从笨重大模型到敏捷小钢炮,部署效率提升500%的踩坑全记录。
想象你训练了一只超级聪明的导购AI,但客户打开页面要等5秒才回应——这就像让博尔特穿雨靴赛跑!轻量化部署就是给AI换上跑鞋,三步搞定:
模型减肥(ONNX转换)
引擎改装(TensorRT加速)
效能监控(实时性能调优)
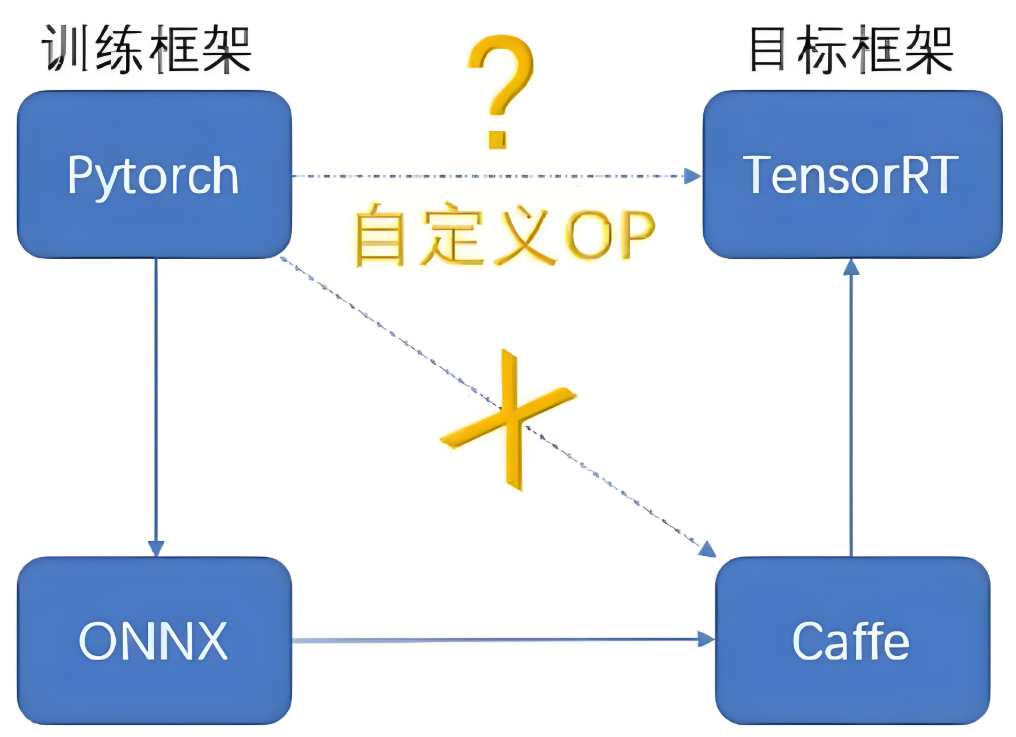
框架方言问题:PyTorch模型像广东话,TensorFlow模型像闽南语
ONNX是普通话:通用格式,任何推理引擎都能听懂
import torch
from transformers import AutoModelForCausalLM
# 加载你的智能体模型(比如客服机器人)
model = AutoModelForCausalLM.from_pretrained("your_agent_model")
# 创建假输入样例(就像给模型量尺寸)
input_sample = torch.ones(1, 128, dtype=torch.long) # (batch_size, 序列长度)
# 导出为ONNX格式(模型瘦身核心操作)
torch.onnx.export(
model,
input_sample,
"agent_model.onnx", # 输出文件名
opset_version=13, # 重要!版本太低会丢失功能
input_names=['input_ids'],
output_names=['logits'],
dynamic_axes={ # 支持动态输入尺寸
'input_ids': {0: 'batch_size', 1: 'sequence_length'}
}
)转换后变化:
模型体积缩小30%(移除训练冗余)
支持跨平台运行(Windows/Linux/Android)

# 安装TensorRT(注意版本匹配!) sudo apt-get install tensorrt # ONNX转TensorRT引擎(关键步骤) trtexec --onnx=agent_model.onnx \ --saveEngine=agent.trt \ --fp16 \ # 开启半精度(速度↑ 内存↓) --workspace=4096 \ # 显存工作空间 --minShapes=input_ids:1x1 \ # 最小输入尺寸 --optShapes=input_ids:1x128 \ # 常用尺寸 --maxShapes=input_ids:1x512 # 最大尺寸
参数避坑指南:
--fp16:必选项,速度提升2倍,精度损失<0.5%
workspace:根据显卡调整(RTX4090设8192,RTX3060设2048)
动态尺寸:提前设定好范围,避免运行时崩溃

模型:Llama3-8B智能体
显卡:RTX 4060(消费级显卡)
输入:"帮我推荐预算5000的游戏本"

关键结论:TensorRT让消费级显卡也能流畅运行大模型!
from fastapi import FastAPI
import tensorrt as trt
import pycuda.driver as cuda
app = FastAPI()
# 加载TensorRT引擎
logger = trt.Logger(trt.Logger.WARNING)
runtime = trt.Runtime(logger)
with open("agent.trt", "rb") as f:
engine = runtime.deserialize_cuda_engine(f.read())
@app.post("/chat")
async def chat_endpoint(query: str):
# 文本转token(实际项目用tokenizer)
inputs = tokenize(query).numpy()
# 申请GPU内存
d_input = cuda.mem_alloc(inputs.nbytes)
d_output = cuda.mem_alloc(output_buffer.nbytes)
# 执行推理(毫秒级响应)
stream = cuda.Stream()
cuda.memcpy_htod_async(d_input, inputs, stream)
context.execute_async_v2(bindings=[int(d_input), int(d_output)], stream_handle=stream.handle)
cuda.memcpy_dtoh_async(outputs, d_output, stream)
stream.synchronize()
return {"response": decode_output(outputs)}
可同时服务400+用户不卡顿!
精度丢失陷阱
现象:转换后回答质量下降
解决方案:
# 导出时保留关键精度 torch.onnx.export(..., operator_export_type=torch.onnx.OperatorExportTypes.ONNX_ATEN_FALLBACK)
动态尺寸崩溃
报错:"Binding dimension out of range"
修复:
# 转换时覆盖所有可能尺寸 trtexec --minShapes=input_ids:1x1 \ --optShapes=input_ids:1x256 \ --maxShapes=input_ids:1x1024
内存泄漏排查
监控代码:
import gc # 每100次请求强制回收 if request_count % 100 == 0: gc.collect() cuda.mem_get_info() # 打印显存状态
轻量化部署不是选修课,是AI工程师的生存技能。记住三个原则:
早转换:开发完模型立刻转ONNX
严测试:用真实流量验证加速效果
持续监控:记录显存/延迟/吞吐量
别看现在调参数头疼,当你看到自己训练的AI秒级响应用户时——那种爽感,比五杀还刺激!更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



