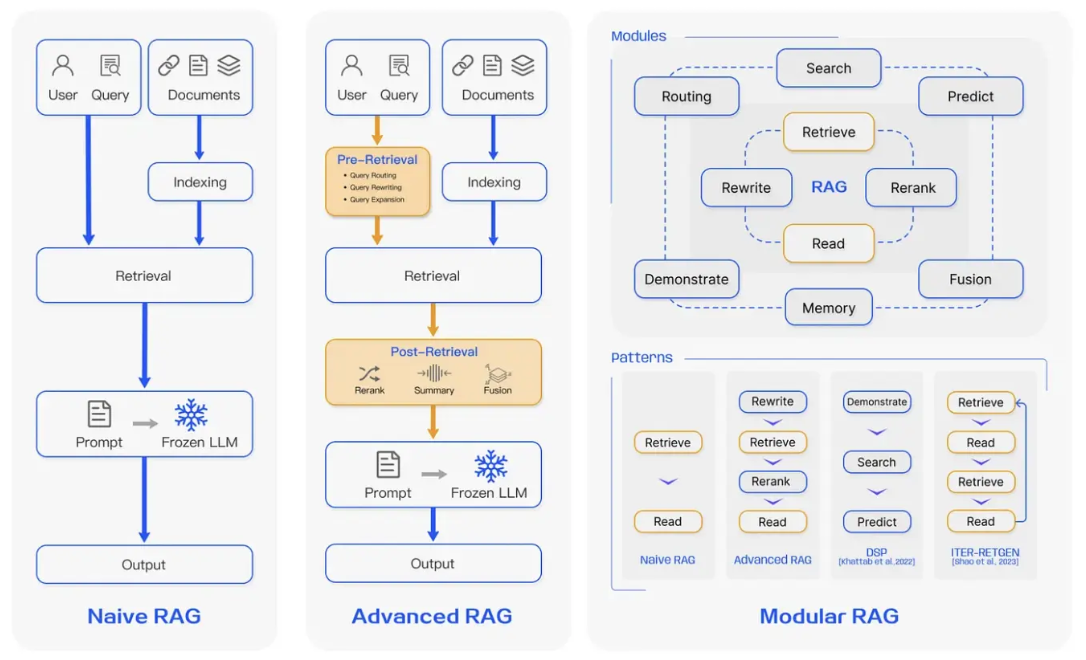
技术内核:检索增强生成(RAG)技术
核心组件:
向量数据库(ChromaDB/Pinecone)
混合检索器(BM25+Embedding)
重排序模型(BAAI/bge-reranker-large)
工业级案例:
法律智能助手:
连接2000万条法律条文数据库
支持法条多维度检索(时间效力、地域适用)
响应延迟<300ms(90%分位)
from langchain.retrievers import EnsembleRetriever # 混合检索器构建 bm25_retriever = BM25Retriever.from_documents(docs) vector_retriever = FAISS.as_retriever() ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, vector_retriever], weights=[0.4, 0.6] )
架构设计:
[感知层] → [规划器] → [工具调用] → [验证器] → [执行器]
关键技术:
反射机制:通过Critic模块评估行动合理性
工具注册中心:动态加载API/数据库/SDK
记忆压缩:采用Token节约策略存储对话历史
实战案例:
电商客服智能体:
自主完成订单查询→物流追踪→退换货处理全流程
复杂问题解决率提升65%(对比传统规则引擎)
技术挑战:
原子性保障:分布式事务一致性
长流程管理:多步骤操作状态跟踪
解决方案:
事务补偿机制:
@transactional def purchase_flow(user_id, item_id): try: lock_inventory(item_id) # 步骤1:库存锁定 deduct_balance(user_id) # 步骤2:扣款 generate_order() # 步骤3:生成订单 except Exception as e: rollback_inventory(item_id) # 补偿操作 refund_balance(user_id)
流程引擎:采用Temporal.io实现分布式工作流
关键技术栈:
时序预测:Prophet+Transformer混合模型
归因分析:SHAP值可视化
仿真系统:基于Ray的并行计算框架
金融风控案例:
输入:用户交易流水(10万条/秒)
处理流程:
异常模式检测(LSTM-Autoencoder)
风险评分(XGBoost+专家规则)
处置建议生成(GPT-4微调模型)
成效:坏账率降低23%,人工审核量减少80%
技术突破点:
认知架构升级:
MetaGPT:实现类人思维链(CODEX架构)
AutoGen:支持多智能体协作竞争
记忆管理革新:
向量记忆压缩(信息熵保持率>92%)
事件图谱构建(Neo4j知识图谱集成)
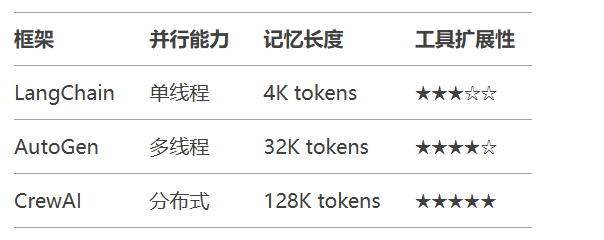
开发框架对比:
方法论体系:
结构化模板:
[角色设定]
你是一位资深{行业}专家,擅长{技能}
[任务目标]
完成{具体任务},要求{质量标准}
[输出规范]
采用{格式},包含{要素},长度限制{字数}动态优化策略:
CoT-SC(思维链自洽校验)
ToT(树状推理优化)
实战技巧:
温度值动态调整:
创意生成:temperature=0.7-1.0
事实回答:temperature=0.1-0.3
停止序列设计:
代码生成:设置\n为停止符防止多余注释
参数高效微调(PEFT)技术矩阵:

LoRA变体:
QLoRA:4-bit量化微调(GPU显存节省70%)
DoRA:方向秩适配(效果提升15%)
混合策略:
底层参数:LoRA
注意力层:Adapter
输出层:全量微调
代码实战:
from peft import LoraConfig, get_peft_model config = LoraConfig( r=32, lora_alpha=64, target_modules=["q_proj", "v_proj"], lora_dropout=0.1, bias="lora_only" ) model = get_peft_model(model, config)
工业化处理流水线:
原始数据 → 清洗 → 分块 → 向量化 → 索引 → 版本管理
关键技术突破:
自适应分块:
文本:滑动窗口(512 tokens) + 重叠(64 tokens)
代码:AST语法树分块
混合编码模型:
BGE-M3:支持密集检索、稀疏检索、多向量检索
性能优化:
量化索引:PQ(Product Quantization)压缩
分布式集群:Milvus 2.0横向扩展方案
多模态数据获取体系:
合规采集:
Common Crawl过滤(清洗率99.8%)
合成数据生成(LLM-as-a-Judge)
质量评估:
困惑度检测(PPL<20)
毒性评分(Perspective API)
数据增强技术:
文本:回译(中→英→中)
代码:AST扰动(变量重命名/控制流变换)
图像:Diffusion重渲染
架构演进路线:
Transformer → Mixture of Experts → Hybird Architecture
关键创新:
FlashAttention-2:训练速度提升45%
Ring Attention:突破百万token上下文限制
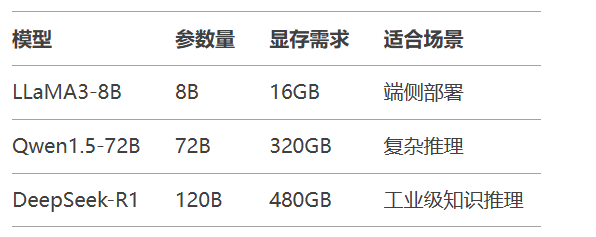
选型指南:
创新架构:
QFormer:桥接文本与视觉特征的查询转换器
动态分辨率处理:
低分辨率:快速物体检测
高分辨率:细粒度特征提取
医疗影像案例:
输入:CT扫描序列(2000张切片)
处理流程:
3D卷积特征提取
跨模态对齐(文本报告→影像特征)
病理诊断生成(敏感度92%)
工业级优化技术:
层次化注意力:
词级→句级→文档级注意力
领域适配器:
法律/医疗/金融领域专用适配层
关键技术指标:
合同解析准确率:98.7%(CUAD数据集)
事件抽取F1值:91.2%(ACE2005基准)
创新架构:SAM(Segment Anything Model)
技术突破:
提示引擎:支持点/框/文本提示
掩码解码器:实时生成高质量分割结果
工业应用:
卫星图像分析:
建筑物识别精度:94%
灾害评估响应时间:<3分钟



