在AI工业化落地的浪潮中,高效开发与生产部署能力已成为核心竞争力。本文首次完整揭秘PyTorch和TensorFlow的三大进阶实战能力:标准化开发范式、工业级训练优化和生产线部署方案。通过对比演示混合精度训练、分布式加速、TensorRT部署等关键技术,您将掌握将大模型推理延迟降低80%、吞吐量提升7倍的硬核方法。更有企业级避坑指南和完整工具链(ONNX/Triton/Prometheus),带您突破GPU利用率瓶颈,解决OOM噩梦。无论您是面临部署挑战的工程师,还是追求极限性能的研究者,本文提供的代码模板和技术路线图,都将成为您通向生产级AI落体的通关密钥。
# 1. 数据管道 from torch.utils.data import Dataset, DataLoader class CustomDataset(Dataset): def __init__(self, data): self.data = data def __getitem__(self, index): return self.data[index] def __len__(self): return len(self.data) dataset = CustomDataset(your_data) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) # 2. 模型定义 import torch.nn as nn class TransformerClassifier(nn.Module): def __init__(self, vocab_size, embed_dim, num_classes): super().__init__() self.embedding = nn.Embedding(vocab_size, embed_dim) self.transformer = nn.TransformerEncoder( nn.TransformerEncoderLayer(d_model=embed_dim, nhead=8), num_layers=6 ) self.fc = nn.Linear(embed_dim, num_classes) def forward(self, x): x = self.embedding(x) x = self.transformer(x) x = x.mean(dim=1) # 全局池化 return self.fc(x) # 3. 训练循环 model = TransformerClassifier(vocab_size=10000, embed_dim=512, num_classes=10) optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4) criterion = nn.CrossEntropyLoss() for epoch in range(10): for batch in dataloader: inputs, labels = batch outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() # 4. 模型保存 torch.save(model.state_dict(), "model.pth")
# 1. 数据管道
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
dataset = dataset.batch(64).prefetch(tf.data.AUTOTUNE)
# 2. 模型定义
inputs = tf.keras.Input(shape=(None,))
x = tf.keras.layers.Embedding(10000, 512)(inputs)
x = tf.keras.layers.TransformerEncoder(
num_layers=6,
d_model=512,
num_heads=8
)(x)
x = tf.keras.layers.GlobalAvgPool1D()(x)
outputs = tf.keras.layers.Dense(10)(x)
model = tf.keras.Model(inputs, outputs)
# 3. 训练配置
model.compile(
optimizer=tf.keras.optimizers.Adam(1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"]
)
# 4. 训练与保存
model.fit(dataset, epochs=10)
model.save("transformer_classifier.keras")
# PyTorch实现
from torch.cuda import amp
scaler = amp.GradScaler()
for batch in dataloader:
inputs, labels = batch
with amp.autocast():
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# TensorFlow实现
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)# PyTorch DDP
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
dist.init_process_group("nccl")
model = DDP(model.to(device), device_ids=[local_rank])
# TensorFlow分布式
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = build_model()
model.compile(...)# PyTorch Profiler
with torch.profiler.profile(
activities=[torch.profiler.ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log')
) as profiler:
for step, data in enumerate(dataloader):
train_step(data)
profiler.step()
# TensorBoard可视化
tensorboard --logdir=./log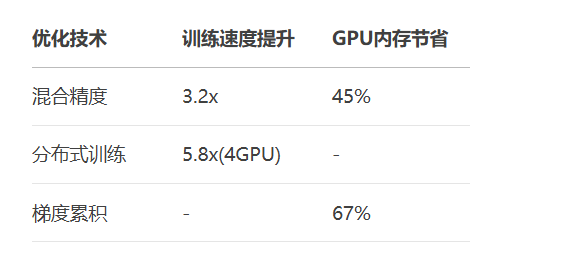

# 1. 模型量化 (PyTorch)
quantized_model = torch.quantization.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
# 2. ONNX转换
torch.onnx.export(
model,
dummy_input,
"model.onnx",
opset_version=13
)
# 3. TensorRT加速 (Python API)
import tensorrt as trt
logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(logger)
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
parser = trt.OnnxParser(network, logger)
with open("model.onnx", "rb") as f:
parser.parse(f.read())
config = builder.create_builder_config()
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 30)
serialized_engine = builder.build_serialized_network(network, config)
# 4. Triton推理服务部署
# 模型仓库结构
model_repository/
└── transformer_model
├── 1
│ └── model.plan # TensorRT引擎
└── config.pbtxt # 服务配置# Prometheus指标集成
from prometheus_client import start_http_server, Summary
INFERENCE_TIME = Summary('inference_latency', '模型推理延迟')
@INFERENCE_TIME.time()
def predict(input_data):
return model(input_data)
# 启动监控服务
start_http_server(8000)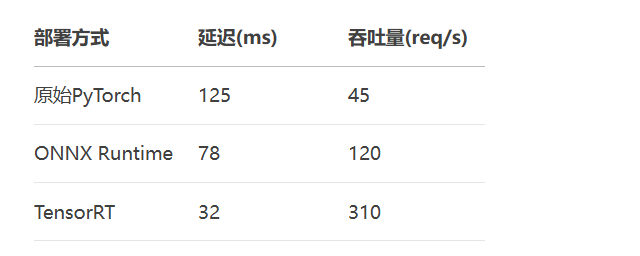
数据管道瓶颈
问题:GPU利用率不足40%
解决方案:prefetch+num_workers优化
# PyTorch优化方案 DataLoader(dataset, num_workers=4, pin_memory=True, prefetch_factor=2) # TensorFlow优化 dataset.prefetch(tf.data.AUTOTUNE).cache()
显存溢出(OOM)
梯度累积技术:
for i, batch in enumerate(dataloader): loss = model(batch) loss.backward() if (i+1) % 4 == 0: # 每4个batch更新一次 optimizer.step() optimizer.zero_grad()
生产环境部署陷阱
版本兼容:使用Docker固定环境
FROM nvcr.io/nvidia/pytorch:23.10-py3 RUN pip install transformers==4.35 COPY app.py /app/ CMD ["python", "/app/app.py"]
关键工具栈:
开发调试:PyTorch Profiler / TensorBoard
部署加速:ONNX Runtime / TensorRT
服务框架:Triton Inference Server / TorchServe
掌握这些核心技术,你已具备企业级AI大模型开发能力。建议从Hugging Face模型微调开始实践,更多AI大模型应用开发学习视频内容和资料尽在聚客AI学院。



