Miniconda环境(推荐):
conda create -n langchain python=3.10 conda activate langchain pip install langchain langchain-core langchain-community langchain-openai
Docker快速部署:
FROM python:3.10-slim RUN pip install langchain[all] EXPOSE 8000 CMD ["langchain", "serve"]
IDE配置建议:
VSCode插件:Python, Jupyter, LangChain Snippets
调试配置:
{
"version": "0.2.0",
"configurations": [
{
"name": "LangChain Debug",
"type": "python",
"request": "launch",
"module": "langchain",
"args": ["run", "--port", "8000"]
}
]
}多模型统一接口:
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
models = {
"gpt-4": ChatOpenAI(model="gpt-4-turbo"),
"claude-3": ChatAnthropic(model="claude-3-opus")
}
def process_input(user_input, model_type):
message = HumanMessage(content=user_input)
return models[model_type].invoke([message]).content
print(process_input("解释量子纠缠", "claude-3"))混合数据加载器:
from langchain_community.document_loaders import (
PyMuPDFLoader,
WebBaseLoader,
CSVLoader
)
loaders = {
"pdf": PyMuPDFLoader("report.pdf"),
"web": WebBaseLoader(["https://example.com"]),
"csv": CSVLoader("data.csv")
}
multimodal_docs = []
for loader in loaders.values():
multimodal_docs.extend(loader.load())多模态嵌入:
from langchain.embeddings import (
OpenAIEmbeddings,
HuggingFaceBgeEmbeddings
)
embeddings = {
"text": HuggingFaceBgeEmbeddings(model_name="BAAI/bge-large-en"),
"image": OpenAIEmbeddings(model="clip-vit-base-patch32")
}智能分块策略:
from langchain.text_splitter import ( RecursiveCharacterTextSplitter, SemanticChunker ) class HybridSplitter: def __init__(self): self.recursive_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=64 ) self.semantic_splitter = SemanticChunker(OpenAIEmbeddings()) def split(self, text): if len(text) < 5000: return self.recursive_splitter.split_text(text) else: return self.semantic_splitter.split_text(text)
混合索引架构:
from langchain.vectorstores import Chroma, FAISS
from langchain.retrievers import EnsembleRetriever
vectorstore = Chroma.from_documents(docs, embeddings["text"])
keyword_retriever = TFIDFRetriever.from_documents(docs)
ensemble_retriever = EnsembleRetriever(
retrievers=[
vectorstore.as_retriever(search_kwargs={"k": 5}),
keyword_retriever
],
weights=[0.7, 0.3]
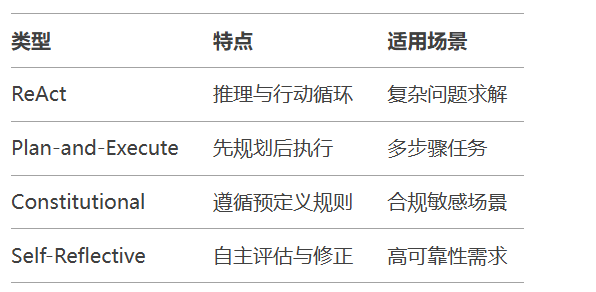
)智能体类型矩阵:
ReAct智能体示例:
from langchain.agents import AgentExecutor, create_react_agent
from langchain import hub
prompt = hub.pull("hwchase17/react")
tools = [
Tool(name="Search", func=search_api),
Tool(name="Calculate", func=calculator)
]
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
result = agent_executor.invoke({
"input": "特斯拉当前股价是多少?如果我有1000股现在卖出能获得多少?"
})供应链管理案例:
from langgraph.graph import StateGraph
class SupplyChainState(TypedDict):
inventory: dict
orders: list
def check_inventory(state):
# 库存检查逻辑
return {"inventory": updated_inventory}
def process_order(state):
# 订单处理逻辑
return {"orders": processed_orders}
workflow = StateGraph(SupplyChainState)
workflow.add_node("check_inventory", check_inventory)
workflow.add_node("process_order", process_order)
workflow.add_edge("check_inventory", "process_order")
workflow.set_entry_point("check_inventory")
app = workflow.compile()
app.invoke(initial_state)监控看板搭建:
from langsmith import Client
from langchain.callbacks.tracers import LangChainTracer
client = Client(api_url="https://api.langchain.com")
tracer = LangChainTracer(project_name="supply-chain")
# 在Agent执行时添加监控
agent_executor.invoke(
{"input": "..."},
config={"callbacks": [tracer]}
)关键监控指标:
响应延迟分布
Token消耗统计
工具调用成功率
知识检索相关性评分
# .github/workflows/langchain-ci.yml
name: LangChain CI
on: [push]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: 3.10
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run tests
run: pytest tests/
- name: LangSmith Evaluation
env:
LANGSMITH_API_KEY: ${{ secrets.LANGSMITH_API_KEY }}
run: langsmith test run --project supply-chain三个阶段演进路线:
基础阶段:单链式流程开发
进阶阶段:分布式智能体系统
专家阶段:自适应认知架构
graph LR A[掌握基础组件] --> B[构建简单RAG] A --> C[开发单功能Agent] B --> D[实现混合检索系统] C --> D D --> E[设计复杂工作流] E --> F[构建自适应认知架构]
掌握LangChain全栈开发需要持续实践,更多AI大模型应开发学习内容,尽在聚客AI学院。



