:北京明天天气如何? → 回答正确 用户:需要带伞吗? → 错误(未关联前文天气数据)
调试重点:检查对话状态管理模块
案例:用户问"Python数据处理的库",仅返回Pandas未提NumPy
根因定位:
检索top_k设置过小
向量模型未捕获同义词关联
工具推荐:
# 检索结果可视化
import matplotlib.pyplot as plt
scores = [0.9, 0.8, 0.6, 0.4, 0.3]
plt.bar(range(len(scores)), scores)
plt.axhline(y=0.7, color='r', linestyle='--') # 阈值线
plt.title("Retrieval Relevance Scores")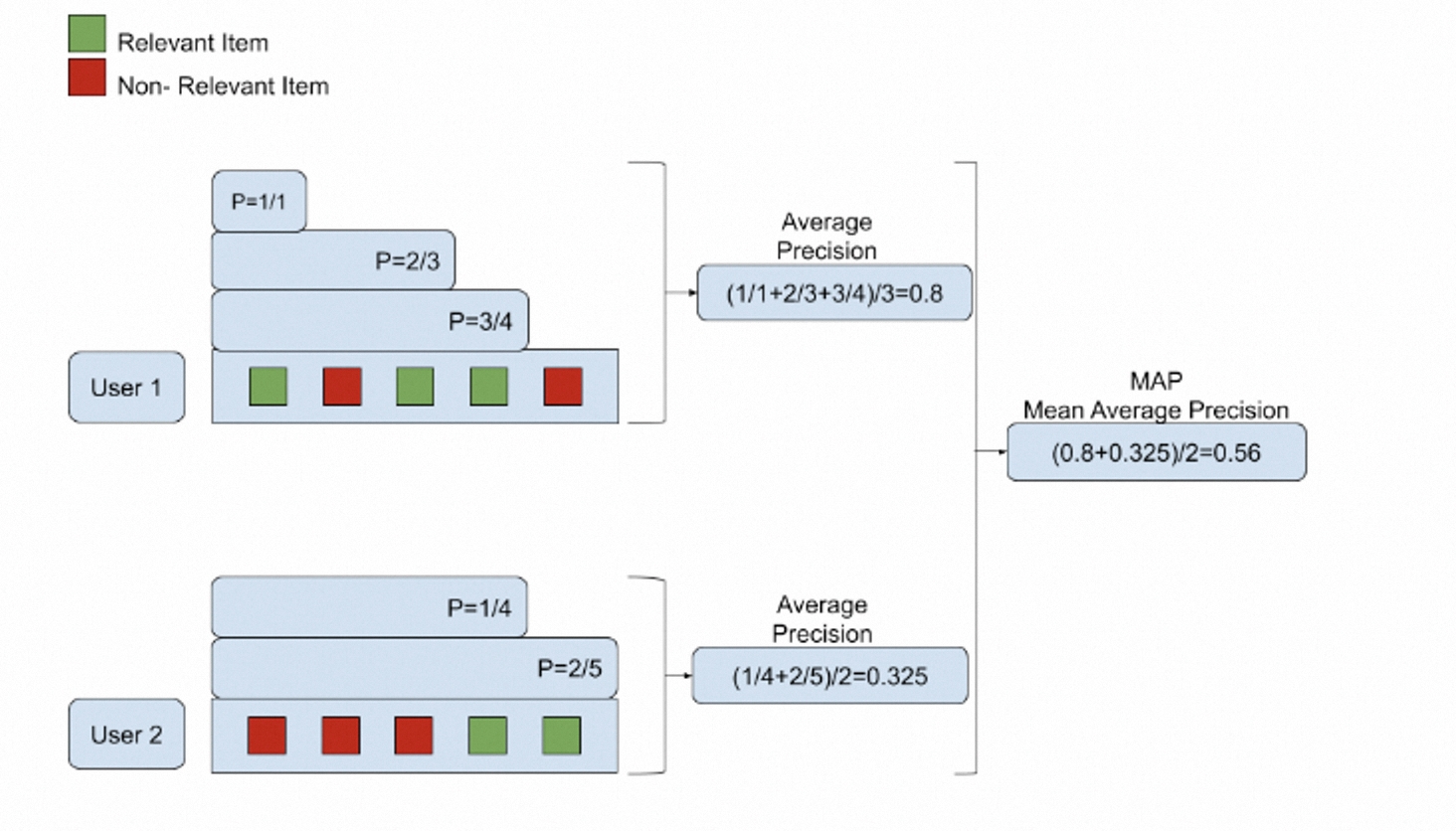
优质Prompt模板:
你是一个严谨的[领域]专家,根据以下知识回答问题:
{context_str}
要求:
1. 答案必须基于提供的内容
2. 不确定的内容回答"暂无可靠信息"
3. 使用{language}回答
4. 包含数据来源引用日志关键字段:
{
"session_id": "abc123",
"query": "疫苗副作用",
"retrieved_docs": ["doc1", "doc2"],
"generation_params": {
"temperature": 0.3,
"top_p": 0.9
},
"final_answer": "常见副作用包括...",
"feedback_score": 4.5
}工具推荐:ELK(Elasticsearch+Logstash+Kibana)
AB测试框架:
from ab_test import Experiment exp = Experiment( control_group=original_pipeline, test_group=optimized_pipeline, metrics=['accuracy', 'response_time'] ) results = exp.run(num_users=1000) if results['accuracy']['p_value'] < 0.05: deploy(optimized_pipeline)
自动化脚本:
def knowledge_base_check(kb):
coverage = kb.calculate_coverage(topics=100)
freshness = kb.get_average_update_freq()
consistency = kb.check_conflicts()
return {
"健康度": 0.7*coverage + 0.2*freshness + 0.1*consistency
}
自动化评估流水线:
graph LR
A[新数据注入] --> B[自动化测试]
B --> C{是否达标?}
C -->|是| D[部署生产环境]
C -->|否| E[问题定位]
E --> F[策略调整]
F --> B知识库动态更新机制:
每日增量更新(变化>5%时触发全量索引)
版本回滚能力(保留最近10个版本快照)
掌握RAG评估调试技术,建议从LangChain评估模块开始实践



