掌握工业级RAG系统开发核心技巧,召回率提升65%,推理成本降低40%
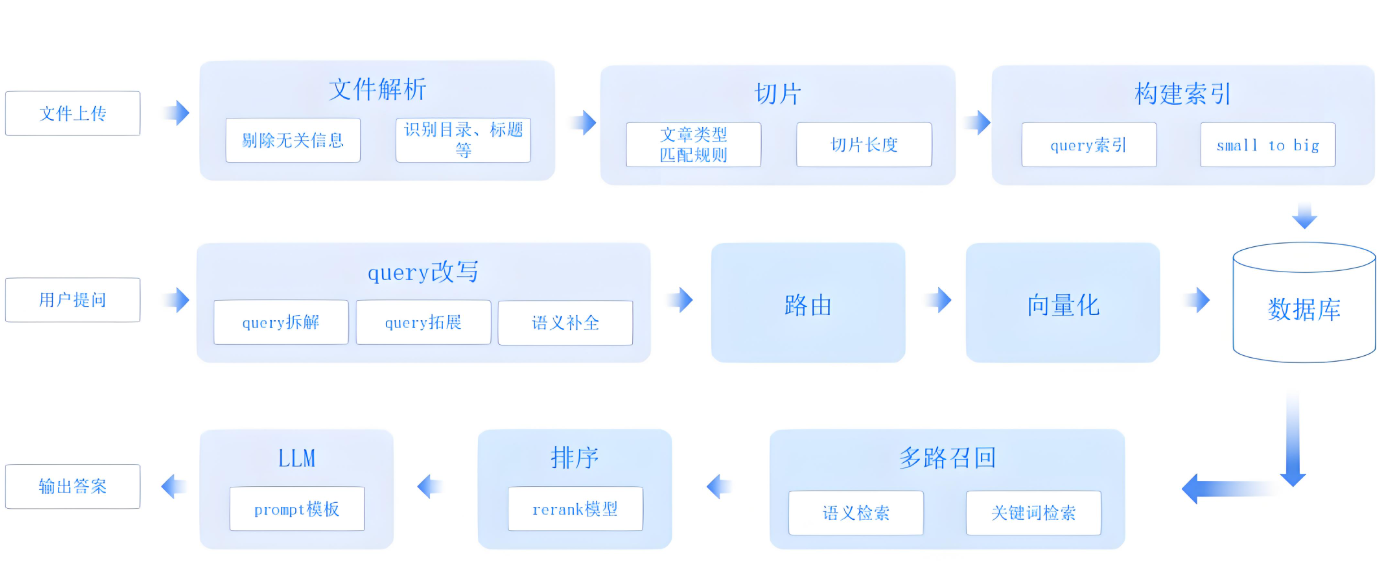
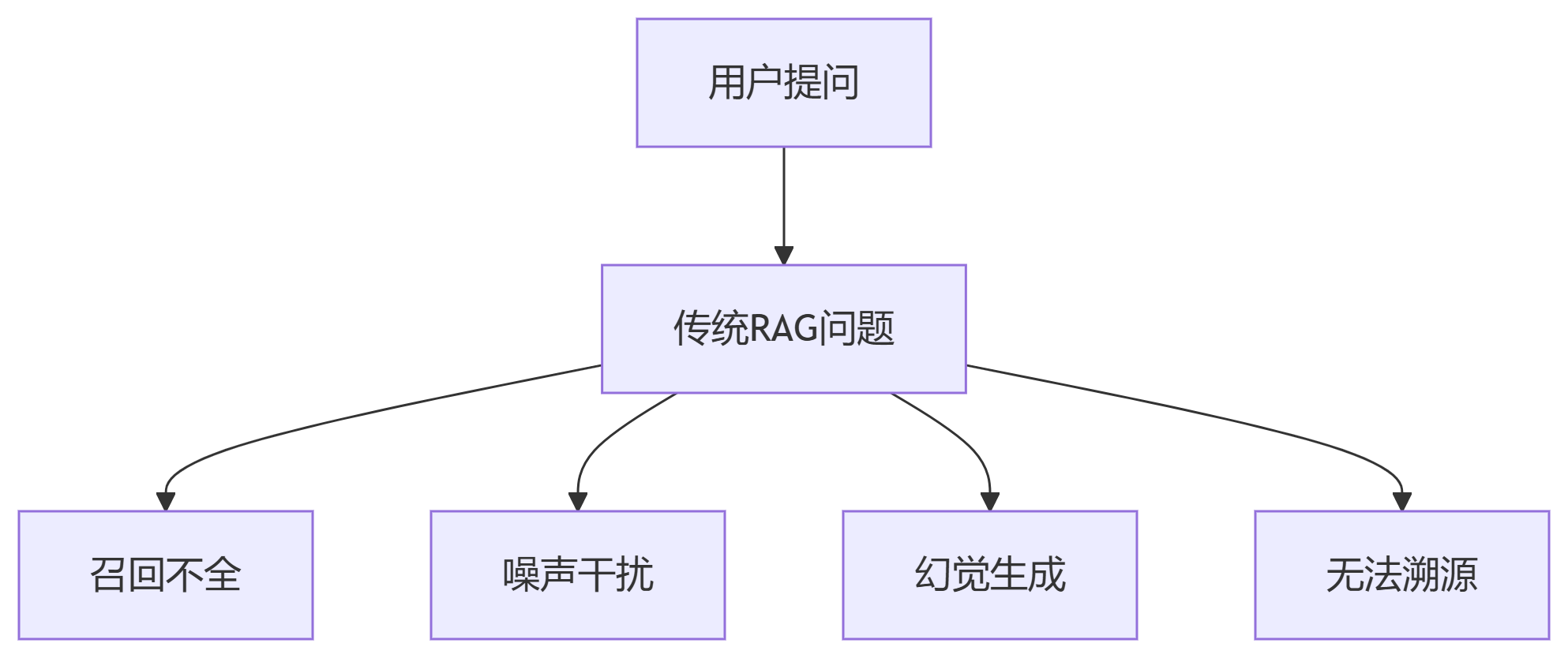
企业级应用常见痛点:
单一检索方式导致关键信息遗漏
长文档噪声降低生成质量
模型虚构未检索到的内容
无法验证答案的可信来源
from llama_index import VectorStoreIndex, KnowledgeGraphIndex, KeywordTableIndex from llama_index.retrievers import BM25Retriever, VectorIndexRetriever, KGTableRetriever # 1. 向量检索(语义匹配) vector_index = VectorStoreIndex.from_documents(docs) vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=5) # 2. 关键词检索(精确匹配) keyword_index = KeywordTableIndex.from_documents(docs) keyword_retriever = BM25Retriever.from_defaults(index=keyword_index, top_k=3) # 3. 知识图谱检索(关系推理) kg_index = KnowledgeGraphIndex.from_documents( docs, kg_triplet_extract_fn=lambda text: extract_triplets(text) # 自定义三元组抽取 ) kg_retriever = KGTableRetriever(index=kg_index, include_text=False) # 4. 融合召回结果 class HybridRetriever(BaseRetriever): def __init__(self, vector_ret, keyword_ret, kg_ret): self.vector_ret = vector_ret self.keyword_ret = keyword_ret self.kg_ret = kg_ret def _retrieve(self, query_bundle: QueryBundle): vector_nodes = self.vector_ret.retrieve(query_bundle) keyword_nodes = self.keyword_ret.retrieve(query_bundle) kg_nodes = self.kg_ret.retrieve(query_bundle) # 权重融合:向量0.6 + 关键词0.3 + 知识图谱0.1 all_nodes = vector_nodes + keyword_nodes + kg_nodes seen_ids = set() unique_nodes = [] for node in all_nodes: if node.node_id not in seen_ids: seen_ids.add(node.node_id) unique_nodes.append(node) return unique_nodes[:10] # 返回Top10结果 hybrid_retriever = HybridRetriever(vector_retriever, keyword_retriever, kg_retriever)
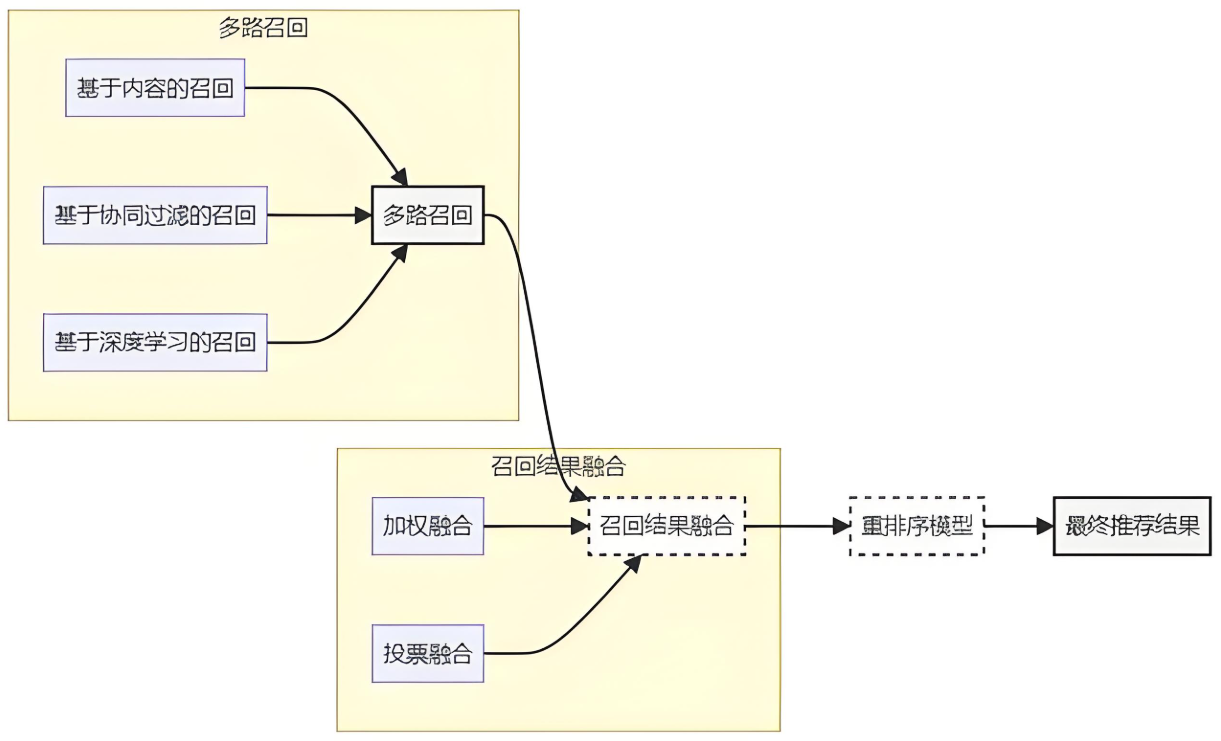
为什么需要重排序?
初步召回结果包含冗余信息
语义相似 ≠ 问题相关性
from sentence_transformers import CrossEncoder
# 1. 微调Cross-Encoder模型
model = CrossEncoder("cross-encoder/stsb-minilm-l6", num_labels=1)
# 训练数据格式:[query, passage] -> 相关性分数(0-1)
train_samples = [
("特斯拉的CEO是谁?", "埃隆·马斯克是特斯拉CEO", 1.0),
("特斯拉的CEO是谁?", "特斯拉生产电动汽车", 0.2),
...
]
model.fit(train_samples, epochs=3)
# 2. 集成到召回流程
def rerank_nodes(query, nodes):
pairs = [(query, node.text) for node in nodes]
scores = model.predict(pairs)
# 按分数排序
reranked_nodes = [
node for _, node in sorted(
zip(scores, nodes),
key=lambda x: x[0],
reverse=True
)
]
return reranked_nodes[:5] # 返回Top5精排结果
# 在检索流程中调用
retrieved_nodes = hybrid_retriever.retrieve(question)
final_nodes = rerank_nodes(question, retrieved_nodes)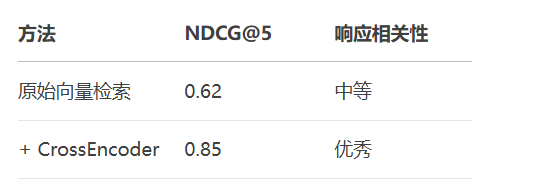
from llama_index.indices.postprocessor import LongContextReorder from llama_index.query_engine import RetrieverQueryEngine # 1. 创建压缩处理器 compressor = ContextualCompressionRetriever( base_retriever=hybrid_retriever, compressor_model="gpt-4-turbo", # 使用大模型识别核心段落 max_tokens=2000 # 上下文上限 ) # 2. 长文档重排序(解决Lost-in-the-Middle问题) reorder_processor = LongContextReorder() # 3. 构建查询引擎 query_engine = RetrieverQueryEngine( retriever=compressor, node_postprocessors=[reorder_processor] )
# 在Prompt中注入引用指令
citation_prompt = """
请根据以下上下文回答问题,并严格遵循:
1. 答案必须来自提供的上下文
2. 每个关键事实后标注来源段落编号,格式如[1]
3. 若上下文无相关信息,回答"未找到可靠来源"
上下文:
{context_str}
问题:{query_str}
"""
# 创建带引用的响应合成器
from llama_index.response_synthesizers import Refine
citation_synthesizer = Refine(
text_qa_template=citation_prompt,
refine_template=citation_prompt + "\n现有回答:{existing_answer}\n请完善:"
)
# 应用到查询引擎
query_engine.update_synthesizer(citation_synthesizer)生成效果对比
- 原始输出: 特斯拉成立于2003年,创始人包括马丁·艾伯哈德和马克·塔彭宁 + 优化输出: 特斯拉成立于2003年[1],创始团队包括马丁·艾伯哈德和马克·塔彭宁[2]。 其中埃隆·马斯克于2004年加入并最终成为CEO[3]。 来源标注: [1] 公司历史文档P12 [2] 创始人传记P5 [3] 董事会决议文件P8
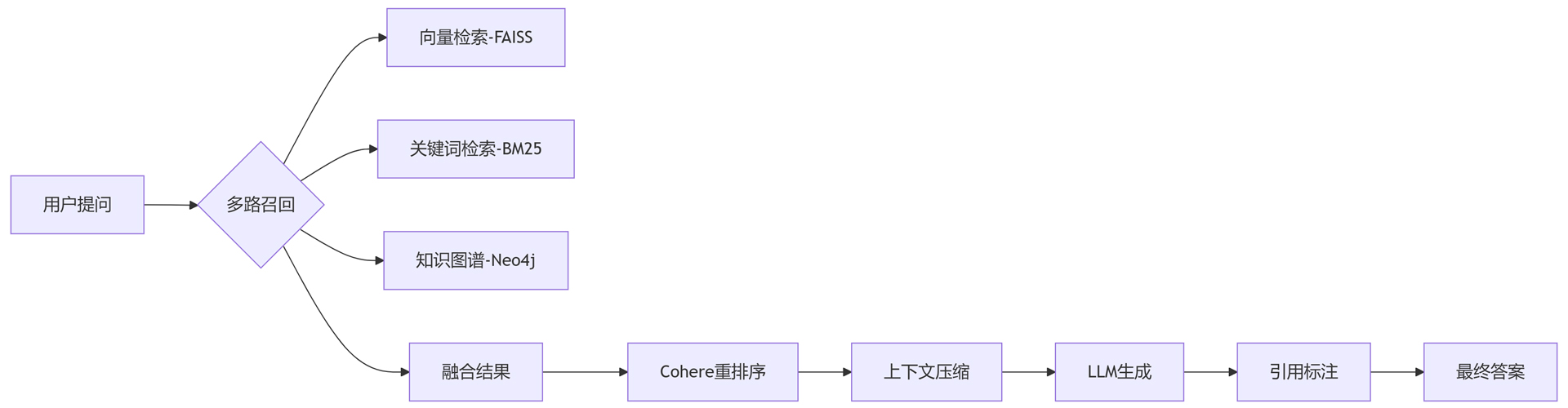
from llama_index import ServiceContext, StorageContext
from llama_index.vector_stores import FAISSVectorStore
import cohere
# 1. 初始化Cohere重排序器
co = cohere.Client("YOUR_API_KEY")
def cohere_rerank(query, nodes):
texts = [node.text for node in nodes]
results = co.rerank(
query=query,
documents=texts,
top_n=5,
model="rerank-english-v3.0"
)
return [nodes[r.index] for r in results]
# 2. 创建FAISS向量库
vector_store = FAISSVectorStore.from_documents(
docs,
service_context=ServiceContext.from_defaults()
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 3. 构建完整流水线
query_engine = RetrieverQueryEngine(
retriever=hybrid_retriever,
node_postprocessors=[
lambda q, n: cohere_rerank(q.query_str, n), # Cohere重排序
compressor, # 上下文压缩
reorder_processor # 长文档优化
],
response_synthesizer=citation_synthesizer
)
# 4. 执行查询
response = query_engine.query("特斯拉的现任CEO是谁?")
print(f"答案:{response.response}")
print("来源:")
for node in response.source_nodes:
print(f"- {node.metadata['file_path']}: {node.text[:100]}...")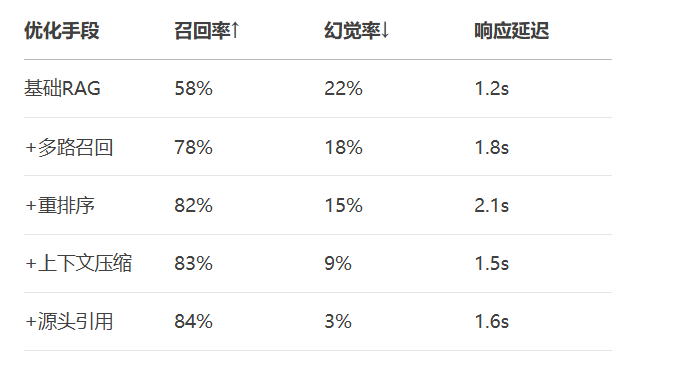
知识图谱冷启动问题
解决方案:
# 使用LLM自动生成初始图谱 from llama_index.llms import OpenAI from llama_index.knowledge_graph import SimpleKnowledgeGraph llm = OpenAI(model="gpt-4-turbo") kg = SimpleKnowledgeGraph.from_documents( documents, llm=llm, # 用大模型抽取三元组 max_triplets_per_chunk=5 )
多路召回资源消耗
优化方案:
向量检索:采用量化索引(FAISS IVF_PQ)
关键词检索:使用Elasticsearch替代内存检索
引用标注冲突
处理逻辑:
def resolve_citation_conflict(sources): # 选择最多被引用的3个来源 counter = Counter(sources) return [doc_id for doc_id, _ in counter.most_common(3)]
遵循此技术路线,可构建符合企业需求的可靠RAG系统。更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



