
核心特点:LLM 刚具备文本生成能力时,开发者通过预定义工具(如搜索、文件操作)和简单决策树,让 Agent 执行基础任务。代表项目如 LangChain、BabyAGI、AutoGPT 早期版本。
局限:LLM 被限制在固定流程中,灵活性低,依赖人工定义工具。
代码示例(基于 AutoGPT 的任务流程):
# 用户设定目标
goal = "获取 Twitter 最新新闻摘要"
# Agent 分解任务
tasks = ["搜索 Twitter 新闻链接", "阅读文章内容", "生成摘要"]
# 执行任务并迭代
for task in tasks:
if task == "搜索 Twitter 新闻链接":
search_results = google_search("Twitter news")
elif task == "阅读文章内容":
articles = read_links(search_results)
elif task == "生成摘要":
summary = generate_summary(articles)注:实际代码需结合 API 调用(如 OpenAI、Google 搜索)和工具链。
第二阶段:认知型 Agent(Cognitive Agents)
技术驱动:GPT-4 等模型增强了推理能力,思维链(Chain-of-Thought)技术让 Agent 能展示内部思考过程。代表框架如 ReAct、Reflexion。
示例场景:客服 Agent 处理用户投诉时,会先分析问题、查询数据库、再生成解决方案。
局限:逻辑链易断裂,长期目标难以维持。
关键代码逻辑:
# 使用 ReAct 框架的伪代码 def react_agent(problem): thought = "我需要先理解用户的问题类型。" action = query_database(problem) observation = get_result(action) final_answer = reflect_and_generate(observation) return final_answer
技术突破:多模态模型(如 GPT-4V)让 Agent 能“看见”图像和界面,结合浏览器自动化技术。代表项目如 BrowserGPT、Adept ACT-1。
应用场景:自动填写网页表单、分析图表数据。
代码示例(模拟浏览器操作):
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://example.com")
# Agent 解析页面元素并操作
search_box = driver.find_element("name", "q")
search_box.send_keys("Twitter news")
search_box.submit()核心能力:长上下文窗口(百万级 Token)支持复杂任务规划,动态适应环境。代表项目如 Devin(自动编程)、OpenHands(机器人控制)8。
局限:资源消耗大,稳定性不足。
架构图示意:
[LLM 核心] → [规划器] → [工具调用] → [环境反馈] ↖________内存管理________↙
终极形态:模型内化所有能力,无需外部框架,自主设定目标。代表如 OpenAI Deep Research(基于强化学习微调)。
示例:用户说“开发一个推荐系统”,Agent 自动完成需求分析、编码、测试部署。
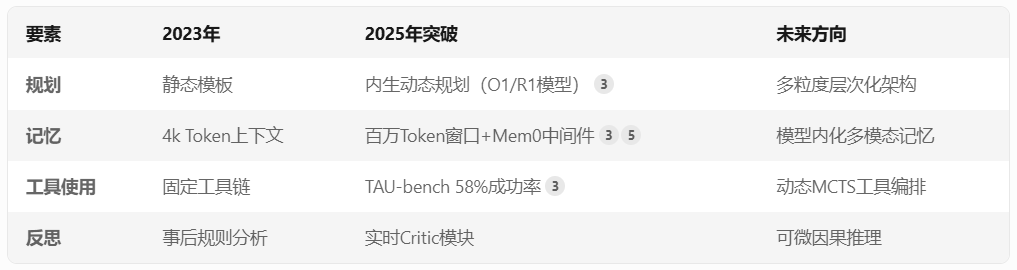
1. 过去(2023年):人工模板驱动
技术特点:依赖人工设计的提示模板(如"分步思考"提示词)和有限决策树,规划流程静态且缺乏灵活性。
代码示例(基于GPT-3时代):
# 固定分步提示模板
prompt = """
请按以下步骤解决问题:
1. 理解用户需求:{query}
2. 调用天气API获取数据
3. 生成自然语言回复
"""
response = llm.generate(prompt)技术突破:
推理模型:O1/R1模型支持动态思维链(Chain-of-Thought)和树状推理(Tree-of-Thought)动态调整:基于环境反馈实时重规划(如任务失败时自动切换工具)
代码示例(Manus Agent动态规划):
def dynamic_planning(goal, context):
# 生成初始规划
plan = llm.generate(f"目标:{goal},当前环境:{context},请生成任务步骤")
while not task_completed:
# 监控执行结果并调整策略
result = execute_step(plan)
if result.status == "failed":
plan = llm.generate(f"修正规划,原步骤:{plan},失败原因:{result.error}")架构设计:
graph TD
A[宏观目标] --> B(战略层:季度销售目标)
B --> C{战术层:月度计划}
C --> D[执行层:周任务分解]
D --> E[操作层:每日具体动作]关键技术:多粒度任务网络(Macro-Micro Task Networks)与实时策略评估模型
短期记忆:100万token上下文窗口 + RAG增强检索(如Mem0的向量索引)
# 长上下文记忆存取 memory_buffer = LongTermMemory(max_tokens=1e6) memory_buffer.store(event="用户偏好:咖啡加糖", timestamp=datetime.now()) # RAG增强查询 relevant_memories = rag_search(query="用户饮食偏好", index=mem0_index)
长期记忆瓶颈:依赖中间件实现记忆持久化(如Letta的时序数据库)
模型内化记忆管理:
class MultimodalMemory: def __encode_video(self, frames): # 使用时空注意力机制编码视频片段 return self.vision_encoder(frames) def retrieve(self, query): # 跨模态检索(文本→视频片段) return cross_modal_search(query)
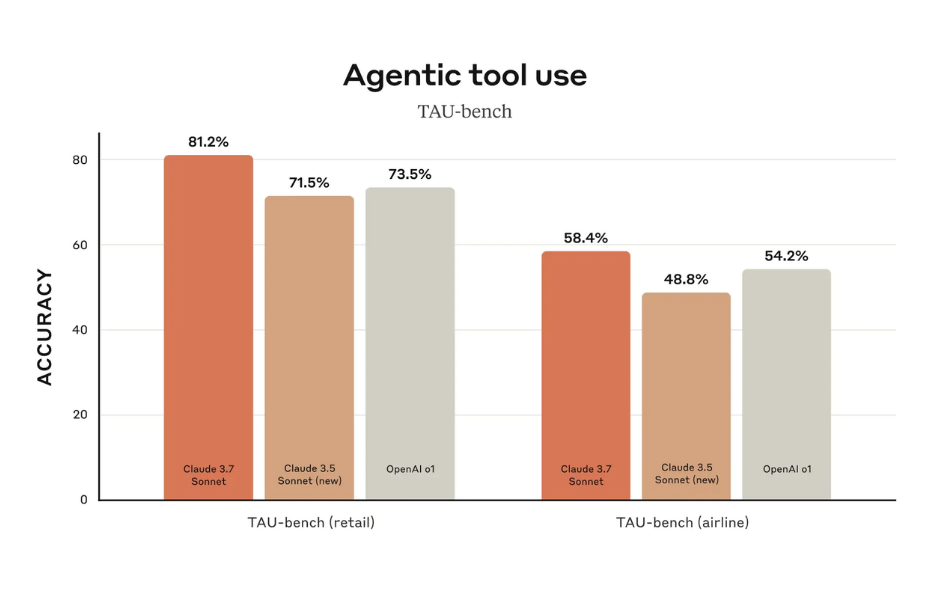
工具调用瓶颈:TAU-bench测试显示复杂场景(如多城市航班比价)成功率仅58%
代码示例(静态工具链):
tools = ["flight_search", "hotel_booking", "calendar_check"] for tool in tools: result = execute_tool(tool, params) if result.failed: break # 单点故障导致任务中断
技术方案:
实时工具编排:基于蒙特卡洛树搜索(MCTS)的动态选择算法
def dynamic_tool_selection(state):
# 评估候选工具效用
candidates = ["search_flight", "check_weather", "query_pricing_api"]
utility_scores = llm.generate(f"评估工具效用:{state} → {candidates}")
return candidates[np.argmax(utility_scores)]架构优化:
graph LR
A[任务状态] --> B{工具效用评估}
B -->|最高分| C[执行工具A]
B -->|次高分| D[备用工具B]
C --> E[更新状态]
E --> F{是否完成?}2023年:基于规则的事后错误分析
2025年:实时反思模型(如MetaGPT的Critic模块)
class SelfReflectionAgent:
def __init__(self):
self.critic = load_model("critic-r1")
def act(self, observation):
action = self.actor(observation)
# 实时反思动作合理性
critique = self.critic.generate(f"评估动作:{action}")
if critique.score < 0.7:
return self.actor(observation, critique.feedback)因果推理框架:建立动作-结果因果图(Causal Graph)实现根因分析
参数化反思:将反思过程编码为可微操作(Differentiable Reflection)
Agent 的发展本质是 模型能力迭代 的体现:从依赖外部工具到内化自主能力。2025 年的关键趋势是 Less Structure, More Intelligence——减少人工框架,释放模型原生智能。开发者应聚焦数据积累(如用户交互日志)和强化学习微调,而非过度设计流程。



