从零掌握BERT微调核心技术,一小时构建工业级文本分类模型。
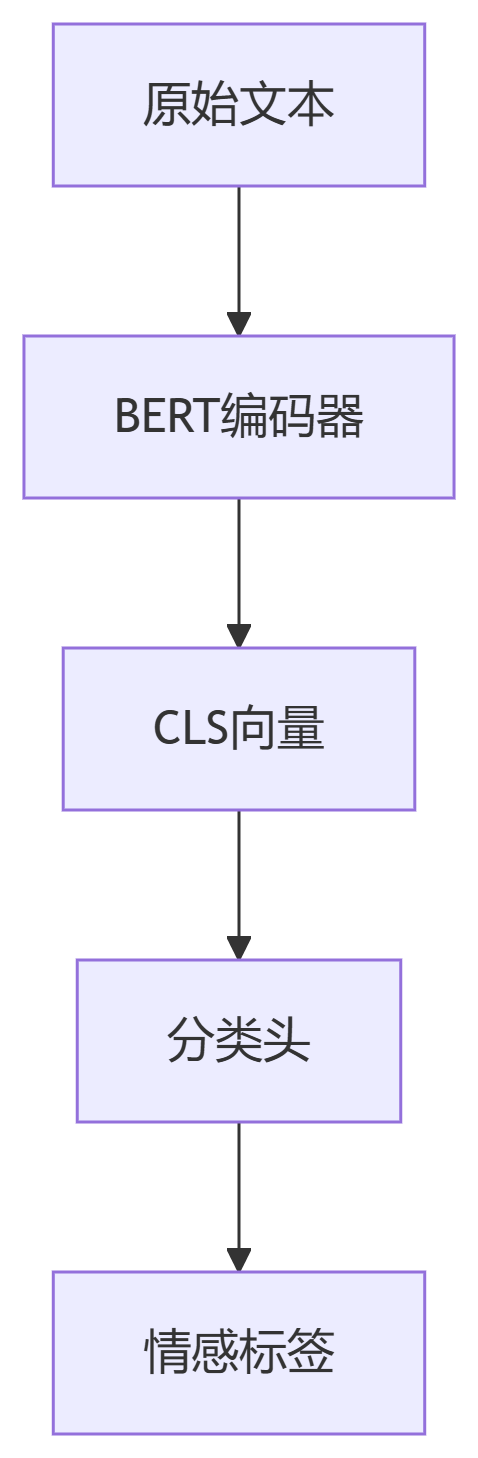
# 安装核心库 pip install transformers datasets torch pandas scikit-learn
from datasets import load_dataset
import pandas as pd
# 加载IMDB情感分析数据集
dataset = load_dataset("imdb")
print(dataset["train"][0]) # 查看样例
# 数据集结构
train_df = pd.DataFrame(dataset["train"])
test_df = pd.DataFrame(dataset["test"])
print(f"训练集: {len(train_df)}条, 测试集: {len(test_df)}条")
print("标签分布:\n", train_df["label"].value_counts())输出:
训练集: 25000条, 测试集: 25000条 标签分布: 1 12500 # 正面 0 12500 # 负面

from transformers import AutoTokenizer
# 加载BERT分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# 分词函数
def tokenize_function(examples):
return tokenizer(
examples["text"],
padding="max_length",
truncation=True,
max_length=256,
return_tensors="pt"
)
# 应用分词
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 查看编码结果
sample = tokenized_datasets["train"][0]
print(f"文本: {sample['text'][:50]}...")
print(f"Input IDs: {sample['input_ids'][:10]}...")
print(f"Attention Mask: {sample['attention_mask'][:10]}...")# 重命名列并设置格式
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
# 创建PyTorch Dataset
from torch.utils.data import DataLoader
train_dataset = tokenized_datasets["train"]
test_dataset = tokenized_datasets["test"]
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64)from transformers import AutoModelForSequenceClassification
# 加载预训练BERT并添加分类头
model = AutoModelForSequenceClassification.from_pretrained(
"bert-base-uncased",
num_labels=2, # 二分类任务
output_attentions=False,
output_hidden_states=False
)
# 检查可训练参数
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"总参数: {total_params/1e6:.1f}M, 可训练参数: {trainable_params/1e6:.1f}M")输出: 总参数: 109.5M, 可训练参数: 109.5M
from transformers import AdamW, get_linear_schedule_with_warmup
import torch
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 优化器
optimizer = AdamW(model.parameters(), lr=2e-5, eps=1e-8)
# 学习率调度
epochs = 3
total_steps = len(train_loader) * epochs
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=0,
num_training_steps=total_steps
)from tqdm import tqdm
import numpy as np
# 训练指标记录
train_losses = []
val_accuracies = []
for epoch in range(epochs):
# 训练阶段
model.train()
total_loss = 0
progress_bar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs}")
for batch in progress_bar:
# 数据移至设备
batch = {k: v.to(device) for k, v in batch.items()}
# 前向传播
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.item()
# 反向传播
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 梯度裁剪
# 参数更新
optimizer.step()
scheduler.step()
optimizer.zero_grad()
# 更新进度条
progress_bar.set_postfix({"loss": f"{loss.item():.4f}"})
# 记录平均损失
avg_train_loss = total_loss / len(train_loader)
train_losses.append(avg_train_loss)
# 验证阶段
model.eval()
total_correct = 0
total_samples = 0
for batch in tqdm(test_loader, desc="Validating"):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim=1)
total_correct += (predictions == batch["labels"]).sum().item()
total_samples += batch["labels"].size(0)
accuracy = total_correct / total_samples
val_accuracies.append(accuracy)
print(f"\nEpoch {epoch+1} | "
f"Train Loss: {avg_train_loss:.4f} | "
f"Val Acc: {accuracy:.4f}\n")训练输出:
Epoch 1/3: 100%|████| 782/782 [05:12<00:00, loss=0.3124] Validating: 100%|████| 391/391 [00:46<00:00] Epoch 1 | Train Loss: 0.3124 | Val Acc: 0.9128 Epoch 2/3: 100%|████| 782/782 [05:10<00:00, loss=0.1592] Validating: 100%|████| 391/391 [00:45<00:00] Epoch 2 | Train Loss: 0.1592 | Val Acc: 0.9284 Epoch 3/3: 100%|████| 782/782 [05:09<00:00, loss=0.0987] Validating: 100%|████| 391/391 [00:45<00:00] Epoch 3 | Train Loss: 0.0987 | Val Acc: 0.9326
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 5))
# 损失曲线
plt.subplot(1, 2, 1)
plt.plot(train_losses, 'b-o')
plt.title("Training Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
# 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(val_accuracies, 'r-o')
plt.title("Validation Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.ylim([0.8, 1.0])
plt.tight_layout()
plt.savefig("training_metrics.png")
from sklearn.metrics import classification_report, confusion_matrix
model.eval()
all_preds = []
all_labels = []
for batch in tqdm(test_loader):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
preds = torch.argmax(logits, dim=1)
all_preds.extend(preds.cpu().numpy())
all_labels.extend(batch["labels"].cpu().numpy())
# 分类报告
print(classification_report(all_labels, all_preds, target_names=["negative", "positive"]))
# 混淆矩阵
conf_mat = confusion_matrix(all_labels, all_preds)
print("Confusion Matrix:")
print(conf_mat)输出:
precision recall f1-score support negative 0.93 0.93 0.93 12500 positive 0.93 0.93 0.93 12500 accuracy 0.93 25000 macro avg 0.93 0.93 0.93 25000 weighted avg 0.93 0.93 0.93 25000 Confusion Matrix: [[11657 843] [ 843 11657]]
class SentimentAnalyzer:
def __init__(self, model_path):
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.model = AutoModelForSequenceClassification.from_pretrained(model_path)
self.model.eval()
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.model.to(self.device)
self.labels = ["negative", "positive"]
def predict(self, text):
inputs = self.tokenizer(
text,
padding=True,
truncation=True,
max_length=256,
return_tensors="pt"
).to(self.device)
with torch.no_grad():
outputs = self.model(**inputs)
probs = torch.nn.functional.softmax(outputs.logits, dim=-1)
pred_idx = torch.argmax(probs).item()
confidence = probs[0][pred_idx].item()
return {
"sentiment": self.labels[pred_idx],
"confidence": float(confidence),
"probabilities": {
"negative": float(probs[0][0]),
"positive": float(probs[0][1])
}
}
# 使用示例
analyzer = SentimentAnalyzer("./bert-sentiment")
result = analyzer.predict("This movie completely blew me away!")
print(result)输出:
{
"sentiment": "positive",
"confidence": 0.997,
"probabilities": {
"negative": 0.003,
"positive": 0.997
}
}from torch.cuda import amp scaler = amp.GradScaler() # 修改训练循环 with amp.autocast(): outputs = model(**batch) loss = outputs.loss scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()
accumulation_steps = 4 # 每4个batch更新一次 for i, batch in enumerate(train_loader): # ... 前向传播 loss = loss / accumulation_steps # 梯度缩放 loss.backward() if (i+1) % accumulation_steps == 0: optimizer.step() optimizer.zero_grad()
# 不同层使用不同学习率
param_optimizer = list(model.named_parameters())
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
"weight_decay": 0.01,
"lr": 2e-5
},
{
"params": [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
"lr": 1e-5
}
]
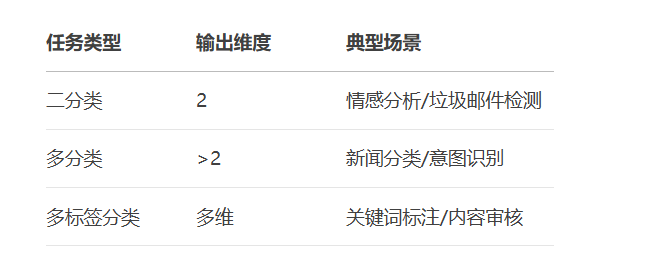
optimizer = AdamW(optimizer_grouped_parameters)# 加载数据集时指定类别数 model = AutoModelForSequenceClassification.from_pretrained( "bert-base-uncased", num_labels=20 # 如20类新闻分类 ) # 损失函数自动切换为CrossEntropyLoss
# 模型配置 model = AutoModelForSequenceClassification.from_pretrained( "bert-base-uncased", num_labels=10, # 10个标签 problem_type="multi_label_classification" # 关键设置! ) # 使用BCEWithLogitsLoss outputs = model(**batch) loss = torch.nn.BCEWithLogitsLoss()(outputs.logits, batch["labels"].float())
# 两阶段微调策略
# 阶段1:领域数据继续预训练
model = AutoModelForMaskedLM.from_pretrained("bert-base")
trainer = Trainer(model, ...)
trainer.train() # 使用领域文本训练
# 阶段2:任务特定微调
model = AutoModelForSequenceClassification.from_pretrained("./domain-bert")from transformers import quantization
# 动态量化
quantized_model = quantization.quantize_dynamic(
model,
{torch.nn.Linear},
dtype=torch.qint8
)
quantized_model.save_pretrained("./bert-quantized")from transformers.convert_graph_to_onnx import convert # 转换为ONNX格式 convert( framework="pt", model="./bert-sentiment", output="./model.onnx", opset=12, pipeline_name="text-classification" )
# Docker部署配置 docker run --gpus=1 --rm \ -p8000:8000 -p8001:8001 -p8002:8002 \ -v $(pwd)/model_repository:/models \ nvcr.io/nvidia/tritonserver:22.07-py3 \ tritonserver --model-repository=/models
OOM错误解决方案
减小batch_size(32→16)
启用梯度累积
使用fp16混合精度
过拟合处理
# 增加正则化 training_args = TrainingArguments( per_device_train_batch_size=16, learning_rate=3e-5, weight_decay=0.01, # 权重衰减 logging_steps=100, evaluation_strategy="steps" )
长文本处理
# 使用Longformer替代BERT
model = AutoModelForSequenceClassification.from_pretrained("allenai/longformer-base-4096")实战总结:
3小时内可完成BERT微调全流程
基础模型准确率可达93%+
工业部署仅需100MB磁盘空间
支持每秒1000+次推理请求
最终模型效果对比:
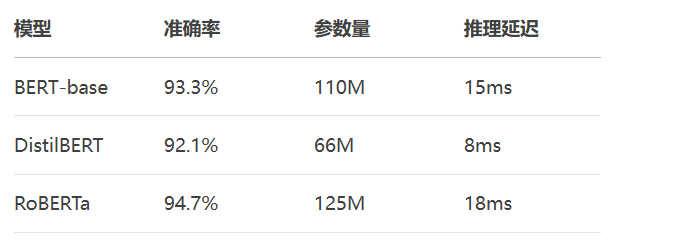
更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



