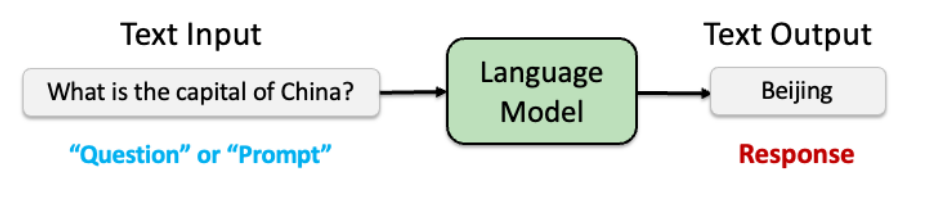
语言模型(Language Models, LMs)是预测序列数据(如文本)概率分布的数学模型。其核心任务是给定前文预测下一个词的概率。
1.1 大型语言模型(LLMs)
LLMs是参数量超过亿级的语言模型,通过海量数据预训练获得通用语言理解能力。例如,GPT-3(1750亿参数)能够生成连贯文本、翻译语言甚至编写代码。
1.2 自回归语言模型
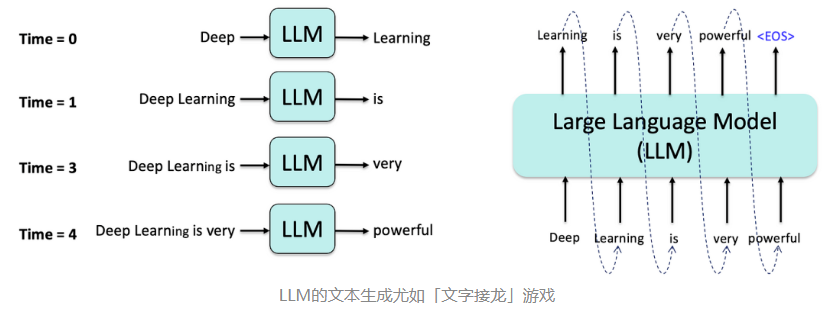
自回归模型(如GPT系列)通过从左到右逐个生成词来构建文本,其核心公式为:
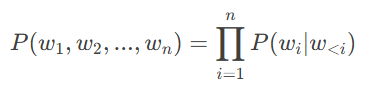
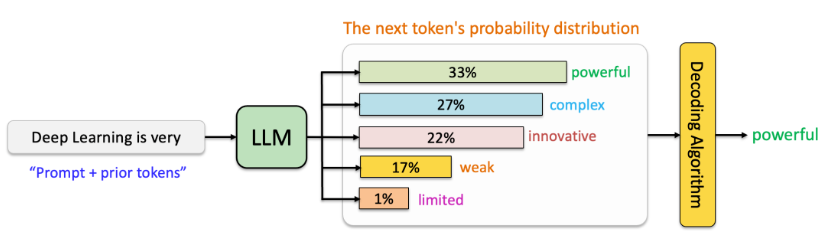
这种生成方式使其在文本生成任务中表现卓越。
1.3 生成能力
LLMs的生成能力不仅限于文本,还可用于代码生成、图像描述等任务。例如,GPT-4能生成符合逻辑的编程解决方案,而DeepSeek-R1在数学推理任务中准确率超过97%。
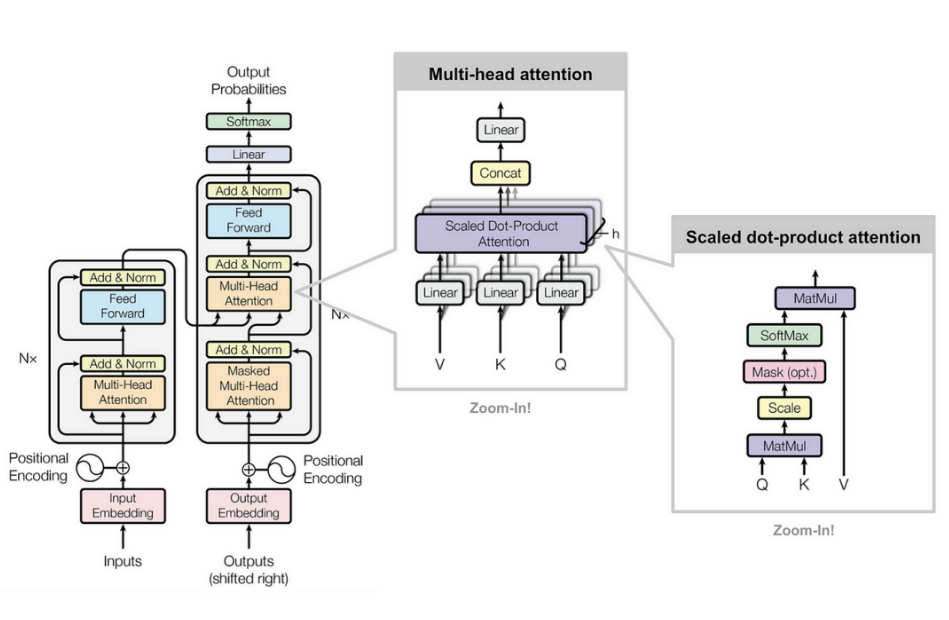
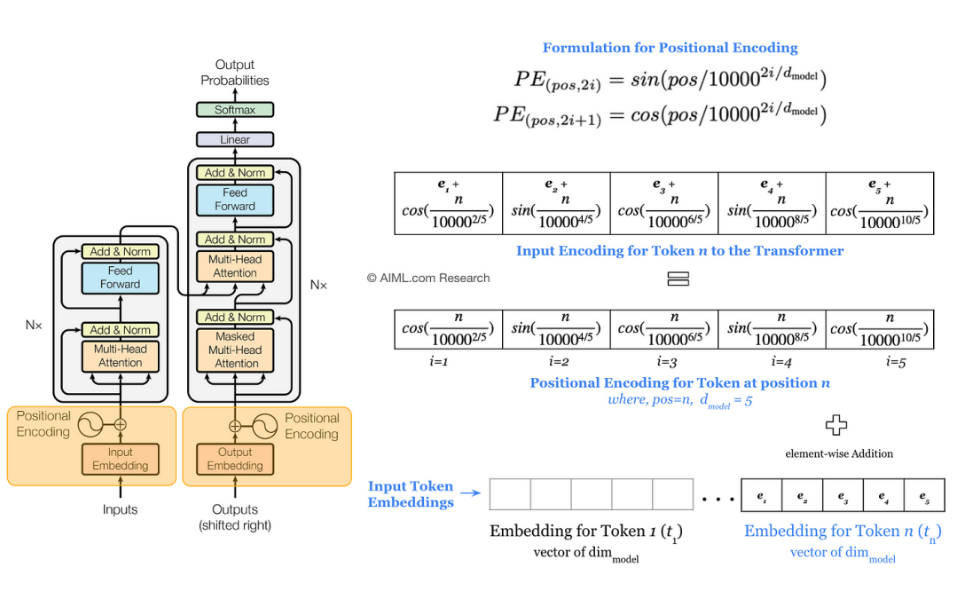
2.1 Transformer架构的关键创新
自注意力机制:动态计算词与词之间的关系权重,替代RNN的序列处理限制。
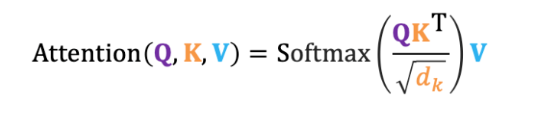
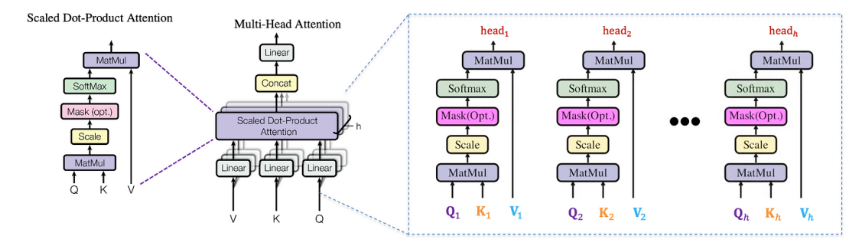
多头注意力:并行多组注意力头,捕获不同层次的语义关联。
位置编码:引入位置信息,解决序列无序性问题。
Transformer的提出(论文《Attention Is All You Need》)彻底改变了NLP领域,成为后续所有大模型的基础架构。
3.1 BERT:双向上下文理解 (2018)
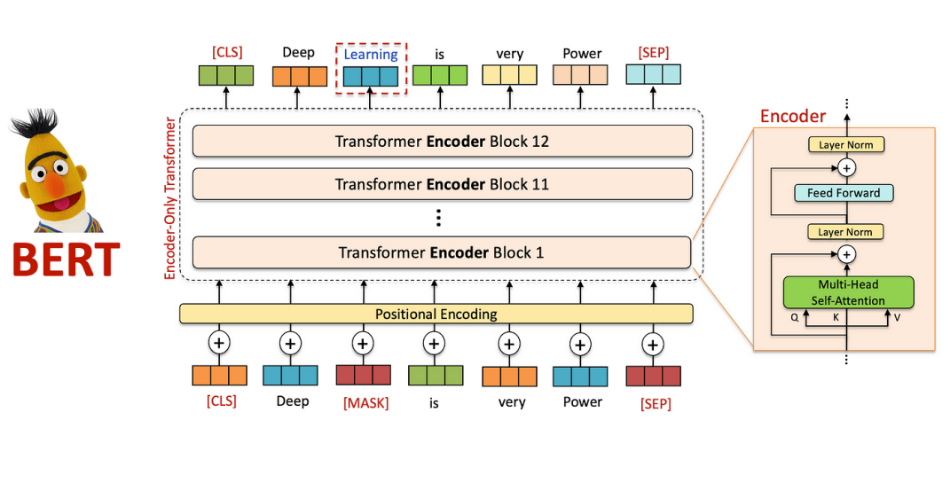
BERT通过掩码语言模型(MLM)和下一句预测(NSP)任务,实现双向上下文建模。例如,在问答任务中,BERT能结合前后文理解问题意图。
3.2 GPT:生成式预训练和自回归文本生成(2018–2020)
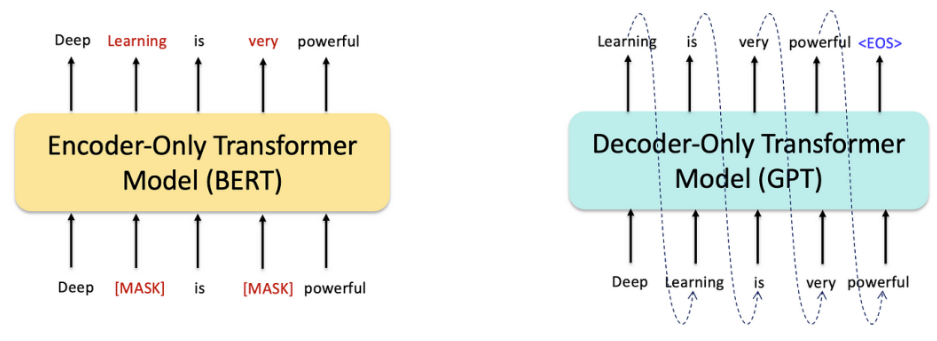
GPT系列采用自回归预训练,逐步扩展模型规模:
GPT-1(1.1亿参数):首次验证生成式预训练的有效性。
GPT-2(15亿参数):展示零样本学习能力。
GPT-3(1750亿参数):通过Few-shot提示实现多任务泛化。
3.3 规模的作用
模型参数量与数据量的指数级增长(如GPT-3的训练数据达45TB)显著提升了模型的涌现能力,例如逻辑推理和跨领域知识迁移
4.1 监督微调 (SFT)
通过标注数据微调模型输出格式,例如将GPT-3调整为遵循指令的InstructGPT。
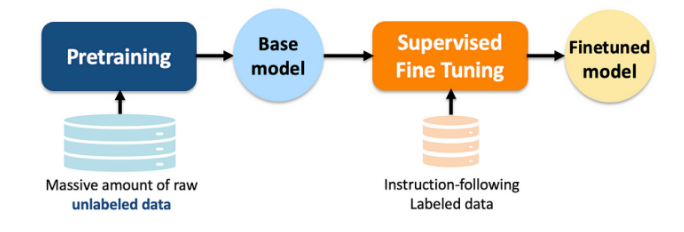
4.2 基于人类反馈的强化学习 (RLHF)
引入奖励模型(Reward Model)和PPO算法,优化生成内容的人类偏好对齐。例如,ChatGPT通过RLHF减少有害输出。
4.3 ChatGPT:推进对话式AI (2022)
ChatGPT结合SFT和RLHF,实现流畅的对话交互,用户仅需自然语言指令即可完成代码生成、文案创作等任务
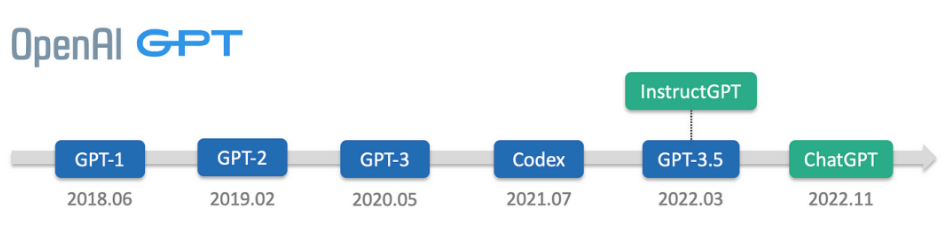

5.1 GPT-4V:视觉遇见语言
GPT-4V支持图像输入与文本生成,例如分析医学影像并生成诊断报告。
5.2 GPT-4o:全模态前沿
整合文本、语音、图像的多模态交互能力,例如实时视频对话中同步解析用户表情与语音内容
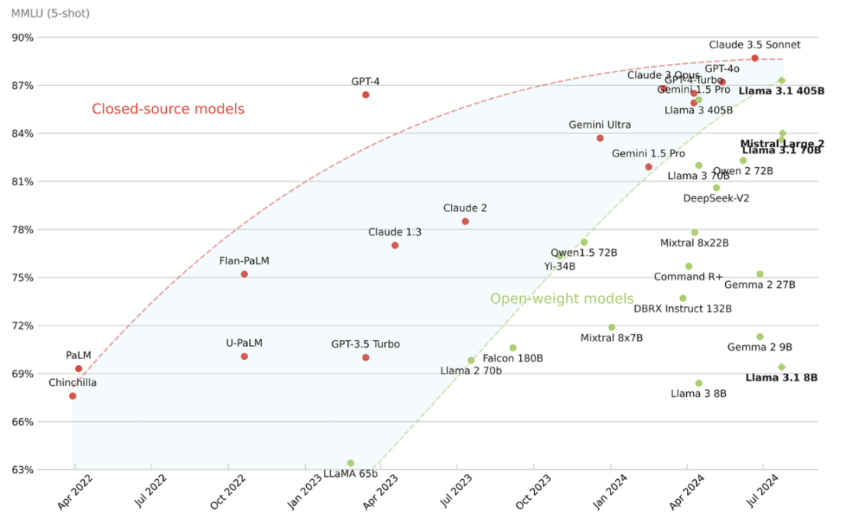
开源社区推动技术民主化:
Llama系列:Meta开源的7B至70B参数模型,支持商业化微调。
Qwen/Baichuan:中文开源模型,适配本地化场景。
开源框架(如Hugging Face Transformers)降低了开发者门槛,加速行业应用落地。
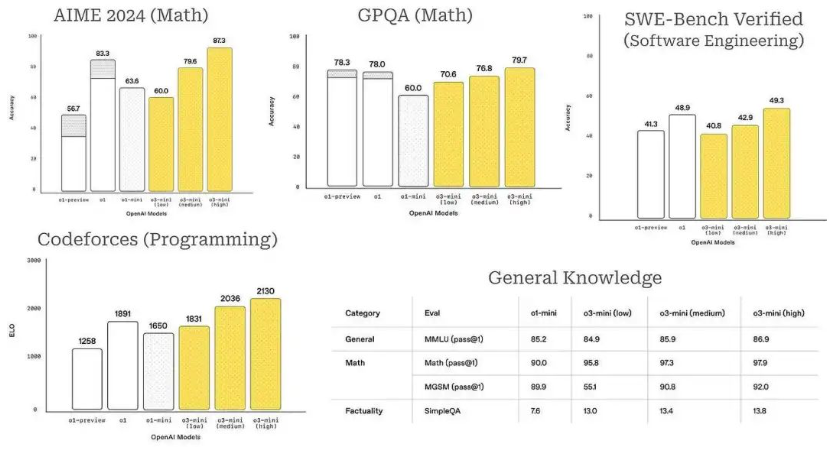
7.1 OpenAI-o1:推理能力的一大飞跃(2024)
OpenAI-o1通过思维链(Chain-of-Thought)和自省机制,显著提升复杂数学问题求解能力。例如,在MATH数据集上准确率提升至89%。
8.1 DeepSeek-V3 (2024–12)
采用混合专家(MoE)架构,动态分配计算资源,推理效率提升3倍。
8.2 DeepSeek-R1-Zero 和 DeepSeek-R1 (2025–01)
R1-Zero:蒸馏小模型,支持笔记本电脑端部署。
R1:强化学习优化,在数学推理任务中准确率达97.3%,API成本仅为同类模型的1/30。
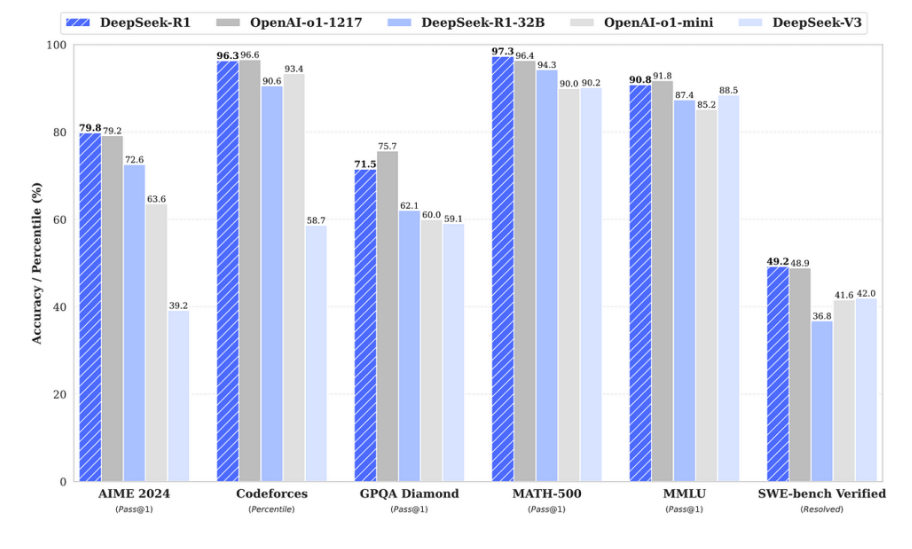
8.3 对AI行业的影响
端侧部署:R1-Zero推动智能座舱、移动设备AI普及。
行业应用:医疗文献解析、代码生成效率提升40%
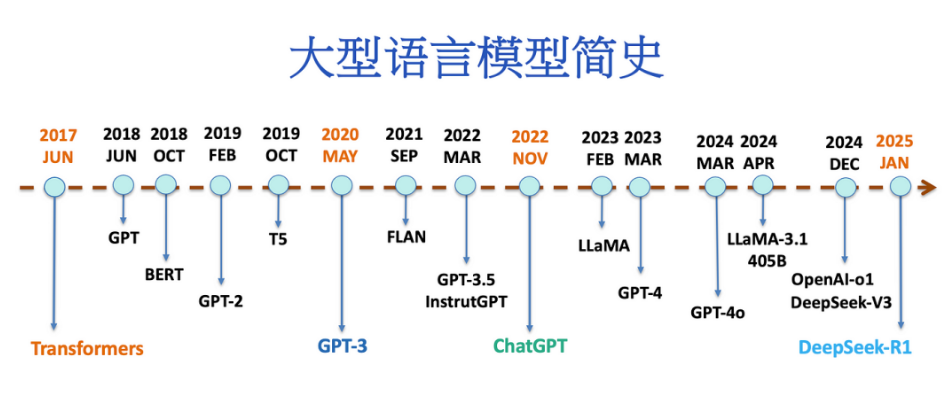
从Transformer到DeepSeek-R1,大模型技术经历了架构革新、规模扩展、多模态融合和推理优化的四次跃迁。DeepSeek-R1通过成本效率和技术突破,标志着AI从实验室走向产业落地的成熟阶段。未来,模型的小型化、多模态与伦理对齐将是关键方向。开发者需掌握微调(如LoRA)、推理加速(如vLLM)等核心技术,以应对快速演进的技术浪潮。



