发展脉络:BERT(双向编码)→ GPT(自回归生成)→ T5(编码-解码统一)→ MoE(混合专家)
核心架构:
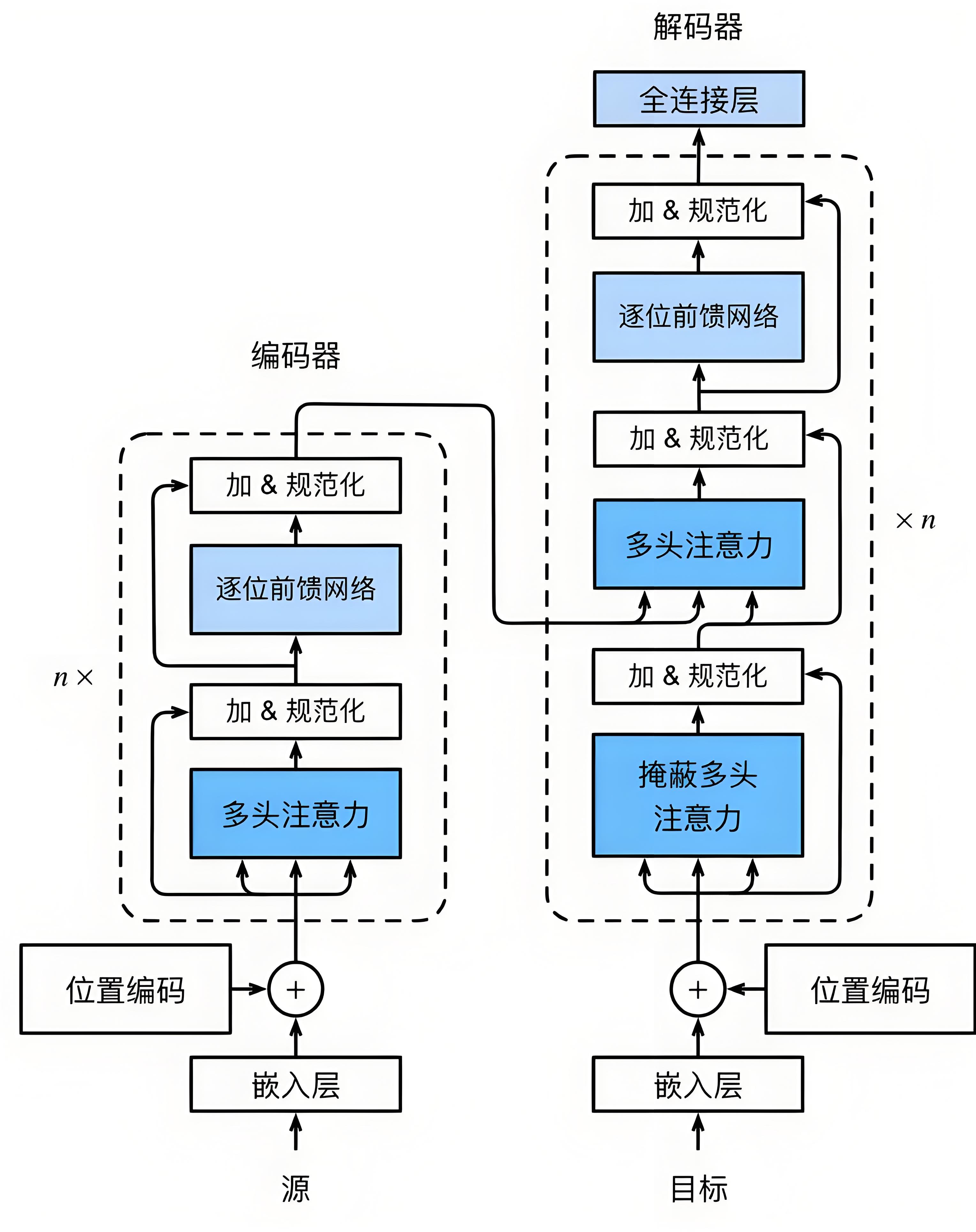
Transformer:基于自注意力机制,解决长距离依赖问题
稀疏模型:如Mixtral-8x7B,动态激活专家层降低计算成本
大模型发展史:
import torch # 创建张量并启用GPU加速 tensor_a = torch.tensor([[1, 2], [3, 4]], device='cuda') # 显存存储 tensor_b = torch.randn(2, 2).cuda() # 随机张量移至GPU # 常见计算 result = torch.matmul(tensor_a, tensor_b) # 矩阵乘法 result = tensor_a @ tensor_b.T # 等价写法(转置后乘)
x = torch.tensor(3.0, requires_grad=True) y = x**2 + 2*x + 1 y.backward() # 自动计算梯度 print(x.grad) # 输出:8.0 (dy/dx = 2x+2)
关键点:requires_grad=True 开启追踪计算图,backward() 反向传播求导。
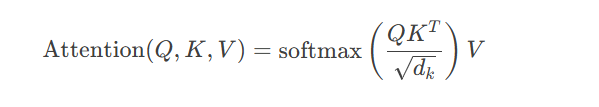

示例:传统NER需训练独立模型,而大模型通过Few-Shot提示即可实现:“文本:马云曾任阿里巴巴CEO。抽取实体:__” → 模型输出:{"人物": "马云", "公司": "阿里巴巴"}
CUDA核心:万级并行线程处理矩阵运算
显存带宽:HBM3显存提供>1TB/s带宽,避免数据瓶颈
优化技术:
FlashAttention-3:减少注意力计算显存占用
量化推理:FP8精度提速2倍(如DeepSeek-R1部署)
import torch.distributed as dist from torch.nn.parallel import DistributedDataParallel as DDP # 初始化多进程组 dist.init_process_group(backend='nccl') model = DDP(model.cuda(), device_ids=[local_rank]) # 数据并行训练 for batch in data_loader: outputs = model(batch) loss = outputs.loss loss.backward()
# 安装PyTorch(CUDA 12.1版本) pip install torch torchvision torchaudio --index-url https://pypi.tuna.tsinghua.edu.cn/simple
from torch.utils.data import Dataset, DataLoader
class TextDataset(Dataset):
def __init__(self, texts, labels):
self.texts = texts
self.labels = labels
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
return {"input": self.texts[idx], "label": self.labels[idx]}
# 实例化并分批次加载
dataset = TextDataset(["text1", "text2"], [0, 1])
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)import torch.optim as optim
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
optimizer = optim.AdamW(model.parameters(), lr=5e-5)
for epoch in range(3):
for batch in dataloader:
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 保存模型
torch.save(model.state_dict(), "model.pt")# 加载微调后的模型
model.load_state_dict(torch.load("model.pt"))
model.eval() # 切换为评估模式
# 执行预测
input_text = "这个产品体验非常好"
inputs = tokenizer(input_text, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
prediction = torch.argmax(logits, dim=1).item() # 输出分类结果from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
# 构建向量数据库
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-base-zh")
vector_db = Chroma.from_documents(docs, embeddings)
# 检索增强生成
retriever = vector_db.as_retriever()
results = retriever.invoke("量子计算原理")from langchain.agents import Tool, initialize_agent
tools = [
Tool(name="WebSearch", func=duckduckgo_search.run, description="搜索引擎"),
Tool(name="Calculator", func=math_calculator, description="数学计算")
]
agent = initialize_agent(tools, llm, agent_type="structured_chat")
agent.run("特斯拉当前股价是多少?2023年营收增长率是多少?")避坑提示:
张量计算时统一设备(CPU/GPU)避免 RuntimeError
训练前开启 torch.backends.cudnn.benchmark = True 加速卷积运算
多卡训练时用 NCCL 后端(NVIDIA显卡)或 GLOO(AMD显卡)
更多AI大模型应用学习视频内容和资料,尽在聚客AI学院。



