本文深入解析Transformer模型的训练与推理机制,通过可视化图解和完整代码实现,系统讲解训练过程、自回归生成原理以及Beam Search优化策略。

import torch
import torch.nn as nn
from torch.optim import Adam
from torch.utils.data import Dataset, DataLoader
# 自定义数据集
class TranslationDataset(Dataset):
def __init__(self, src_sentences, tgt_sentences, src_vocab, tgt_vocab):
self.src_enc = [[src_vocab[word] for word in sent.split()] for sent in src_sentences]
self.tgt_enc = [[tgt_vocab[word] for word in sent.split()] for sent in tgt_sentences]
def __len__(self):
return len(self.src_enc)
def __getitem__(self, idx):
return torch.tensor(self.src_enc[idx]), torch.tensor(self.tgt_enc[idx])
# 训练循环函数
def train_transformer(model, dataloader, epochs=10, lr=0.001):
criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略填充符
optimizer = Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
total_loss = 0
for src, tgt in dataloader:
# 准备数据 (添加起始/终止符)
tgt_input = tgt[:, :-1]
tgt_output = tgt[:, 1:]
# 前向传播
pred = model(src, tgt_input)
# 计算损失 (展平序列维度)
loss = criterion(
pred.reshape(-1, pred.size(-1)),
tgt_output.reshape(-1)
)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 梯度裁剪 (防止爆炸)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# 参数更新
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs} | Loss: {total_loss/len(dataloader):.4f}")
return modelimport matplotlib.pyplot as plt
# 模拟训练损失
epochs = 10
train_loss = [3.2, 2.1, 1.5, 1.2, 0.9, 0.7, 0.6, 0.5, 0.45, 0.4]
plt.figure(figsize=(10, 5))
plt.plot(range(1, epochs+1), train_loss, 'o-')
plt.title('Transformer训练损失曲线')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.grid(True)
plt.xticks(range(1, epochs+1))
plt.show()训练关键要素:
数据批处理:动态填充与掩码生成
教师强制:训练时使用真实目标序列
梯度裁剪:防止梯度爆炸
学习率调度:预热与衰减策略
def greedy_decode(model, src, src_vocab, tgt_vocab, max_len=20):
"""贪婪解码算法"""
model.eval()
src_mask = (src != 0).unsqueeze(1) # 创建源序列掩码
# 初始化解码器输入 (起始符)
tgt = torch.ones(1, 1).fill_(tgt_vocab['<sos>']).long()
# 编码器前向传播
with torch.no_grad():
encoder_output = model.encoder(src, src_mask)
# 逐步生成序列
for i in range(max_len):
# 创建目标序列掩码 (下三角矩阵)
tgt_mask = torch.tril(torch.ones(i+1, i+1)) == 0
# 解码器前向传播
with torch.no_grad():
output = model.decoder(
tgt,
encoder_output,
src_mask,
tgt_mask
)
# 获取最后一个预测词
pred_token = output.argmax(dim=-1)[:, -1].item()
# 添加到序列
tgt = torch.cat([tgt, torch.tensor([[pred_token]])], dim=1)
# 遇到终止符停止
if pred_token == tgt_vocab['<eos>']:
break
# 转换为文本
decoded_tokens = [tgt_vocab_inv[idx] for idx in tgt[0].tolist()]
return ' '.join(decoded_tokens[1:-1]) # 去掉起始/终止符
# 示例使用
src_sentence = "I love machine learning"
src_tokens = [src_vocab.get(word, src_vocab['<unk>']) for word in src_sentence.split()]
src_tensor = torch.tensor([src_tokens])
translation = greedy_decode(model, src_tensor, src_vocab, tgt_vocab)
print(f"源句: {src_sentence}")
print(f"翻译: {translation}")import numpy as np
# 创建模拟生成过程
generation_steps = [
["<sos>", "", "", "", ""],
["<sos>", "Je", "", "", ""],
["<sos>", "Je", "t'aime", "", ""],
["<sos>", "Je", "t'aime", "l'apprentissage", ""],
["<sos>", "Je", "t'aime", "l'apprentissage", "automatique"],
["<sos>", "Je", "t'aime", "l'apprentissage", "automatique<eos>"]
]
# 可视化
fig, ax = plt.subplots(figsize=(10, 6))
ax.set_title('自回归生成过程')
ax.set_xlabel('生成步骤')
ax.set_ylabel('序列位置')
ax.set_xticks(range(len(generation_steps)))
ax.set_yticks(range(len(generation_steps[0])))
# 绘制表格
for i, step in enumerate(generation_steps):
for j, token in enumerate(step):
ax.text(i, j, token, ha='center', va='center',
bbox=dict(boxstyle='round', facecolor='lightblue' if token else 'white'))
# 连接线
if i > 0 and j < len(generation_steps[i-1]) and generation_steps[i-1][j]:
ax.plot([i-1, i], [j, j], 'k-', lw=1)
if j < len(step)-1 and step[j+1]:
ax.plot([i, i], [j, j+1], 'k-', lw=1)
plt.grid(False)
plt.show()
def beam_search_decode(model, src, src_vocab, tgt_vocab, beam_size=3, max_len=20):
"""Beam Search解码算法"""
model.eval()
src_mask = (src != 0).unsqueeze(1)
# 编码器前向传播
with torch.no_grad():
encoder_output = model.encoder(src, src_mask)
# 初始化Beam
start_token = tgt_vocab['<sos>']
end_token = tgt_vocab['<eos>']
# 初始Beam: (序列, 概率, 完成标志)
beams = [(torch.tensor([[start_token]]), 0.0, False)]
# 逐步生成
for step in range(max_len):
all_candidates = []
# 扩展每个Beam
for seq, score, done in beams:
# 已完成序列直接传递
if done:
all_candidates.append((seq, score, True))
continue
# 创建目标序列掩码
tgt_mask = torch.tril(torch.ones(seq.size(1), seq.size(1)) == 0
# 解码器前向传播
with torch.no_grad():
output = model.decoder(
seq,
encoder_output,
src_mask,
tgt_mask
)
log_probs = torch.log_softmax(output[:, -1], dim=-1)
topk_probs, topk_tokens = log_probs.topk(beam_size, dim=-1)
# 生成新候选
for i in range(beam_size):
token = topk_tokens[0, i].item()
new_score = score + topk_probs[0, i].item()
new_seq = torch.cat([seq, torch.tensor([[token]])], dim=1)
new_done = (token == end_token) or done
all_candidates.append((new_seq, new_score, new_done))
# 按分数排序并选择Top-k
ordered = sorted(all_candidates, key=lambda x: x[1], reverse=True)
beams = ordered[:beam_size]
# 检查是否全部完成
if all(done for _, _, done in beams):
break
# 选择最佳序列
best_seq = beams[0][0].squeeze().tolist()
decoded_tokens = [tgt_vocab_inv[idx] for idx in best_seq]
return ' '.join(decoded_tokens[1:-1]) # 去掉起始/终止符
# 示例使用
translation_beam = beam_search_decode(model, src_tensor, src_vocab, tgt_vocab, beam_size=3)
print(f"Beam Search翻译: {translation_beam}")# 创建模拟Beam Search树
beam_tree = {
"root": {"seq": ["<sos>"], "prob": 0.0},
"A": {"parent": "root", "seq": ["<sos>", "Je"], "prob": -0.2},
"B": {"parent": "root", "seq": ["<sos>", "I"], "prob": -1.5},
"C": {"parent": "root", "seq": ["<sos>", "Nous"], "prob": -2.0},
"A1": {"parent": "A", "seq": ["<sos>", "Je", "t'aime"], "prob": -0.5},
"A2": {"parent": "A", "seq": ["<sos>", "Je", "suis"], "prob": -1.8},
"A3": {"parent": "A", "seq": ["<sos>", "Je", "adore"], "prob": -1.2},
"A1a": {"parent": "A1", "seq": ["<sos>", "Je", "t'aime", "l'IA"], "prob": -0.7},
"A1b": {"parent": "A1", "seq": ["<sos>", "Je", "t'aime", "les"], "prob": -1.5},
}
# 可视化
plt.figure(figsize=(12, 8))
ax = plt.gca()
ax.set_title('Beam Search搜索树 (beam_size=3)')
ax.set_axis_off()
# 节点位置
positions = {
"root": (0, 0),
"A": (1, 1), "B": (1, 0), "C": (1, -1),
"A1": (2, 1.5), "A2": (2, 1), "A3": (2, 0.5),
"A1a": (3, 1.7), "A1b": (3, 1.3)
}
# 绘制连接线
for node, info in beam_tree.items():
if node != "root":
parent = info["parent"]
x1, y1 = positions[parent]
x2, y2 = positions[node]
ax.plot([x1, x2], [y1, y2], 'k-', lw=1)
# 绘制节点
seq_text = ' '.join(info["seq"])
prob_text = f"{info['prob']:.1f}"
ax.text(x2, y2, f"{seq_text}\n{prob_text}",
ha='center', va='center',
bbox=dict(boxstyle='round', facecolor='lightgreen' if node.startswith('A1') else 'lightblue'))
# 标记最终选择
ax.text(positions["A1a"][0]+0.1, positions["A1a"][1], "★",
fontsize=20, color='gold', ha='center', va='center')
plt.xlim(-0.5, 4)
plt.ylim(-1.5, 2)
plt.show()
Beam Search关键参数:
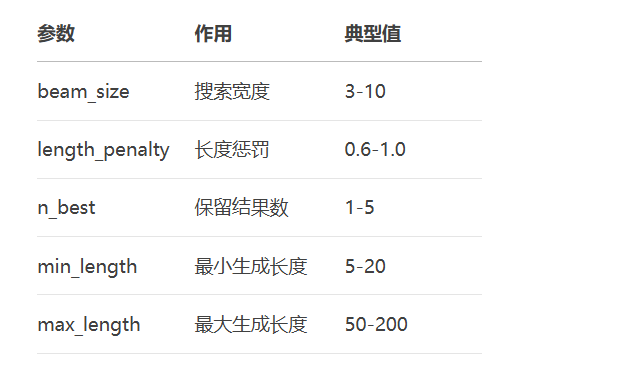
def compare_train_inference():
"""训练与推理模式差异对比"""
print("训练模式:")
print("- 教师强制: 使用完整目标序列作为输入")
print("- 并行计算: 同时处理整个序列")
print("- 梯度更新: 反向传播优化参数")
print("- 高计算量: 需要计算所有位置")
print("\n推理模式:")
print("- 自回归生成: 逐步生成序列")
print("- 序列依赖: 每个步骤依赖前序输出")
print("- 无梯度计算: 只需前向传播")
print("- 搜索策略: 使用Beam Search等优化")
# 执行对比
compare_train_inference()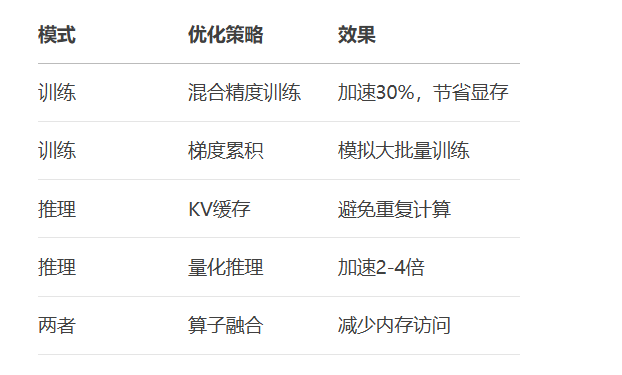
import math
import copy
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# 线性变换并分割多头
Q = self.W_q(Q).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
K = self.W_k(K).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
V = self.W_v(V).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.head_dim)
# 应用掩码
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# 计算注意力权重
attn_weights = F.softmax(scores, dim=-1)
# 加权求和
output = torch.matmul(attn_weights, V)
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
return self.W_o(output), attn_weights
class PositionWiseFFN(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.ffn = PositionWiseFFN(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
# 自注意力 + 残差连接
attn_output, _ = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 前馈网络 + 残差连接
ffn_output = self.ffn(x)
x = self.norm2(x + self.dropout(ffn_output))
return x
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.ffn = PositionWiseFFN(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask, tgt_mask):
# 掩码自注意力
attn_output, _ = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
# 编码器-解码器注意力
cross_output, _ = self.cross_attn(x, encoder_output, encoder_output, src_mask)
x = self.norm2(x + self.dropout(cross_output))
# 前馈网络
ffn_output = self.ffn(x)
x = self.norm3(x + self.dropout(ffn_output))
return x
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_len=100):
super().__init__()
self.encoder_embed = nn.Embedding(src_vocab_size, d_model)
self.decoder_embed = nn.Embedding(tgt_vocab_size, d_model)
# 位置编码
self.position_encoding = self.create_position_encoding(max_seq_len, d_model)
# 编码器
self.encoder_layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)
])
# 解码器
self.decoder_layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)
])
# 输出层
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
def create_position_encoding(self, max_len, d_model):
"""创建位置编码矩阵"""
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return pe
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
# 嵌入 + 位置编码
src_emb = self.encoder_embed(src) + self.position_encoding[:src.size(1), :]
tgt_emb = self.decoder_embed(tgt) + self.position_encoding[:tgt.size(1), :]
# 编码器
enc_output = src_emb
for layer in self.encoder_layers:
enc_output = layer(enc_output, src_mask)
# 解码器
dec_output = tgt_emb
for layer in self.decoder_layers:
dec_output = layer(dec_output, enc_output, src_mask, tgt_mask)
# 输出层
return self.fc_out(dec_output)# 1. 数据准备
src_vocab = {"<pad>": 0, "<sos>": 1, "<eos>": 2, "I": 3, "love": 4, "machine": 5, "learning": 6}
tgt_vocab = {"<pad>": 0, "<sos>": 1, "<eos>": 2, "Je": 3, "t'aime": 4, "l'apprentissage": 5, "automatique": 6}
tgt_vocab_inv = {v: k for k, v in tgt_vocab.items()}
# 2. 创建数据集
src_sentences = ["I love machine learning"]
tgt_sentences = ["Je t'aime l'apprentissage automatique"]
dataset = TranslationDataset(src_sentences, tgt_sentences, src_vocab, tgt_vocab)
dataloader = DataLoader(dataset, batch_size=1)
# 3. 初始化模型
model = Transformer(
src_vocab_size=len(src_vocab),
tgt_vocab_size=len(tgt_vocab),
d_model=128,
num_heads=8,
num_layers=3,
d_ff=512
)
# 4. 训练模型
model = train_transformer(model, dataloader, epochs=10, lr=0.0001)
# 5. 推理生成
src_tensor = torch.tensor([[src_vocab["I"], src_vocab["love"], src_vocab["machine"], src_vocab["learning"]]])
greedy_result = greedy_decode(model, src_tensor, src_vocab, tgt_vocab)
beam_result = beam_search_decode(model, src_tensor, src_vocab, tgt_vocab, beam_size=3)
print(f"贪婪解码结果: {greedy_result}")
print(f"Beam Search结果: {beam_result}")class DecoderWithCache(nn.Module):
"""带KV缓存的解码器优化"""
def __init__(self, decoder_layer, num_layers):
super().__init__()
self.layers = nn.ModuleList([decoder_layer for _ in range(num_layers)])
self.cache = None
def init_cache(self, batch_size, max_len):
"""初始化缓存"""
self.cache = [{
'k': torch.zeros(batch_size, max_len, self.layers[0].d_model),
'v': torch.zeros(batch_size, max_len, self.layers[0].d_model)
} for _ in range(len(self.layers))]
def forward(self, x, encoder_output, step=0):
"""带缓存的推理前向传播"""
if self.cache is None:
self.init_cache(x.size(0), 100) # 初始化缓存
for i, layer in enumerate(self.layers):
# 更新缓存
self.cache[i]['k'][:, step:step+1] = layer.k_proj(x)
self.cache[i]['v'][:, step:step+1] = layer.v_proj(x)
# 使用缓存计算注意力
k = self.cache[i]['k'][:, :step+1]
v = self.cache[i]['v'][:, :step+1]
x = layer.attention(x, k, v)
# 后续计算...
return xfrom torch.cuda.amp import autocast def generate_with_amp(model, src): """混合精度推理""" model.eval() with torch.no_grad(): with autocast(): output = model(src) return output
# 训练后动态量化
quantized_model = torch.quantization.quantize_dynamic(
model,
{nn.Linear},
dtype=torch.qint8
)
# 保存量化模型
torch.save(quantized_model.state_dict(), "quantized_transformer.pth")训练核心流程:
for epoch in range(epochs): for batch in dataloader: # 前向传播 pred = model(src, tgt_input) loss = criterion(pred, tgt_output) # 反向传播 optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step()
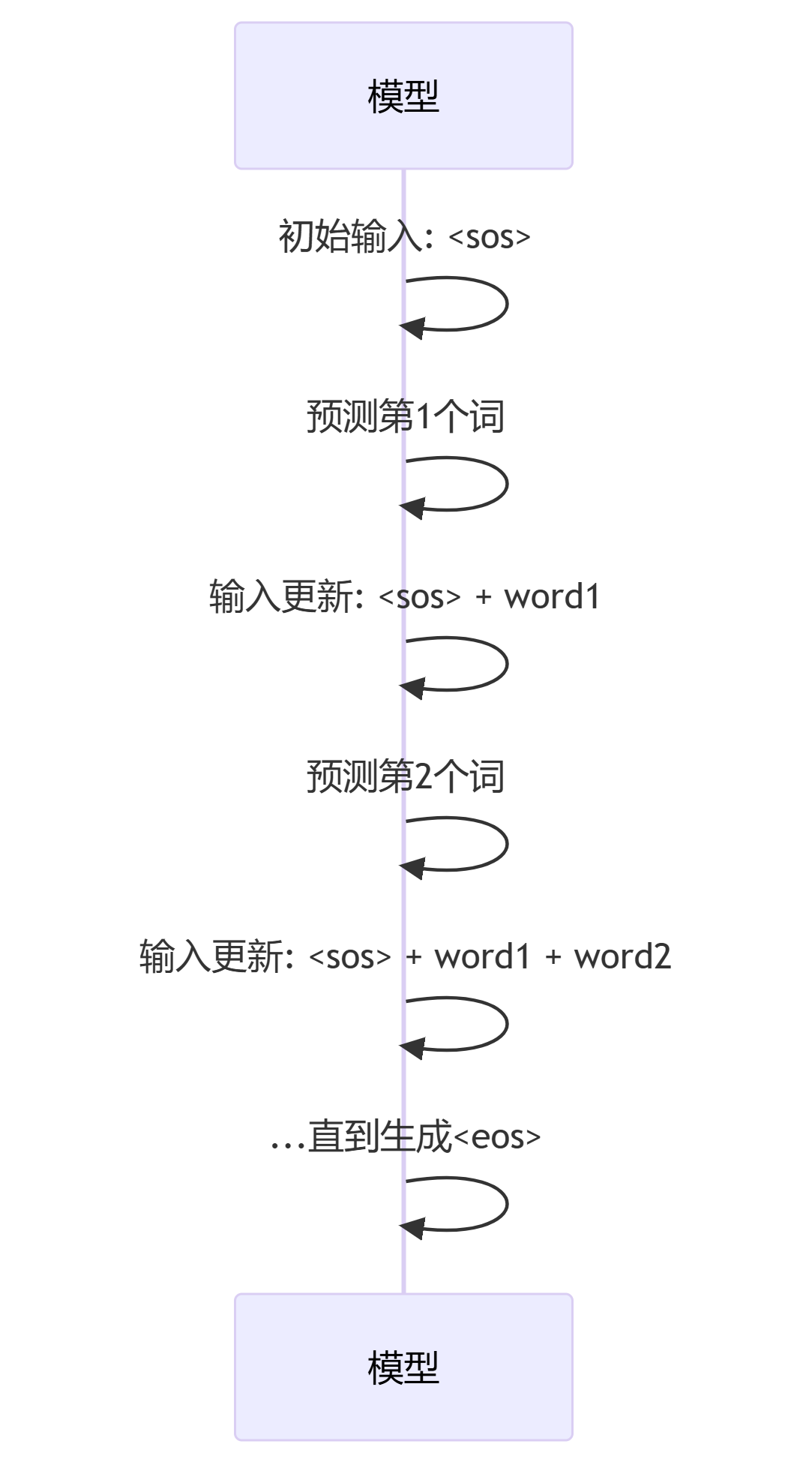
自回归生成步骤:
while not end_condition: 输入 = 当前序列 输出 = model(输入) 新词 = argmax(输出[-1]) 序列 = 序列 + 新词
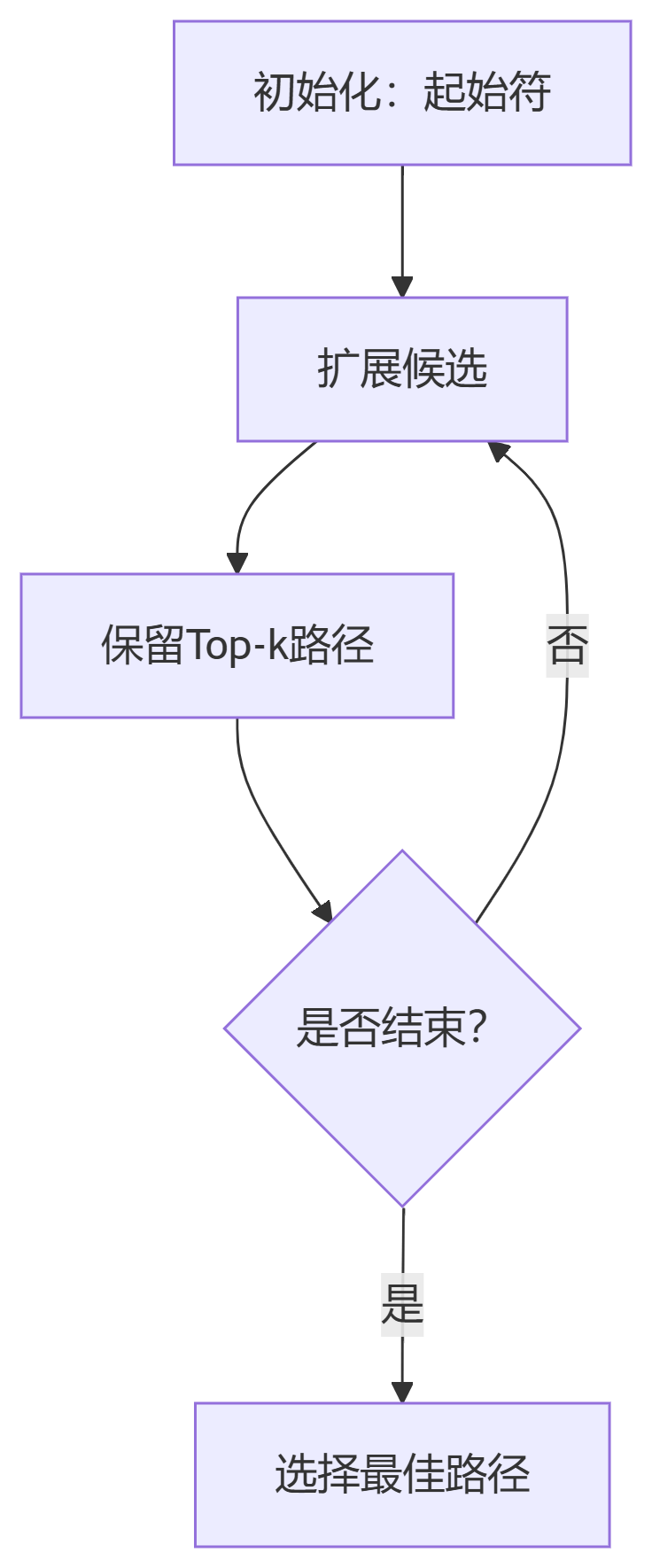
Beam Search伪代码:
初始化: beams = [(<sos>, 0.0)] for step in range(max_len): 候选列表 = [] for beam in beams: 扩展候选 = beam 扩展 top_k 个词 候选列表 += 扩展候选 beams = 候选列表中分数最高的k个 return beams[0] # 最佳序列
性能优化对比:

通过掌握Transformer的训练与推理全流程,你将能够高效开发和生产部署各类大语言模型,为构建实际AI应用奠定坚实基础!更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



