全平台安装命令:
# Linux/macOS curl -fsSL https://ollama.com/install.sh | sh # Windows (PowerShell管理员模式) irm https://ollama.com/install.ps1 | iex
环境变量配置:
# 设置服务地址(允许远程访问) export OLLAMA_HOST=0.0.0.0 export OLLAMA_PORT=11434 # 持久化存储路径 export OLLAMA_MODELS=/data/ollama/models
模型下载与验证:
ollama run deepseek-r1:1.5b # 测试生成 >>> 中国的首都是哪里? >>> 北京是中国的政治和文化中心...
性能调优参数:
# ~/.ollama/config.yaml num_ctx: 4096 # 上下文长度 num_gpu: 1 # 使用GPU数量 maintain_memory: true # 持久化内存
docker-compose.yml核心配置:
version: '3' services: dify: image: langgenius/dify:latest ports: - "3000:3000" volumes: - ./data:/data environment: - DB_URL=postgresql://postgres:password@db:5432/dify - OPENAI_API_KEY=sk-xxx # DeepSeek API密钥 db: image: postgres:13 environment: POSTGRES_PASSWORD: password volumes: - pg_data:/var/lib/postgresql/data volumes: pg_data:
启动命令:
docker-compose up -d # 验证服务 curl http://localhost:3000/api/status
关键参数修改:
# app/config/settings.py
# 知识库设置
KNOWLEDGE_BASE = {
'max_file_size': 500 * 1024 * 1024, # 500MB
'allowed_extensions': ['.pdf', '.docx', '.md']
}
# 模型接入
DEEPSEEK_CONFIG = {
'api_base': 'http://ollama:11434',
'model_name': 'deepseek-r1:1.5b',
'temperature': 0.3,
'max_tokens': 2048
}文档预处理流水线:
from langchain.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = PyMuPDFLoader("企业财报.pdf")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=64,
separators=["\n\n", "\n", "。", "!"]
)
splits = text_splitter.split_documents(docs)向量化存储:
curl -X POST "http://localhost:3000/api/knowledge" \
-H "Content-Type: multipart/form-data" \
-F "file=@财报.pdf" \
-F "config={\"embedding_model\": \"bge-large-zh\", \"index_type\": \"HNSW\"}"检索增强参数:
retrieval_config: top_k: 5 # 召回文档数 score_threshold: 0.75 # 相似度阈值 rerank_model: bge-reranker-large # 重排序模型 generation_config: temperature: 0.3 # 生成稳定性 top_p: 0.9 presence_penalty: 0.5 # 避免重复
效果测试案例:
用户问:公司第三季度净利润增长率是多少? 系统响应: 根据2024Q3财报第15页披露,本季度净利润为5.2亿元,同比增长23.5%。 (数据来源:财报.pdf-P15)
缓存策略:
from redis import Redis from functools import lru_cache redis_conn = Redis(host='localhost', port=6379, db=0) @lru_cache(maxsize=1000) def get_cached_answer(query): # 先查Redis result = redis_conn.get(query) if not result: result = generate_answer(query) redis_conn.setex(query, 3600, result) return result
负载均衡配置:
upstream dify_servers {
server 10.0.0.1:3000 weight=3;
server 10.0.0.2:3000;
server 10.0.0.3:3000 backup;
}
location /api/ {
proxy_pass http://dify_servers;
proxy_set_header X-Real-IP $remote_addr;
}访问控制:
# config/security.yml auth: jwt_secret: your_secure_key rate_limit: enabled: true requests: 100 per: minute api_keys: - name: internal_system key: sk-xxx permissions: [read, write]
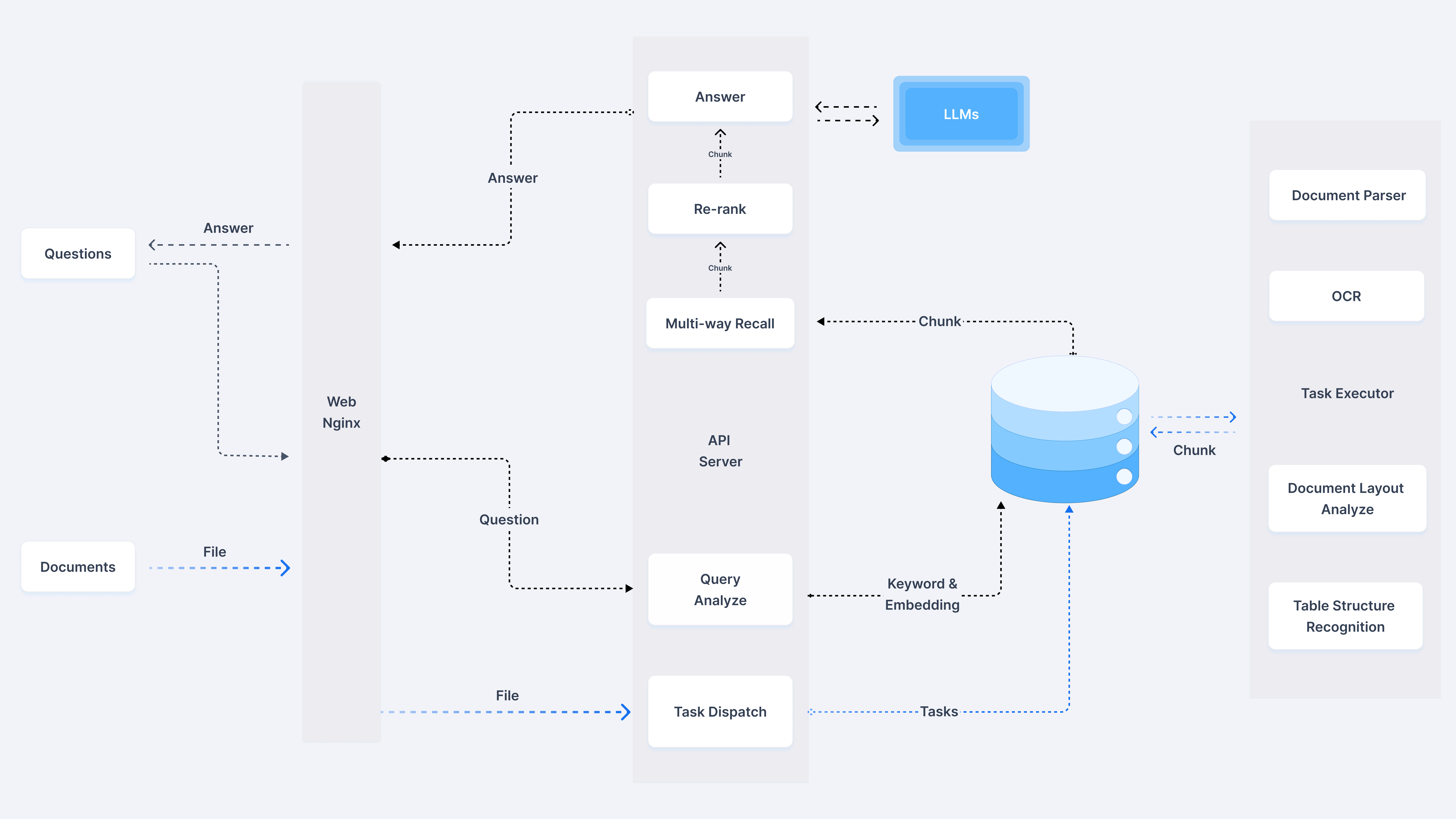
模型选型:DeepSeek-R1 1.5B在精度与效率的平衡
架构设计:Ollama+Dify的轻量级容器化方案
检索优化:混合检索策略(BM25+向量)提升召回率
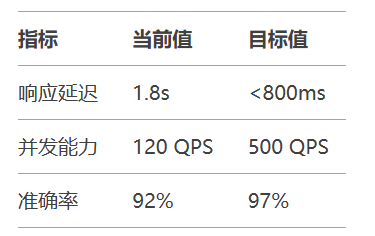
性能优化目标:
部署检查清单:
Ollama服务端口开放(11434)
Docker内存≥16GB
知识库文档预处理完成
API密钥安全存储
压力测试通过(JMeter/Locust)
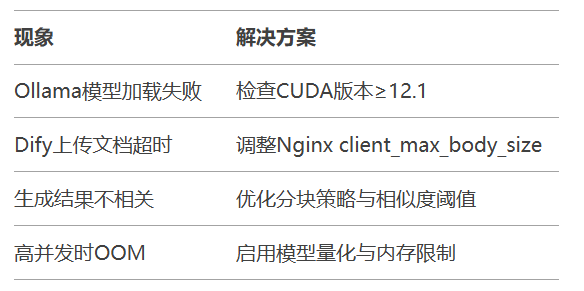
常见问题速查:
掌握本方案后,可进一步探索DeepSeek MoE架构与LlamaIndex高级检索等进阶技术,构建企业级知识中枢系统。



