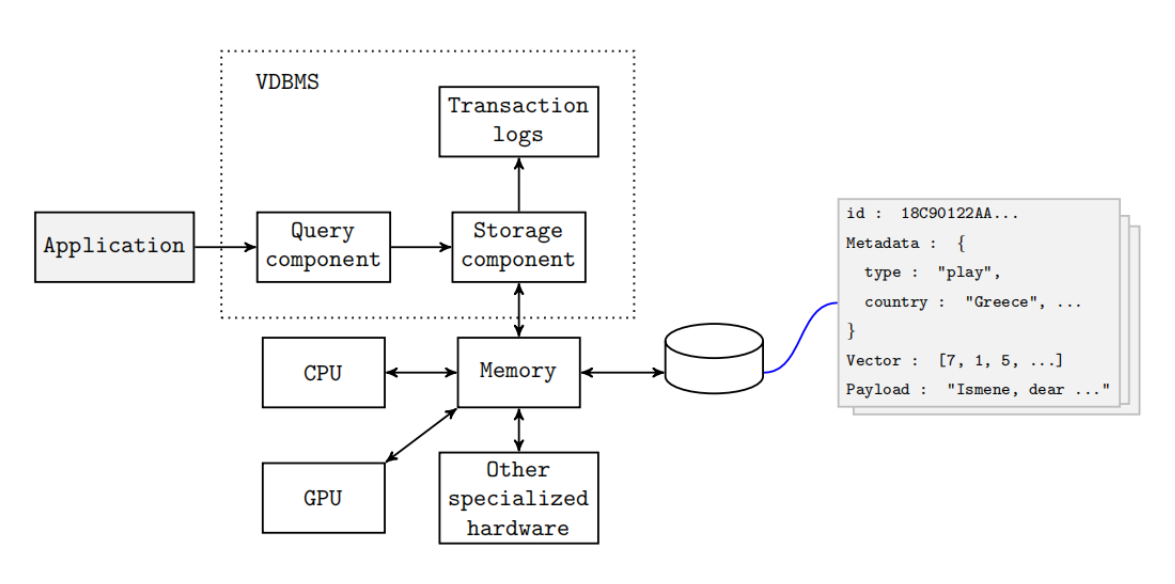
向量数据库(Vector Database)是专为高维向量数据设计的存储与检索系统,通过计算向量间的相似度(如余弦相似度、欧氏距离),实现快速近邻搜索。其核心价值在于解决传统数据库无法高效处理非结构化数据(文本、图像、音视频)的问题。
核心组件:
向量编码器:将数据转换为向量(如BERT、CLIP)
索引结构:加速搜索(如HNSW、IVF)
相似度计算:距离度量算法
典型应用场景:
文本语义搜索(如ChatGPT知识库增强)
图像/视频内容检索
个性化推荐系统
给定查询向量,在数据集中找到与其距离最近的K个向量:
import numpy as np def knn(query: np.ndarray, data: np.ndarray, k: int): # 计算欧氏距离 distances = np.linalg.norm(data - query, axis=1) # 取前K个最小距离的索引 return np.argpartition(distances, k)[:k] # 示例 data = np.random.rand(1000, 512) # 1000个512维向量 query = np.random.rand(512) top_5_indices = knn(query, data, 5)
直接暴力计算复杂度为O(N),需通过索引加速:
树状索引:KD-Tree、Ball-Tree(适合低维数据)
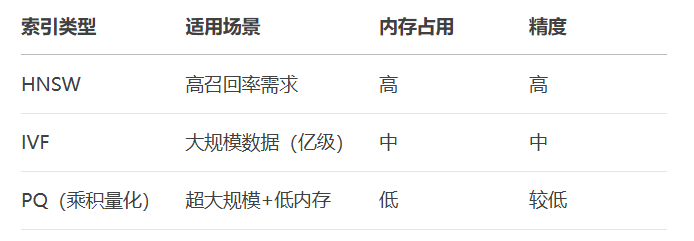
近似最近邻(ANN):HNSW(Hierarchical Navigable Small World)、IVF(Inverted File Index)
代码示例:使用Faiss加速KNN
import faiss
# 创建索引
dim = 512
index = faiss.IndexFlatL2(dim) # 暴力搜索
# index = faiss.IndexHNSWFlat(dim, 32) # HNSW加速
# 添加数据
index.add(data)
# 搜索
distances, indices = index.search(query.reshape(1, -1), 5)
print(f"Top 5结果索引: {indices}")
文本嵌入:Sentence-BERT、OpenAI text-embedding-3
图像嵌入:CLIP、ResNet-50
多模态嵌入:CLIP(联合文本-图像编码)
代码示例:生成文本嵌入
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
texts = ["机器学习", "深度学习", "人工智能"]
embeddings = model.encode(texts)
print(f"嵌入维度: {embeddings.shape}") # 输出: (3, 384)基于用户历史行为生成向量,检索相似物品:
# 用户向量 = 历史交互物品向量的加权平均 user_vector = np.mean(item_embeddings[interacted_items], axis=0) # 检索Top-K相似物品 scores = np.dot(item_embeddings, user_vector) top_k = np.argsort(scores)[-10:][::-1]
轻量级:单机可处理百万级向量
多模态支持:文本、图像、自定义向量
实时更新:支持动态增删数据
import chromadb
# 创建客户端
client = chromadb.Client()
# 创建集合
collection = client.create_collection(name="docs")
# 添加文档
documents = ["机器学习是...", "深度学习基于神经网络..."]
collection.add(
documents=documents,
ids=["id1", "id2"]
)
# 相似性检索
results = collection.query(
query_texts=["什么是神经网络?"],
n_results=1
)
print(f"最相关文档: {results['documents'][0][0]}")from PIL import Image
import clip
# 加载CLIP模型
model, preprocess = clip.load("ViT-B/32")
# 图像编码
image = preprocess(Image.open("cat.jpg")).unsqueeze(0)
image_features = model.encode_image(image)
# 将特征存入Chroma
collection.add(
embeddings=image_features.tolist(),
ids=["img1"]
)
# 图文混合检索
results = collection.query(
query_embeddings=model.encode_text(["一只猫"]).tolist(),
n_results=1
)
按业务维度分库,提升检索效率:
# 按类别创建子集合
client.create_collection(name="movies")
client.create_collection(name="books")
def route_query(query):
if "电影" in query:
return client.get_collection("movies")
else:
return client.get_collection("books")注:本文代码需安装以下依赖:
pip install chromadb sentence-transformers faiss-cpu clip torch
更多AI大模型应用开发学习内容,尽在聚客AI学院。



