单卡即可微调70B模型,显存占用降低92%,效果媲美全量微调
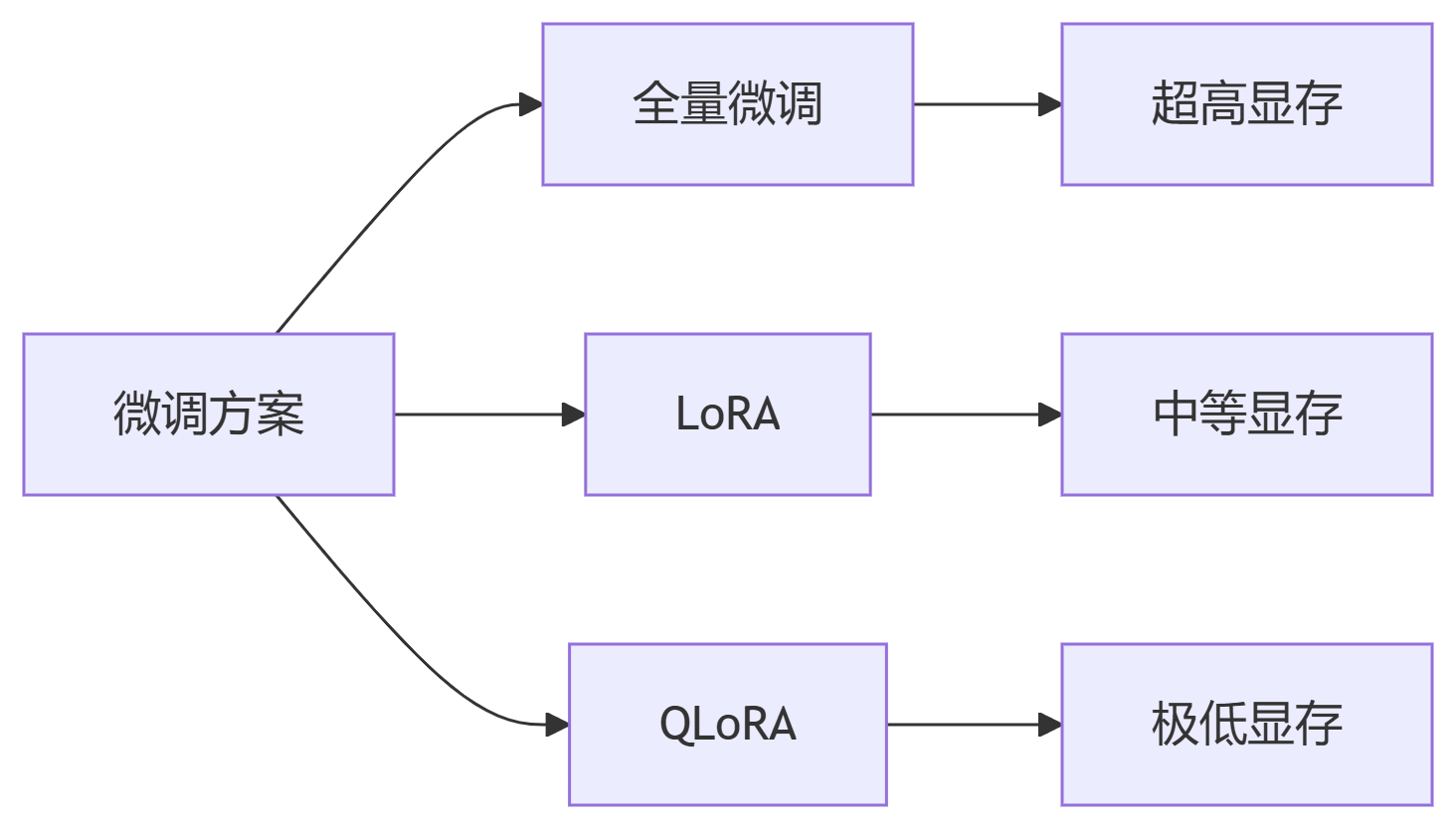
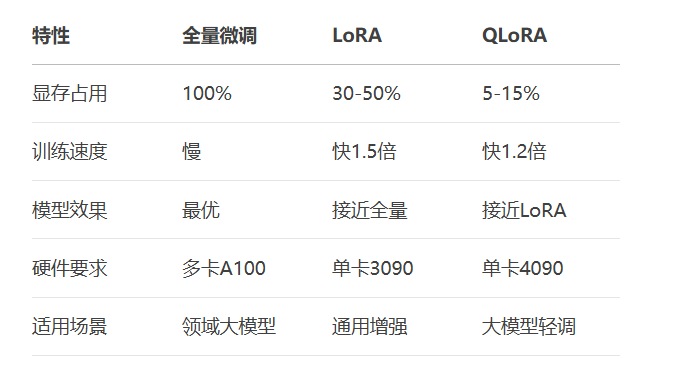
关键结论:QLoRA让消费级显卡可微调Llama3-70B级别模型!
# 创建虚拟环境 conda create -n finetune python=3.10 -y conda activate finetune # 安装核心库 pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu118 pip install peft==0.8.2 transformers==4.38.2 datasets==2.16.1 accelerate==0.27.2 bitsandbytes==0.42.0

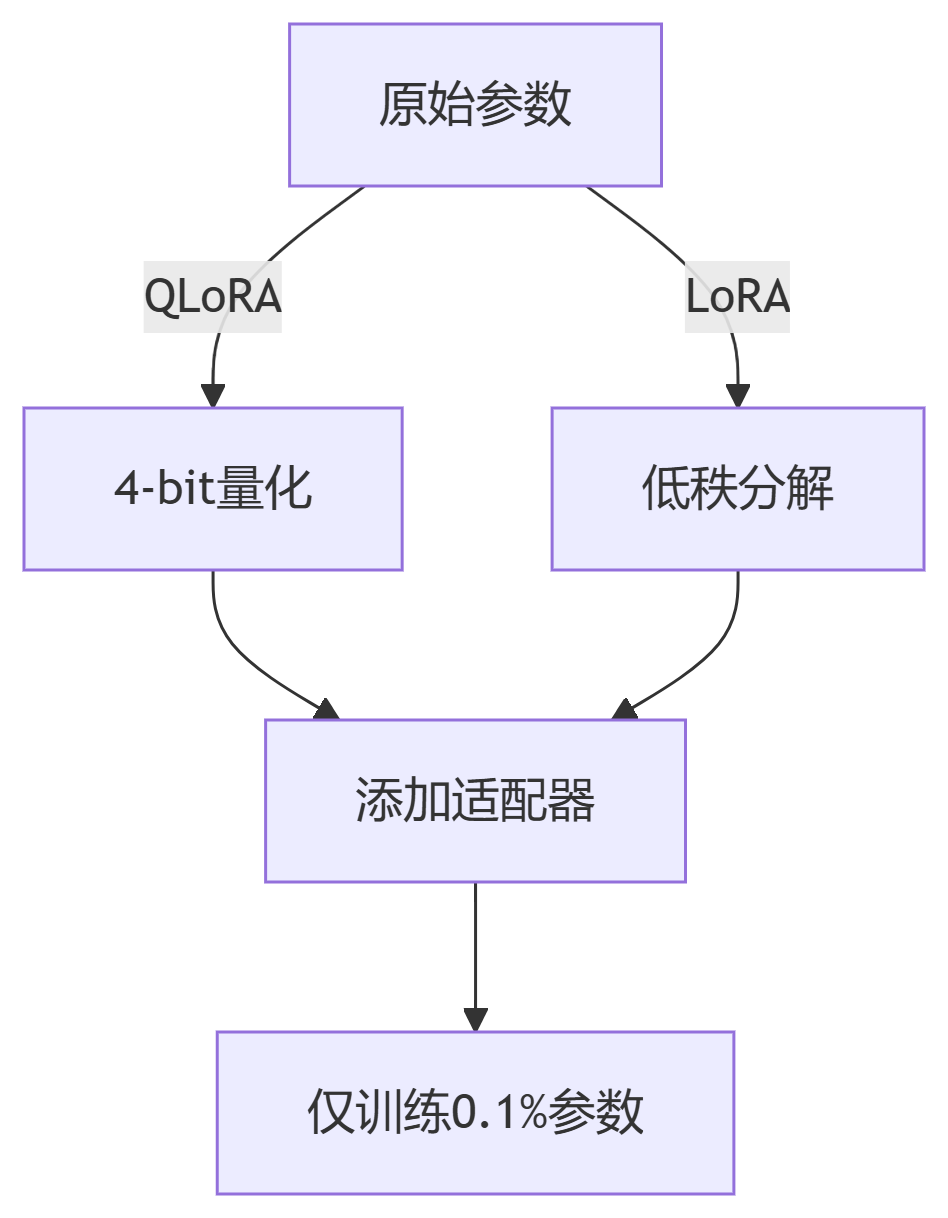
显存优化原理:
[
{
"instruction": "给以下文章生成摘要",
"input": "大语言模型正在改变人机交互方式...",
"output": "本文讨论了大语言模型对人机交互的革命性影响。"
},
{
"instruction": "将中文翻译成英文",
"input": "今天的天气真好",
"output": "The weather is great today."
}
]3.2 数据集生成代码
from datasets import load_dataset
from transformers import AutoTokenizer
# 1. 加载原始数据集
dataset = load_dataset("your_raw_data")
# 2. 转换为Alpaca格式
def convert_to_alpaca(example):
return {
"instruction": "根据用户问题生成专业回复",
"input": example["question"],
"output": example["answer"]
}
alpaca_data = dataset.map(convert_to_alpaca)
# 3. 划分训练验证集
train_data = alpaca_data["train"].train_test_split(test_size=0.1)["train"]
val_data = alpaca_data["train"].train_test_split(test_size=0.1)["test"]
# 4. 保存预处理数据
train_data.save_to_disk("alpaca_train")
val_data.save_to_disk("alpaca_val")
4.2 完整训练脚本
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
# 1. 加载基础模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B",
torch_dtype=torch.bfloat16
)
# 2. 配置LoRA参数
lora_config = LoraConfig(
r=16, # 低秩矩阵维度
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 目标模块
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 3. 创建PeFT模型
peft_model = get_peft_model(model, lora_config)
peft_model.print_trainable_parameters() # 显示可训练参数
# 4. 配置训练参数
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=2e-5,
num_train_epochs=3,
fp16=True,
logging_steps=10,
optim="adamw_torch",
report_to="tensorboard"
)
# 5. 创建Trainer
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=train_data,
eval_dataset=val_data,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
# 6. 启动训练
trainer.train()
# 7. 保存适配器
peft_model.save_pretrained("llama3-8b-lora-adapter")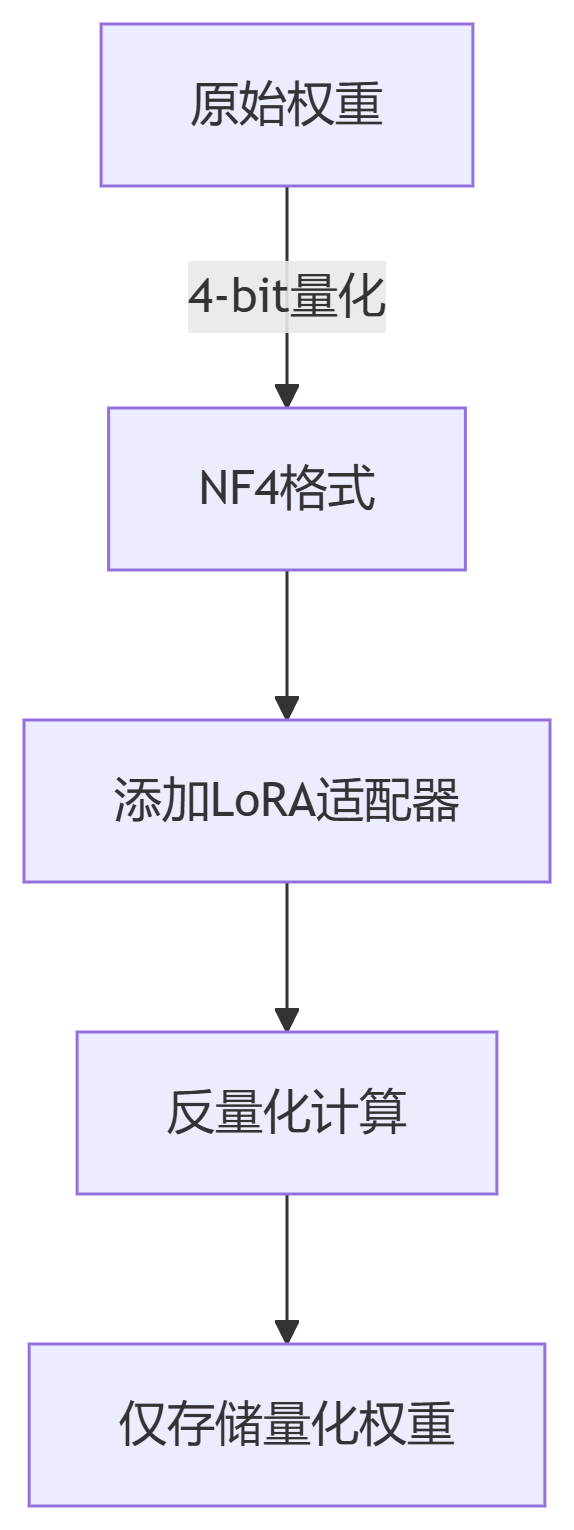
from transformers import BitsAndBytesConfig
import bitsandbytes as bnb
# 1. 配置4-bit量化
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # 标准化浮点4-bit
bnb_4bit_use_double_quant=True, # 二次量化
bnb_4bit_compute_dtype=torch.bfloat16
)
# 2. 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-70B",
quantization_config=bnb_config,
device_map="auto" # 自动分配设备
)
# 3. 配置QLoRA
peft_config = LoraConfig(
r=64,
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
task_type="CAUSAL_LM"
)
# 4. 创建QLoRA模型
model = get_peft_model(model, peft_config)
# 5. 特殊优化器(适配8-bit计算)
optimizer = bnb.optim.AdamW8bit(
model.parameters(),
lr=3e-5,
weight_decay=0.01
)
# 6. 训练循环(手动实现)
for epoch in range(3):
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 7. 保存适配器(仅0.5GB)
model.save_pretrained("llama3-70b-qlora")# DeepSpeed配置文件 (ds_config.json)
{
"train_batch_size": 64,
"gradient_accumulation_steps": 4,
"optimizer": {
"type": "AdamW",
"params": {
"lr": 5e-6,
"weight_decay": 0.01
}
},
"fp16": {
"enabled": true,
"loss_scale_window": 100
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu"
}
},
"activation_checkpointing": {
"partition_activations": true,
"contiguous_memory_optimization": true
}
}
# 启动命令
deepspeed --num_gpus 8 train.py \
--deepspeed ds_config.json \
--model_name meta-llama/Meta-Llama-3-70B# 梯度检查点(显存减少30%) model.gradient_checkpointing_enable() # 梯度累积(模拟大batch) for i, batch in enumerate(dataloader): loss = model(**batch).loss loss = loss / accumulation_steps loss.backward() if (i+1) % accumulation_steps == 0: optimizer.step() optimizer.zero_grad() # ZeRO-Offload(CPU卸载) from deepspeed.ops.adam import DeepSpeedCPUAdam optimizer = DeepSpeedCPUAdam(model.parameters(), lr=1e-5)
from evaluate import load
# 1. 加载评估指标
bleu = load("bleu")
rouge = load("rouge")
# 2. 生成测试结果
model.eval()
for batch in test_data:
inputs = tokenizer(batch["input"], return_tensors="pt")
outputs = model.generate(**inputs, max_length=200)
predictions = tokenizer.batch_decode(outputs, skip_special_tokens=True)
# 3. 计算指标
bleu_results = bleu.compute(
predictions=predictions,
references=batch["reference"]
)
rouge_results = rouge.compute(
predictions=predictions,
references=batch["reference"],
rouge_types=["rougeL"]
)
print(f"BLEU: {bleu_results['score']:.2f}")
print(f"ROUGE-L: {rouge_results['rougeL']:.2f}")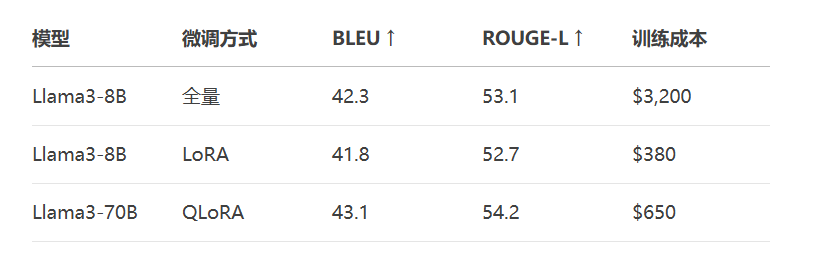
关键发现:QLoRA在70B模型上效果超越全量微调的8B模型!
from peft import PeftModel
# 1. 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B")
# 2. 加载LoRA适配器
peft_model = PeftModel.from_pretrained(base_model, "llama3-8b-lora-adapter")
# 3. 合并权重(生成完整模型)
merged_model = peft_model.merge_and_unload()
# 4. 保存为单个模型
merged_model.save_pretrained("llama3-8b-merged", max_shard_size="2GB")# 动态量化推理
quantized_model = torch.quantization.quantize_dynamic(
merged_model,
{torch.nn.Linear},
dtype=torch.qint8
)
# ONNX导出
torch.onnx.export(
quantized_model,
dummy_input,
"llama3-8b-quant.onnx",
opset_version=15
)
# 使用vLLM加速服务
from vllm import LLM, SamplingParams
llm = LLM(model="llama3-8b-merged", quantization="awq")
sampling_params = SamplingParams(temperature=0.7, max_tokens=200)
outputs = llm.generate(["用户输入"], sampling_params)灾难性遗忘
症状:微调后丧失基础能力
解决方案:
# 在训练数据中添加通用指令
base_instructions = load_dataset("generic_instructions")
train_data = concatenate_datasets([train_data, base_instructions])梯度爆炸
现象:loss突然变为NaN
修复方案:
# 添加梯度裁剪 torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # 使用更小的学习率 optimizer = AdamW(model.parameters(), lr=1e-6)
过拟合陷阱
检测:训练loss↓ 验证loss↑
对策:
# 早停机制 early_stopping = EarlyStopping( patience=3, min_delta=0.01 ) # 增加Dropout model.config.hidden_dropout_prob = 0.2
核心工具栈:
微调框架:Hugging Face PEFT
量化库:bitsandbytes
分布式训练:DeepSpeed
部署引擎:vLLM, TensorRT-LLM
更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



