本文深入剖析Transformer解码器的核心机制,通过数学原理、可视化图解和完整代码实现,详细讲解掩码自注意力和编码器-解码器注意力的工作原理及其在序列生成任务中的应用。
掩码自注意力确保解码器在生成位置t时只能访问位置0到t的信息,防止未来信息泄露。
数学表示:
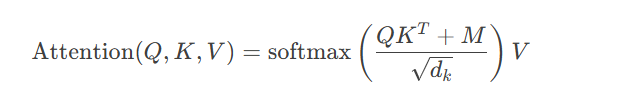
其中$M$为掩码矩阵:
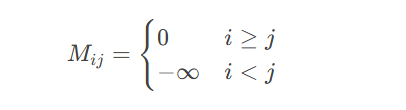
import torch
import numpy as np
import matplotlib.pyplot as plt
def generate_mask(seq_len):
"""生成下三角掩码矩阵"""
mask = torch.tril(torch.ones(seq_len, seq_len))
mask = mask.masked_fill(mask == 0, float('-inf'))
return mask.masked_fill(mask == 1, float(0.0))
# 可视化掩码矩阵
seq_len = 8
mask = generate_mask(seq_len)
plt.figure(figsize=(8, 8))
plt.imshow(mask.numpy(), cmap='viridis')
plt.title('掩码自注意力矩阵')
plt.xlabel('Key位置')
plt.ylabel('Query位置')
plt.xticks(range(seq_len))
plt.yticks(range(seq_len))
# 添加矩阵值
for i in range(seq_len):
for j in range(seq_len):
plt.text(j, i, f"{mask[i,j].item():.0f}",
ha="center", va="center", color="w", fontsize=12)
plt.colorbar()
plt.show()
class MaskedSelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super().__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert self.head_dim * heads == embed_size, "嵌入维度必须是头数的整数倍"
self.values = nn.Linear(embed_size, embed_size)
self.keys = nn.Linear(embed_size, embed_size)
self.queries = nn.Linear(embed_size, embed_size)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, x, mask):
# x: (batch_size, seq_len, embed_size)
batch_size, seq_length, _ = x.size()
# 线性变换
V = self.values(x) # (batch_size, seq_len, embed_size)
K = self.keys(x) # (batch_size, seq_len, embed_size)
Q = self.queries(x) # (batch_size, seq_len, embed_size)
# 分割多头
V = V.view(batch_size, seq_length, self.heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(batch_size, seq_length, self.heads, self.head_dim).permute(0, 2, 1, 3)
Q = Q.view(batch_size, seq_length, self.heads, self.head_dim).permute(0, 2, 1, 3)
# 计算注意力能量 (QK^T)
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / np.sqrt(self.head_dim)
# 应用掩码
if mask is not None:
energy = energy.masked_fill(mask == 0, float('-1e20'))
# 计算注意力权重
attention = F.softmax(energy, dim=-1)
# 加权求和
out = torch.matmul(attention, V)
out = out.permute(0, 2, 1, 3).contiguous()
out = out.view(batch_size, seq_length, self.embed_size)
out = self.fc_out(out)
return out, attention
# 测试掩码自注意力
embed_size = 128
heads = 8
seq_len = 6
batch_size = 2
# 创建输入和掩码
x = torch.randn(batch_size, seq_len, embed_size)
mask = generate_mask(seq_len).unsqueeze(0).unsqueeze(0) # 增加批次和头维度
# 初始化模型
masked_attn = MaskedSelfAttention(embed_size, heads)
output, attn_weights = masked_attn(x, mask)
print("输入形状:", x.shape)
print("输出形状:", output.shape)
print("注意力权重形状:", attn_weights.shape)
# 可视化注意力权重 (第一个批次,第一个头)
plt.figure(figsize=(8, 8))
plt.imshow(attn_weights[0, 0].detach().numpy(), cmap='viridis')
plt.title('掩码自注意力权重 (头1)')
plt.xlabel('Key位置')
plt.ylabel('Query位置')
plt.xticks(range(seq_len))
plt.yticks(range(seq_len))
plt.colorbar()
plt.show()掩码自注意力的关键特性:
因果性保证:确保当前位置只能关注之前位置
自回归支持:实现序列的逐步生成
并行计算:训练时所有位置同时计算(带掩码)
信息流控制:防止未来信息泄露
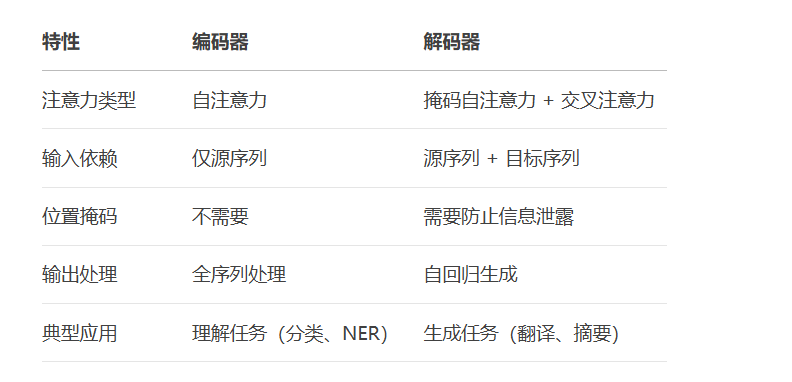
编码器-解码器注意力连接源序列和目标序列,使解码器可以动态关注源序列的相关部分。
数学表示:
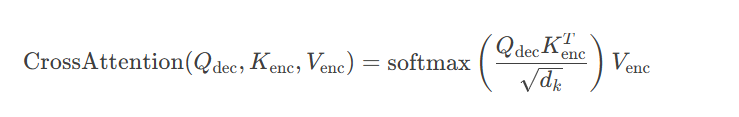
class EncoderDecoderAttention(nn.Module):
def __init__(self, embed_size, heads):
super().__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
self.values = nn.Linear(embed_size, embed_size)
self.keys = nn.Linear(embed_size, embed_size)
self.queries = nn.Linear(embed_size, embed_size)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, x, encoder_output, src_mask=None):
# x: 解码器输入 (batch_size, tgt_seq_len, embed_size)
# encoder_output: 编码器输出 (batch_size, src_seq_len, embed_size)
batch_size, tgt_len, _ = x.size()
src_len = encoder_output.size(1)
# 线性变换
V = self.values(encoder_output)
K = self.keys(encoder_output)
Q = self.queries(x)
# 分割多头
V = V.view(batch_size, src_len, self.heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(batch_size, src_len, self.heads, self.head_dim).permute(0, 2, 1, 3)
Q = Q.view(batch_size, tgt_len, self.heads, self.head_dim).permute(0, 2, 1, 3)
# 计算能量
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / np.sqrt(self.head_dim)
# 应用源序列掩码(如填充掩码)
if src_mask is not None:
energy = energy.masked_fill(src_mask.unsqueeze(1).unsqueeze(2) == 0, float('-1e20'))
# 计算注意力权重
attention = F.softmax(energy, dim=-1)
# 加权求和
out = torch.matmul(attention, V)
out = out.permute(0, 2, 1, 3).contiguous()
out = out.view(batch_size, tgt_len, self.embed_size)
out = self.fc_out(out)
return out, attention
# 测试交叉注意力
src_seq_len = 10
tgt_seq_len = 6
# 创建模拟数据
encoder_output = torch.randn(batch_size, src_seq_len, embed_size)
decoder_input = torch.randn(batch_size, tgt_seq_len, embed_size)
# 源序列掩码(模拟填充位置)
src_mask = torch.ones(batch_size, src_seq_len)
src_mask[:, 8:] = 0 # 最后两个位置为填充
# 初始化模型
cross_attn = EncoderDecoderAttention(embed_size, heads)
output, attn_weights = cross_attn(decoder_input, encoder_output, src_mask=src_mask)
print("编码器输出形状:", encoder_output.shape)
print("解码器输入形状:", decoder_input.shape)
print("交叉注意力输出形状:", output.shape)
# 可视化注意力权重 (第一个批次,第一个头)
plt.figure(figsize=(10, 8))
plt.imshow(attn_weights[0, 0].detach().numpy(), cmap='viridis')
plt.title('编码器-解码器注意力权重 (头1)')
plt.xlabel('源序列位置')
plt.ylabel('目标序列位置')
plt.xticks(range(src_seq_len))
plt.yticks(range(tgt_seq_len))
plt.colorbar()
plt.show()交叉注意力的核心作用:
对齐机制:自动学习源序列与目标序列的对应关系
信息融合:将源序列信息注入解码过程
上下文提取:动态聚焦相关源信息
解耦依赖:分离源序列和目标序列的处理
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, heads, ff_dim, dropout=0.1):
super().__init__()
# 掩码自注意力
self.masked_self_attn = MaskedSelfAttention(d_model, heads)
self.norm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
# 编码器-解码器注意力
self.enc_dec_attn = EncoderDecoderAttention(d_model, heads)
self.norm2 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(dropout)
# 前馈网络
self.ffn = nn.Sequential(
nn.Linear(d_model, ff_dim),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(ff_dim, d_model)
)
self.norm3 = nn.LayerNorm(d_model)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask, tgt_mask):
# 掩码自注意力 + 残差连接
attn1, self_attn_weights = self.masked_self_attn(x, tgt_mask)
x = x + self.dropout1(attn1)
x = self.norm1(x)
# 编码器-解码器注意力 + 残差连接
attn2, cross_attn_weights = self.enc_dec_attn(x, encoder_output, src_mask)
x = x + self.dropout2(attn2)
x = self.norm2(x)
# 前馈网络 + 残差连接
ffn_out = self.ffn(x)
x = x + self.dropout3(ffn_out)
x = self.norm3(x)
return x, self_attn_weights, cross_attn_weights
# 测试解码器层
d_model = 128
heads = 8
ff_dim = 512
# 创建输入和掩码
decoder_input = torch.randn(batch_size, tgt_seq_len, d_model)
encoder_output = torch.randn(batch_size, src_seq_len, d_model)
src_mask = torch.ones(batch_size, src_seq_len) # 假设无填充
tgt_mask = generate_mask(tgt_seq_len).unsqueeze(0).unsqueeze(0) # 增加批次和头维度
# 初始化解码器层
decoder_layer = TransformerDecoderLayer(d_model, heads, ff_dim)
output, self_attn, cross_attn = decoder_layer(
decoder_input,
encoder_output,
src_mask,
tgt_mask
)
print("解码器输入形状:", decoder_input.shape)
print("解码器输出形状:", output.shape)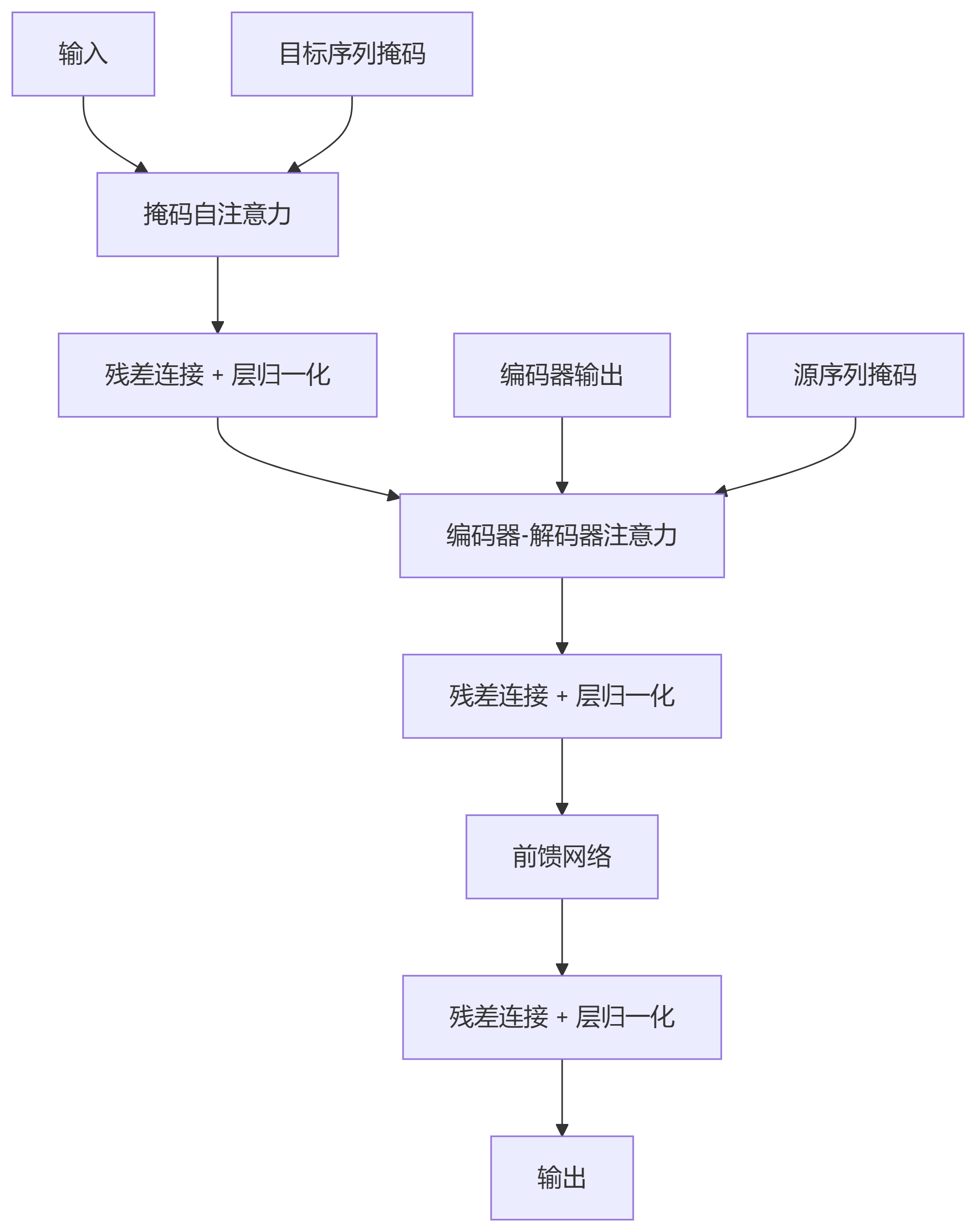

class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers):
super().__init__()
self.layers = nn.ModuleList([decoder_layer for _ in range(num_layers)])
self.num_layers = num_layers
def forward(self, x, encoder_output, src_mask, tgt_mask):
all_self_attn = []
all_cross_attn = []
for layer in self.layers:
x, self_attn, cross_attn = layer(
x,
encoder_output,
src_mask,
tgt_mask
)
all_self_attn.append(self_attn)
all_cross_attn.append(cross_attn)
return x, all_self_attn, all_cross_attn
# 构建完整解码器
num_layers = 6
decoder = TransformerDecoder(decoder_layer, num_layers)
# 测试解码器
output, all_self_attn, all_cross_attn = decoder(
decoder_input,
encoder_output,
src_mask,
tgt_mask
)
print("解码器输出形状:", output.shape)
print("自注意力权重列表长度:", len(all_self_attn))
print("交叉注意力权重列表长度:", len(all_cross_attn))class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, ff_dim):
super().__init__()
# 编码器部分
self.encoder_embed = nn.Embedding(src_vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model)
encoder_layer = nn.TransformerEncoderLayer(d_model, nhead, ff_dim)
self.encoder = nn.TransformerEncoder(encoder_layer, num_encoder_layers)
# 解码器部分
self.decoder_embed = nn.Embedding(tgt_vocab_size, d_model)
self.pos_decoder = PositionalEncoding(d_model)
decoder_layer = nn.TransformerDecoderLayer(d_model, nhead, ff_dim)
self.decoder = nn.TransformerDecoder(decoder_layer, num_decoder_layers)
# 输出层
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
# 编码器
src_emb = self.pos_encoder(self.encoder_embed(src))
memory = self.encoder(src_emb, src_key_padding_mask=src_mask)
# 解码器
tgt_emb = self.pos_decoder(self.decoder_embed(tgt))
output = self.decoder(
tgt_emb,
memory,
tgt_mask=tgt_mask,
memory_key_padding_mask=src_mask
)
# 输出预测
return self.fc_out(output)
# 参数设置
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6
ff_dim = 2048
# 初始化模型
model = Transformer(
src_vocab_size,
tgt_vocab_size,
d_model,
nhead,
num_encoder_layers,
num_decoder_layers,
ff_dim
)
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")# 模拟数据生成
src_data = torch.randint(1, src_vocab_size, (32, 20)) # 批量32, 源序列长20
tgt_data = torch.randint(1, tgt_vocab_size, (32, 15)) # 批量32, 目标序列长15
# 创建掩码
src_mask = (src_data != 0).float() # 假设0为填充
tgt_mask = generate_mask(tgt_data.size(1))
# 前向传播
output = model(src_data, tgt_data[:, :-1], src_mask=src_mask, tgt_mask=tgt_mask)
print("模型输出形状:", output.shape) # (batch_size, tgt_seq_len-1, tgt_vocab_size)criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略填充位置
optimizer = torch.optim.Adam(model.parameters(), lr=0.0005)
def train_step(src, tgt):
optimizer.zero_grad()
# 创建目标输入和标签
tgt_input = tgt[:, :-1]
tgt_labels = tgt[:, 1:]
# 创建掩码
src_mask = (src != 0).float()
tgt_mask = generate_mask(tgt_input.size(1))
# 前向传播
output = model(src, tgt_input, src_mask=src_mask, tgt_mask=tgt_mask)
# 计算损失
loss = criterion(output.reshape(-1, output.size(-1)), tgt_labels.reshape(-1))
# 反向传播
loss.backward()
optimizer.step()
return loss.item()
# 模拟训练
for step in range(1000):
src = torch.randint(1, src_vocab_size, (32, 20))
tgt = torch.randint(1, tgt_vocab_size, (32, 15))
loss = train_step(src, tgt)
if (step+1) % 100 == 0:
print(f"Step {step+1}, Loss: {loss:.4f}")def greedy_decode(model, src, max_len=20, start_symbol=1):
src_mask = (src != 0).float()
src_emb = model.pos_encoder(model.encoder_embed(src))
memory = model.encoder(src_emb, src_key_padding_mask=src_mask)
# 初始化目标序列
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src)
for i in range(max_len-1):
# 创建目标掩码
tgt_mask = generate_mask(ys.size(1))
# 解码
tgt_emb = model.pos_decoder(model.decoder_embed(ys))
out = model.decoder(tgt_emb, memory, tgt_mask=tgt_mask)
# 预测下一个词
prob = model.fc_out(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.item()
# 添加到序列
ys = torch.cat([ys, torch.ones(1, 1).type_as(src).fill_(next_word)], dim=1)
# 遇到结束符停止
if next_word == 2: # 假设2是结束符
break
return ys
# 测试推理
src_sentence = torch.randint(1, src_vocab_size, (1, 10)) # 单个源序列
translated = greedy_decode(model, src_sentence)
print("源序列:", src_sentence)
print("翻译结果:", translated)掩码自注意力核心:
# 创建因果掩码
mask = torch.tril(torch.ones(seq_len, seq_len))
mask = mask.masked_fill(mask == 0, float('-inf'))
# 应用掩码
energy = QK^T / sqrt(d_k) + mask编码器-解码器注意力流程:

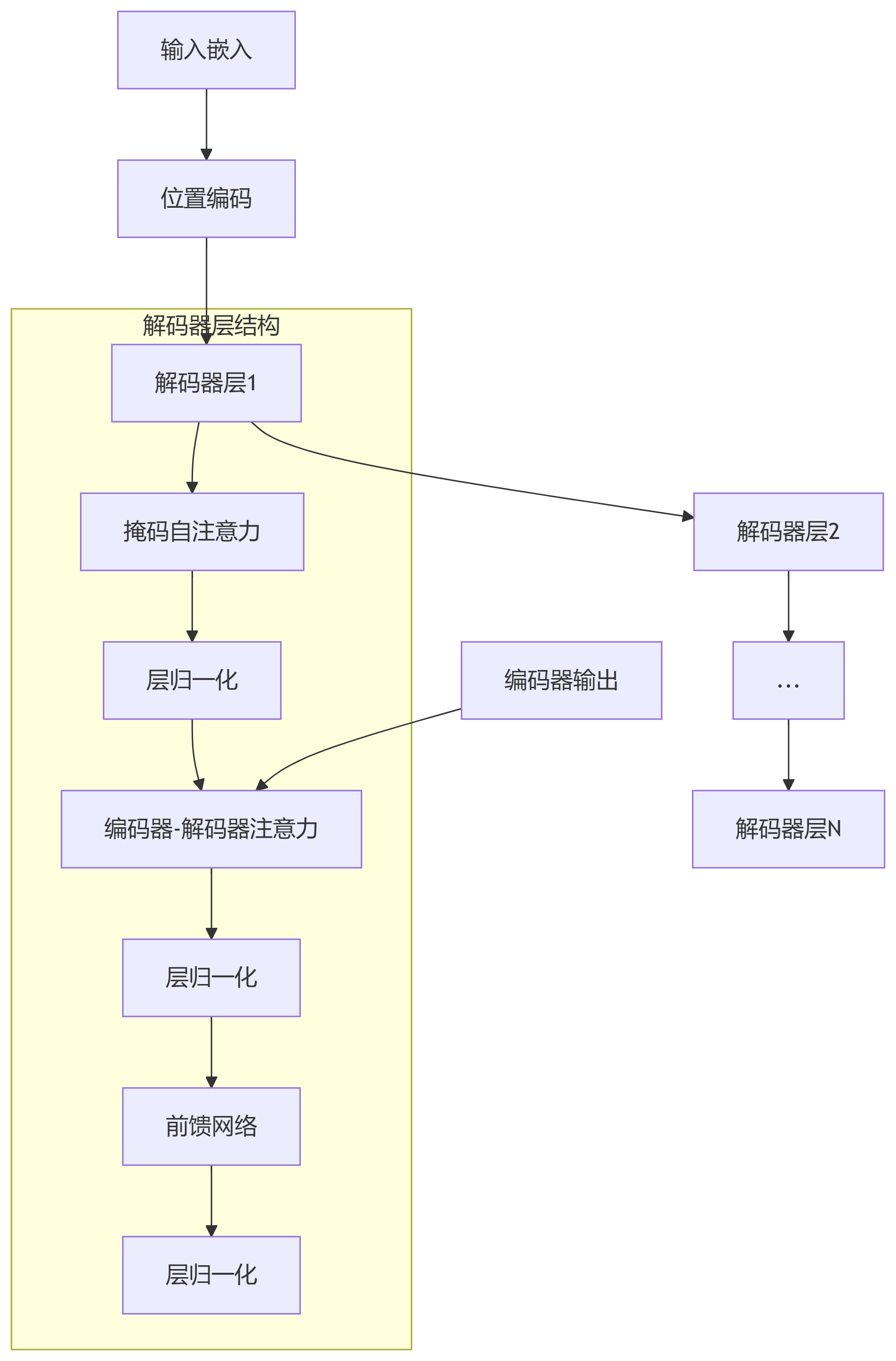
解码器层结构:
输入 │ ├─> 掩码自注意力 → 残差连接 → 层归一化 │ ├─> 编码器-解码器注意力 → 残差连接 → 层归一化 │ └─> 前馈网络 → 残差连接 → 层归一化 │ 输出
训练与推理差异:

超参数设置建议:
d_model:512-1024(平衡性能与计算)
nhead:8-16(确保d_model可整除)
层数:编码器/解码器各6层(基础模型)
ff_dim:通常为4×d_model
Dropout:0.1(防止过拟合)
通过掌握Transformer解码器的核心机制,你已经具备了构建现代序列生成模型的基础能力。更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



