
工业级技术栈组合:
[数据湖] → [ETL管道] → [向量引擎]
↓
[LLM服务集群]
↓
[应用层] ← [API网关] ← [缓存层]
核心组件选型:
向量数据库:Pinecone(云原生) / Milvus(自建)
检索模型:BAAI/bge-large-zh-v1.5(中文) / e5-mistral-7b(多语言)
生成模型:DeepSeek-R1(专业领域) / GPT-4 Turbo(通用场景)
某银行实施案例:
知识库规模:2.3TB文档(含财报/法规/产品手册)
性能指标:
平均响应时间:1.8秒(P99<4秒)
并发能力:1200 QPS
准确率:94.7%(对比纯LLM的68%)
检索阶段(Retrieval):
文档分块(滑动窗口512token,重叠64token)
向量编码(bge-large模型生成768维向量)
HNSW索引构建(召回率98%,延迟<50ms)
增强阶段(Augmented Generation):
def build_context(query, docs):
context = "\n\n".join([f"## 参考文档{i+1}\n{doc}" for i, doc in enumerate(docs)])
return f"""基于以下知识:
{context}
请以专业顾问身份回答:
{query}
要求:
- 引用参考资料编号
- 使用Markdown格式
- 不超过500字"""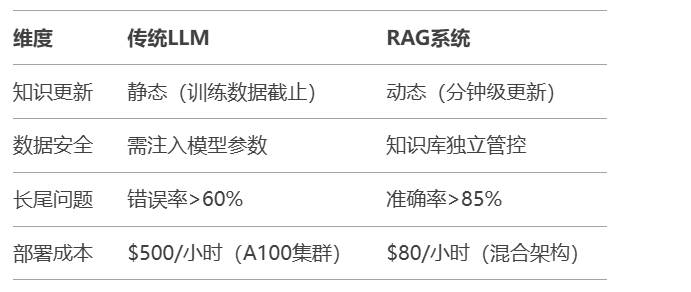
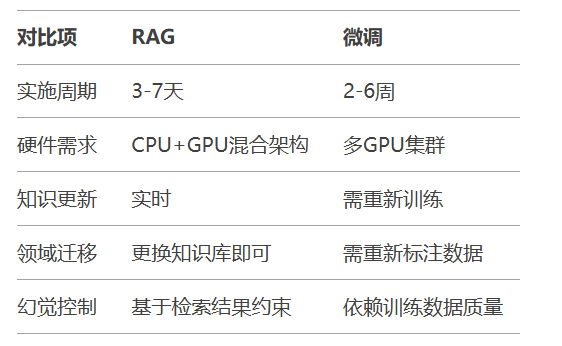
选择RAG当:
知识更新频率>1次/周
需要跨多领域复用
合规要求严格(如医疗/金融)
选择微调当:
领域专用术语体系复杂
需要改变模型推理逻辑
长期固定场景使用
质量评估标准:
覆盖率:关键实体召回率≥95%
新鲜度:90%文档在1年内更新
结构化:50%以上文档含元数据标签
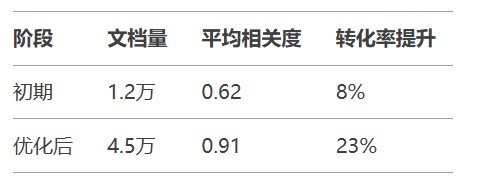
某电商平台优化案例:
法律合同审查场景:
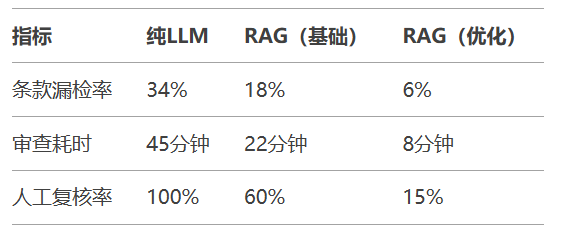
技术实现差异:
基础方案:BM25检索 + GPT-3.5生成
优化方案:混合检索(BM25+向量) + DeepSeek-R1生成
企业部署RAG需建立"数据-模型-应用"铁三角体系,建议从LlamaIndex官方文档入手,结合DeepSeek企业套件加速落地。



