本文深入解析大模型开发中的数据预处理全流程,掌握这些技能可处理TB级文本数据,构建工业级数据流水线。
pip install datasets tokenizers torchtext sentencepiece
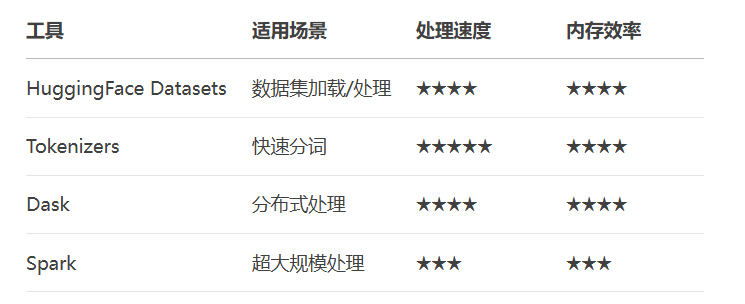
from datasets import load_dataset
# 加载1.7TB的C4数据集(仅加载1%样本)
dataset = load_dataset("c4", "en", split="train", streaming=True).take(100_000)
# 分布式处理方案
import dask.dataframe as dd
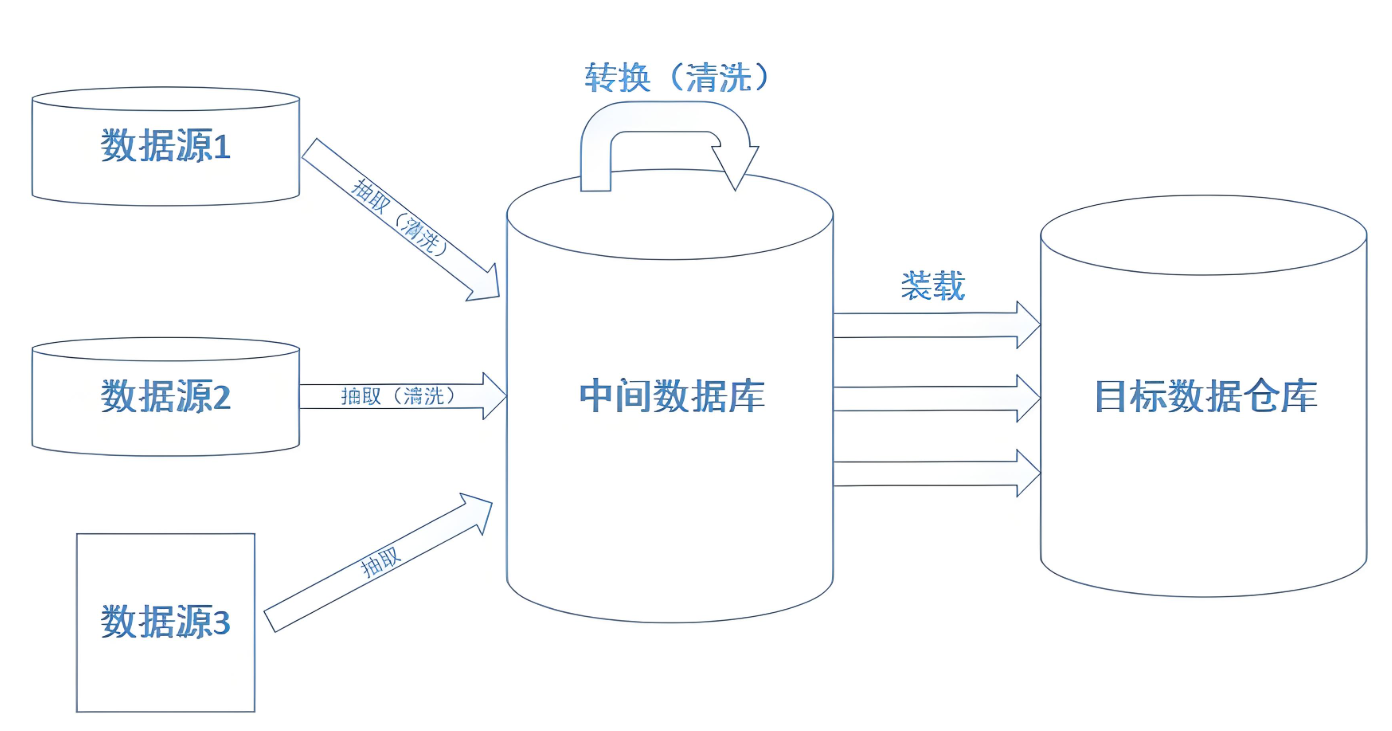
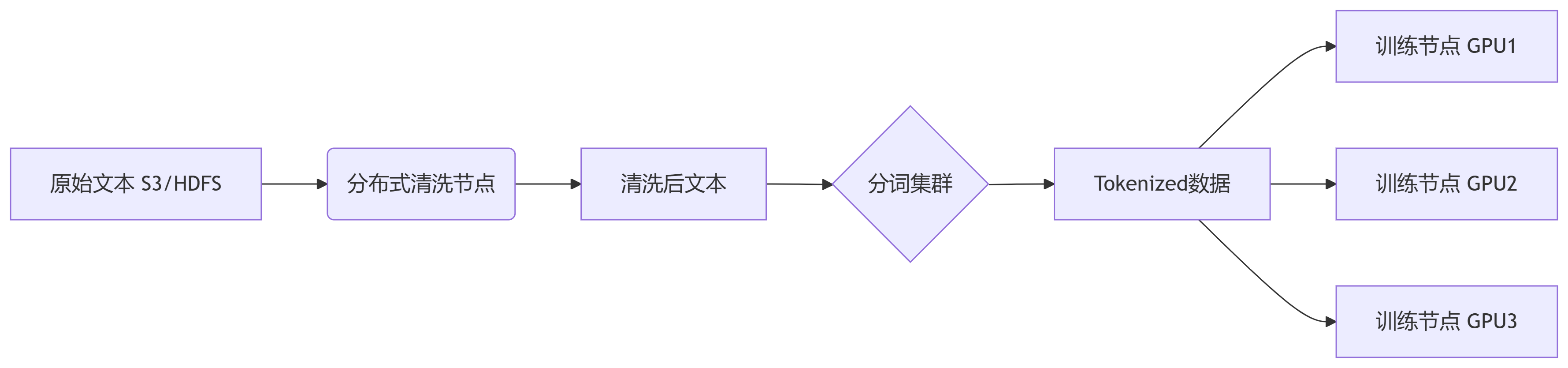
df = dd.read_parquet("s3://my-bucket/text-data/*.parquet", blocksize="1GB")import re from bs4 import BeautifulSoup def clean_text(text): # 移除HTML标签 text = BeautifulSoup(text, "lxml").get_text() # 过滤低质量内容 if len(text) < 100 or len(text) > 10_000: return None # 标准化文本 text = re.sub(r'\s+', ' ', text) # 合并空白字符 text = re.sub(r'[^\w\s.,?!]', '', text) # 移除非标准字符 # 语言检测(示例) if detect_language(text) != "en": return None return text.strip() # 应用清洗(分布式执行) cleaned_df = df.map_partitions(lambda df: df["text"].apply(clean_text))
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
trainer = BpeTrainer(
vocab_size=30000,
special_tokens=["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]
)
# 训练BPE分词器
tokenizer.train(files=["text1.txt", "text2.txt"], trainer=trainer)
# 保存与加载
tokenizer.save("bpe_tokenizer.json")
Tokenizer.from_file("bpe_tokenizer.json")from tokenizers import Tokenizer from tokenizers.models import WordPiece from tokenizers.trainers import WordPieceTrainer tokenizer = Tokenizer(WordPiece(unk_token="[UNK]")) trainer = WordPieceTrainer( vocab_size=50000, special_tokens=["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"] ) tokenizer.train(files=["text_corpus.txt"], trainer=trainer)
import sentencepiece as spm
# 训练配置
spm.SentencePieceTrainer.train(
input='merged_corpus.txt',
model_prefix='sp_model',
vocab_size=50000,
character_coverage=0.9995,
model_type='bpe', # 可选bpe/unigram
user_defined_symbols=['<mask>', '<sep>'],
pad_id=0
)
# 使用分词器
sp = spm.SentencePieceProcessor()
sp.load("sp_model.model")
tokens = sp.encode("自然语言处理真有趣!", out_type=str)
import torch
from torch.utils.data import Dataset
from transformers import AutoTokenizer
class TextDataset(Dataset):
def __init__(self, file_path, tokenizer_name, max_length=128):
self.data = self.load_data(file_path)
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
self.max_length = max_length
def __len__(self):
return len(self.data)
def load_data(self, path):
# 实现内存映射加载
return np.memmap(path, dtype='uint16', mode='r')
def __getitem__(self, idx):
text = self.data[idx]
encoding = self.tokenizer(
text,
max_length=self.max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
)
return {
'input_ids': encoding['input_ids'].squeeze(),
'attention_mask': encoding['attention_mask'].squeeze()
}from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
dataset = TextDataset("processed_data.bin", "bert-base-uncased")
# 多进程数据加载
loader = DataLoader(
dataset,
batch_size=256,
num_workers=8,
pin_memory=True, # GPU加速
prefetch_factor=4, # 预加载批次
sampler=DistributedSampler(dataset) # 分布式训练
)
# 内存映射优化(100GB+数据集)
loader = DataLoader(
dataset,
batch_size=512,
collate_fn=lambda x: torch.utils.data.default_collate(x),
persistent_workers=True
)from datasets import IterableDataset
def data_generator():
with open("huge_file.txt", "r") as f:
while True:
line = f.readline()
if not line:
break
yield {"text": line}
streaming_dataset = IterableDataset.from_generator(data_generator)from transformers import DataCollatorForLanguageModeling collator = DataCollatorForLanguageModeling( tokenizer=tokenizer, mlm=True, mlm_probability=0.15 ) loader = DataLoader( dataset, batch_size=256, collate_fn=collator # 动态填充至批次内最大长度 )
import matplotlib.pyplot as plt
# 计算压缩率
original_lengths = [len(text) for text in sample_texts]
token_lengths = [len(tokenizer.tokenize(text)) for text in sample_texts]
compression_ratio = np.mean(original_lengths) / np.mean(token_lengths)
# 可视化分布
plt.figure(figsize=(10,6))
plt.hist(token_lengths, bins=50, alpha=0.7)
plt.title(f'Token Length Distribution (Avg: {np.mean(token_lengths):.1f})')
plt.xlabel('Token Count')
plt.ylabel('Frequency')
plt.savefig('token_distribution.png')from torch.utils.data import IterableDataset
import time
class ProfiledDataset(IterableDataset):
def __init__(self, dataset):
self.dataset = dataset
self.profile = {'load_time': 0, 'count': 0}
def __iter__(self):
for item in self.dataset:
start = time.time()
yield item
self.profile['load_time'] += time.time() - start
self.profile['count'] += 1
def get_stats(self):
avg_time = self.profile['load_time'] / self.profile['count']
return f"{avg_time*1000:.2f} ms per sample"黄金比例:训练集/验证集/测试集按90/5/5划分
分词优化:
中文推荐SentencePiece
英文推荐BPE或WordPiece
内存管理:
# 减少内存碎片 torch.backends.cudnn.benchmark = True torch.set_num_threads(4)
灾难恢复:
# 定期保存检查点 loader = DataLoader(..., generator=torch.Generator().manual_seed(42))
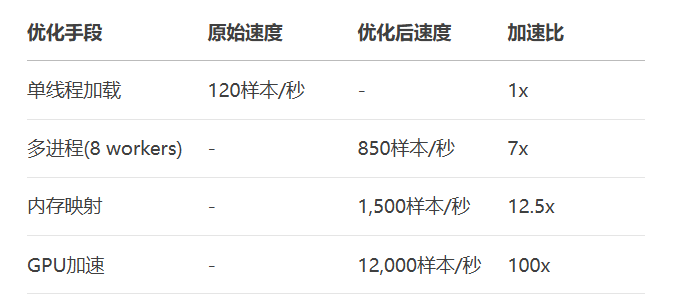
关键建议:
处理超大规模数据时,优先使用流式处理
分词器训练样本至少100MB,推荐1GB+
使用datasets库的map方法时设置batched=True可提速5倍
对于中文文本,设置jieba分词作为预处理可提升效果
更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



