在2023年之前,RAG(检索增强生成)的核心技术——检索增强(Retrieval-Augmented)已在智能问答系统中广泛应用,但直到大模型(LLM)的爆发式增长,RAG才真正成为企业级AI落地的核心范式。2024年,随着技术细节的深度优化与行业需求的碰撞,RAG技术逐渐从“架构探索”转向“工程化实践”,并在知识管理、企业服务等领域展现出不可替代的价值。本文将结合一线实战经验,拆解RAG技术的核心变化与落地策略。
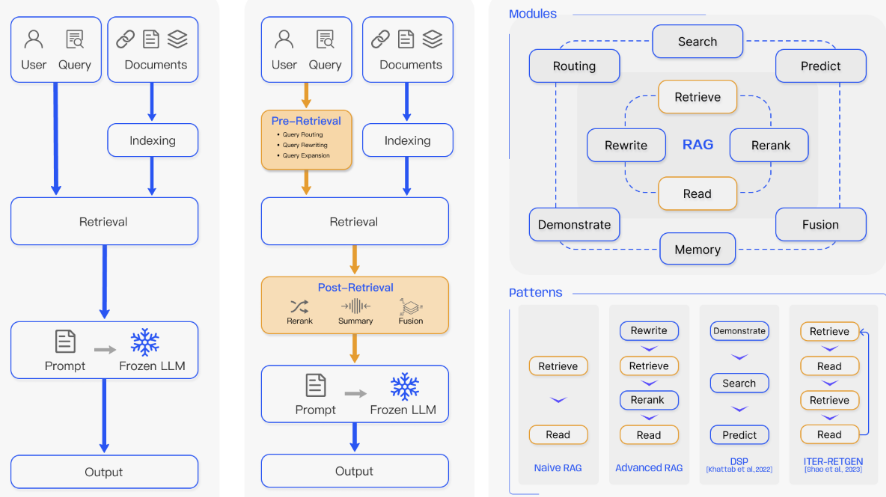
在RAG的架构选择中,2024年的主流已从早期的“Naive RAG”转向“Advanced RAG”,其核心优势在于效果与成本的平衡:
Naive RAG:简单的“检索-生成”管道,依赖LLM的上下文窗口直接处理原始文档,但存在检索精度低、幻觉风险高的问题。
Advanced RAG:引入预处理(如元数据标注、指代消解)和后处理(如重排序Rerank),通过多阶段优化提升准确率。例如,在TorchV AI系统中,通过元数据过滤+混合检索,将客户问题的解决率提升了30%以上。
Modular RAG:模块化设计(如动态路由、多路召回)虽理论上更灵活,但开发与维护成本陡增,目前仅适用于头部企业的定制化场景。
核心结论:Advanced RAG的普适性源于其“对症下药”的特性——通过轻量级改造(如元数据增强)快速适配客户需求,而非追求复杂的“全家桶”方案。
痛点演变:早期RAG处理标准PDF/HTML文档时问题较少,但2024年行业需求推动下,非结构化数据(如扫描件、老旧Office文件)的解析成为瓶颈。
技术突破:
垂直工具崛起:合合信息(科创板上市)的OCR技术、百度PaddleOCR的开源方案,以及新兴企业SoMark的智能解析工具,解决了复杂表格、合并单元格等难题。
流程前置化尝试:探索通过知识生产工具(如协作平台)直接生成结构化知识,减少后期解析成本。例如,TorchV AI正在研发的“知识编辑器”,允许用户直接标注实体关系,生成带元数据的知识库。
Chunking的本质:并非“切割越细越好”,而是需结合LLM上下文窗口灵活调整。例如,对于5页以内的文档,可直接整篇输入GPT-4 Turbo(128k窗口)。
两大隐藏技巧:
指代消解:通过Chunk叠加或动态附加元数据(如合同中的“甲方/乙方全称”),解决跨段落指代问题。
元数据激活策略:在TorchV AI系统中,通过NLU(自然语言理解)提取用户意图,仅当匹配预设的“系统槽位”(如时间、地点)时,才触发元数据过滤,避免无效检索。
Graph数据库的争议:虽然Neo4j等图数据库在关联分析上有优势,但非结构化数据转换成本过高,目前仅建议特定场景(如法律条款关联)使用。
Hybrid检索的必然性:BM25(稀疏检索)与语义检索(如HNSW算法)的组合已成标配。BM25擅长精确匹配(如产品型号),而语义检索可捕捉用户意图的泛化表达。
RRF融合与重排序优化:
RRF公式:通过倒数排序融合(RRF)整合多路检索结果,兼顾召回率与相关性。
重排序(Rerank)的价值:对Top结果进行二次精排(如归一化处理),可将准确率提升15%-20%。但需注意,Rerank是“被动优化”,而元数据过滤是“主动提效”,后者优先级更高。
知识生产工具化:通过协作平台直接生成结构化知识,减少解析成本(如TorchV的“知识编辑器”原型)。
多模态RAG崛起:从纯文本向图像、音视频扩展,需解决跨模态检索与生成的一致性难题。
成本敏感型架构:针对中小企业,推出轻量化检索方案(如基于SQLite的嵌入式向量库)。
2024年的RAG技术演进,印证了一个朴素真理:没有“银弹”架构,只有“适配”方案。无论是元数据策略还是混合检索,核心目标始终是提升客户问题的解决率。随着Scaling Law瓶颈的显现,RAG或将成为未来3-5年企业级AI落地的核心支柱。从业者需摒弃“技术炫技”思维,回归需求本质——用最低成本解决最多问题。



