本文深入剖析Transformer编码器的核心组件,通过数学原理、可视化图解和完整代码实现,全面讲解位置编码、层归一化、前馈网络和残差连接的设计思想与实现细节。
Transformer使用正弦余弦函数生成位置编码:
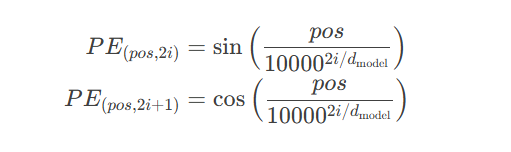
其中:
$pos$:序列中的位置(0-indexed)
$i$:维度索引($0 \leq i < d_{\text{model}}/2$)
$d_{\text{model}}$:模型维度(通常512)
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
self.dropout = nn.Dropout(p=0.1)
# 创建位置编码矩阵
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-np.log(10000.0) / d_model)
pe = torch.zeros(max_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term) # 偶数索引使用sin
pe[:, 1::2] = torch.cos(position * div_term) # 奇数索引使用cos
self.register_buffer('pe', pe) # 注册为缓冲区,不参与训练
def forward(self, x):
# x: (batch_size, seq_len, d_model)
x = x + self.pe[:x.size(1), :] # 添加位置编码
return self.dropout(x)
# 可视化位置编码
d_model = 128
max_len = 100
pe = PositionalEncoding(d_model, max_len)
pos_enc = pe.pe.numpy() # 获取位置编码矩阵
plt.figure(figsize=(10, 8))
plt.imshow(pos_enc[:50, :], cmap='viridis', aspect='auto')
plt.title('位置编码可视化 (前50个位置)')
plt.xlabel('模型维度')
plt.ylabel('序列位置')
plt.colorbar()
plt.show()
# 3D可视化
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
x = np.arange(d_model)
y = np.arange(max_len)
X, Y = np.meshgrid(x, y)
Z = pos_enc[Y, X]
surf = ax.plot_surface(X, Y, Z, cmap=cm.viridis, rstride=1, cstride=1)
ax.set_xlabel('模型维度')
ax.set_ylabel('序列位置')
ax.set_zlabel('编码值')
ax.set_title('位置编码3D可视化')
fig.colorbar(surf)
plt.show()位置编码关键特性:
相对位置感知:位置$pos+k$的编码可以表示为$pos$的线性函数
唯一性:每个位置有唯一编码表示
有界性:值在[-1,1]范围内
模型维度无关:适用于任意$d_{\text{model}}$
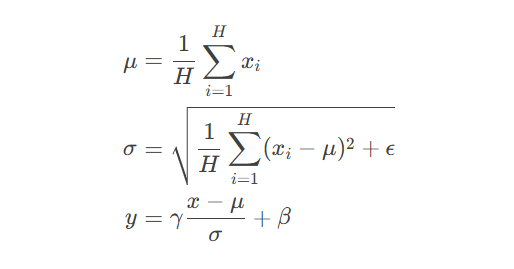
其中$H$是特征维度大小
# 输入数据:模拟4个样本,每个样本5个特征
data = torch.tensor([
[1.0, 2.0, 3.0, 4.0, 5.0],
[2.0, 3.0, 4.0, 5.0, 6.0],
[-1.0, 0.0, 1.0, 2.0, 3.0],
[0.5, 1.5, 2.5, 3.5, 4.5]
])
# 批归一化
batch_norm = nn.BatchNorm1d(5)
bn_output = batch_norm(data)
# 层归一化
layer_norm = nn.LayerNorm(5)
ln_output = layer_norm(data)
# 可视化对比
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
# 原始数据
im0 = axes[0].imshow(data.numpy(), cmap='viridis')
axes[0].set_title('原始数据')
axes[0].set_xlabel('特征维度')
axes[0].set_ylabel('样本索引')
fig.colorbar(im0, ax=axes[0])
# 批归一化结果
im1 = axes[1].imshow(bn_output.detach().numpy(), cmap='viridis')
axes[1].set_title('批归一化结果')
axes[1].set_xlabel('特征维度')
fig.colorbar(im1, ax=axes[1])
# 层归一化结果
im2 = axes[2].imshow(ln_output.detach().numpy(), cmap='viridis')
axes[2].set_title('层归一化结果')
axes[2].set_xlabel('特征维度')
fig.colorbar(im2, ax=axes[2])
plt.tight_layout()
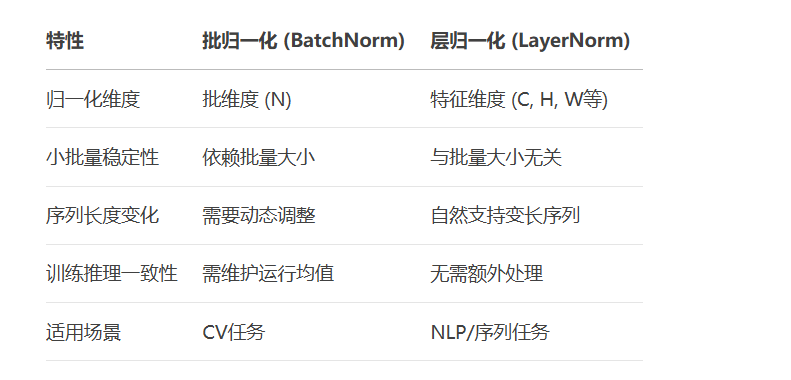
plt.show()层归一化优势:
class PositionwiseFeedForward(nn.Module):
"""Transformer中的前馈网络"""
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = nn.GELU() # 比ReLU更平滑的激活函数
def forward(self, x):
return self.linear2(self.dropout(self.activation(self.linear1(x))))
# 测试前馈网络
d_model = 512
d_ff = 2048 # 通常为d_model的4倍
ffn = PositionwiseFeedForward(d_model, d_ff)
input_data = torch.randn(2, 10, d_model) # 批量2, 序列10, 维度512
output = ffn(input_data)
print("输入形状:", input_data.shape)
print("输出形状:", output.shape)前馈网络数学表示:
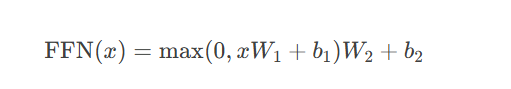
现代实现通常使用GELU激活函数:
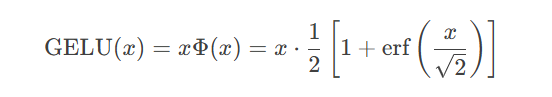
# 创建模拟数据
x = torch.linspace(-5, 5, 100)
linear = nn.Linear(1, 1)(x.unsqueeze(1)).squeeze()
relu = nn.ReLU()(linear)
gelu = nn.GELU()(linear)
# 可视化
plt.figure(figsize=(10, 6))
plt.plot(x.numpy(), linear.detach().numpy(), label='线性变换', linestyle='--')
plt.plot(x.numpy(), relu.detach().numpy(), label='ReLU激活')
plt.plot(x.numpy(), gelu.detach().numpy(), label='GELU激活')
plt.title('前馈网络激活函数对比')
plt.xlabel('输入值')
plt.ylabel('输出值')
plt.legend()
plt.grid(True)
plt.show()前馈网络核心作用:
非线性变换:引入非线性表达能力
维度扩展:先升维(d_model→d_ff)后降维(d_ff→d_model)
特征重组:在相同位置独立处理每个特征
上下文独立:不依赖其他位置信息
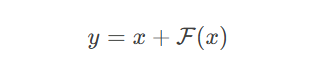
其中$\mathcal{F}$表示子层(自注意力或前馈网络)
# 创建简单网络
class BlockWithoutRes(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(2, 2)
self.relu = nn.ReLU()
def forward(self, x):
return self.relu(self.linear(x))
class BlockWithRes(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(2, 2)
self.relu = nn.ReLU()
def forward(self, x):
return x + self.relu(self.linear(x))
# 测试梯度流动
def compute_grad(model, input):
output = model(input)
output.norm().backward()
return input.grad.norm().item()
# 创建输入
x = torch.tensor([[1.0, 2.0]], requires_grad=True)
# 无残差连接
model_no_res = BlockWithoutRes()
grad_no_res = compute_grad(model_no_res, x)
# 有残差连接
x.grad = None # 重置梯度
model_res = BlockWithRes()
grad_res = compute_grad(model_res, x)
print(f"无残差连接梯度范数: {grad_no_res:.4f}")
print(f"有残差连接梯度范数: {grad_res:.4f}")
# 可视化梯度流动
plt.figure(figsize=(10, 6))
plt.bar(['无残差连接', '有残差连接'], [grad_no_res, grad_res], color=['red', 'green'])
plt.title('残差连接对梯度的影响')
plt.ylabel('输入梯度范数')
plt.grid(axis='y')
plt.show()残差连接核心优势:
缓解梯度消失:提供恒等映射路径
加速训练收敛:允许更深网络结构
模型容错性:即使子层失效仍能传递信息
特征复用:保留原始输入特征
5.1 编码器层组件集成
class TransformerEncoderLayer(nn.Module):
"""Transformer编码器层"""
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super().__init__()
# 自注意力层
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# 前馈网络
self.ffn = PositionwiseFeedForward(d_model, dim_feedforward, dropout)
# 归一化层
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# Dropout
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, src, src_mask=None, src_key_padding_mask=None):
# 残差连接1: 自注意力
src2, attn_weights = self.self_attn(
src, src, src,
attn_mask=src_mask,
key_padding_mask=src_key_padding_mask
)
src = src + self.dropout1(src2)
src = self.norm1(src)
# 残差连接2: 前馈网络
src2 = self.ffn(src)
src = src + self.dropout2(src2)
src = self.norm2(src)
return src, attn_weights
# 测试编码器层
d_model = 512
nhead = 8
encoder_layer = TransformerEncoderLayer(d_model, nhead)
src = torch.randn(10, 32, d_model) # (seq_len, batch_size, d_model)
output, attn_weights = encoder_layer(src)
print("输入形状:", src.shape)
print("输出形状:", output.shape)
print("注意力权重形状:", attn_weights.shape)class TransformerEncoder(nn.Module):
"""Transformer编码器"""
def __init__(self, encoder_layer, num_layers):
super().__init__()
# 堆叠多个编码器层
self.layers = nn.ModuleList([encoder_layer for _ in range(num_layers)])
def forward(self, src, mask=None, src_key_padding_mask=None):
output = src
all_attn_weights = []
for layer in self.layers:
output, attn_weights = layer(
output,
src_mask=mask,
src_key_padding_mask=src_key_padding_mask
)
all_attn_weights.append(attn_weights)
return output, all_attn_weights
# 构建完整编码器
num_layers = 6
encoder = TransformerEncoder(encoder_layer, num_layers)
encoder_output, all_attn = encoder(src)
print("编码器输出形状:", encoder_output.shape)
print("注意力权重列表长度:", len(all_attn))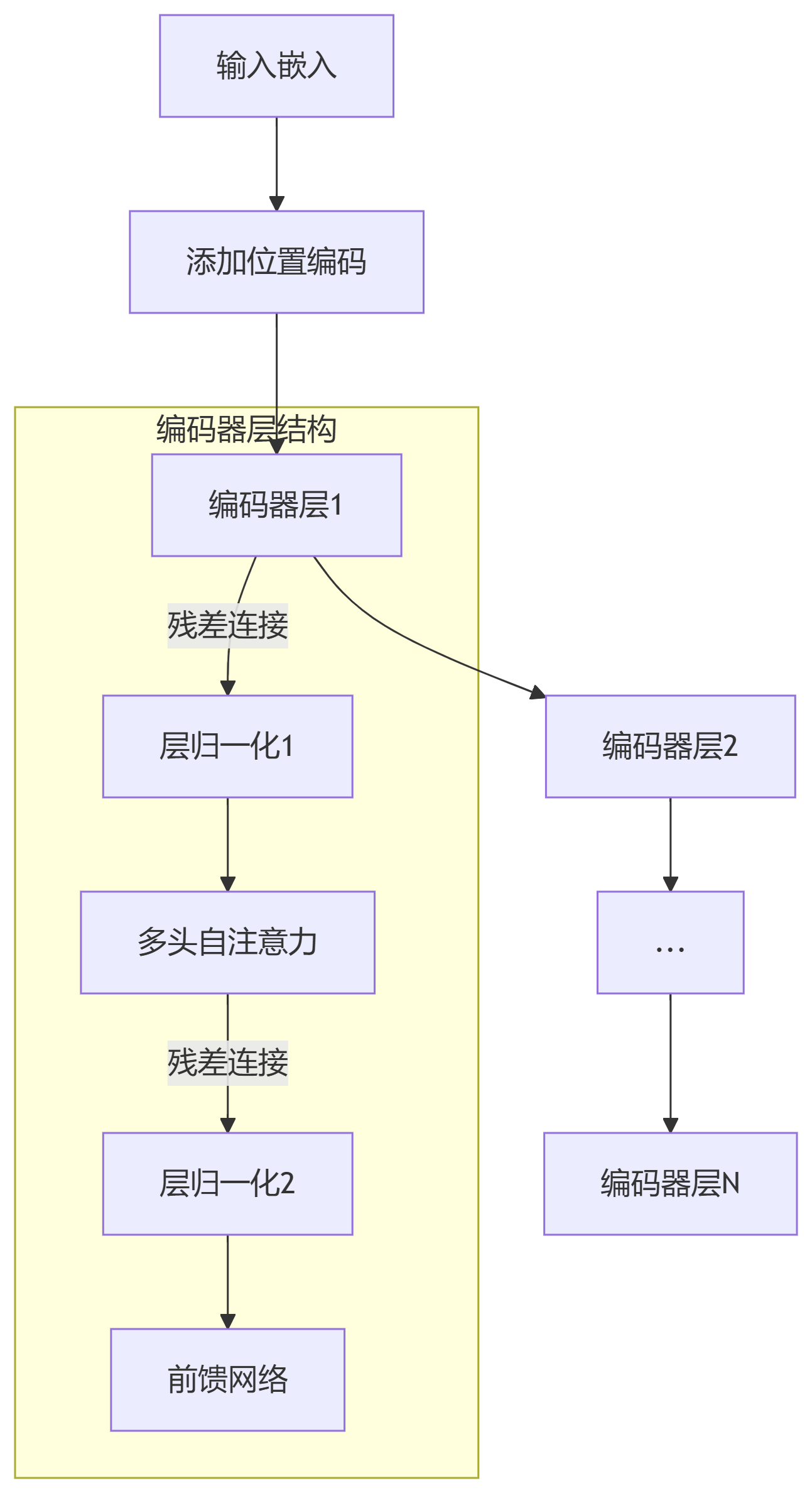
from torchtext.datasets import IMDB
from torchtext.data import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
# 加载IMDB数据集
train_iter = IMDB(split='train')
tokenizer = get_tokenizer('basic_english')
# 构建词汇表
def yield_tokens(data_iter):
for _, text in data_iter:
yield tokenizer(text)
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=['<unk>', '<pad>'])
vocab.set_default_index(vocab['<unk>'])
# 文本转张量
def text_pipeline(text, max_len=512):
tokens = vocab(tokenizer(text))[:max_len]
tokens += [vocab['<pad>']] * (max_len - len(tokens))
return tokens
# 创建批次处理
def collate_batch(batch):
labels, texts = [], []
for label, text in batch:
labels.append(1 if label == 'pos' else 0)
texts.append(text_pipeline(text))
return torch.tensor(labels), torch.tensor(texts)
# 数据加载器
from torch.utils.data import DataLoader
train_loader = DataLoader(
list(IMDB(split='train')),
batch_size=32,
collate_fn=collate_batch
)class TransformerClassifier(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_layers, num_classes):
super().__init__()
# 嵌入层
self.embedding = nn.Embedding(vocab_size, d_model)
# 位置编码
self.pos_encoder = PositionalEncoding(d_model)
# Transformer编码器
encoder_layer = TransformerEncoderLayer(d_model, nhead)
self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers)
# 分类器
self.classifier = nn.Sequential(
nn.Linear(d_model, d_model//2),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(d_model//2, num_classes)
)
def forward(self, src):
# 嵌入层
src = self.embedding(src) * np.sqrt(self.embedding.embedding_dim)
# 位置编码
src = self.pos_encoder(src)
# Transformer编码器
encoder_output, _ = self.transformer_encoder(src)
# 取序列第一个位置 ([CLS]标记)
cls_output = encoder_output[:, 0, :]
# 分类
return self.classifier(cls_output)
# 初始化模型
vocab_size = len(vocab)
d_model = 256
nhead = 8
num_layers = 4
num_classes = 2
model = TransformerClassifier(vocab_size, d_model, nhead, num_layers, num_classes)
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
# 训练配置
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001, weight_decay=1e-5)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)def train_epoch(model, loader, optimizer, criterion):
model.train()
total_loss = 0
correct = 0
total = 0
for labels, texts in loader:
optimizer.zero_grad()
outputs = model(texts)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
accuracy = 100. * correct / total
avg_loss = total_loss / len(loader)
return avg_loss, accuracy
# 训练循环
num_epochs = 10
train_losses = []
train_accs = []
for epoch in range(num_epochs):
loss, acc = train_epoch(model, train_loader, optimizer, criterion)
scheduler.step()
train_losses.append(loss)
train_accs.append(acc)
print(f"Epoch {epoch+1}/{num_epochs} | "
f"Loss: {loss:.4f} | Acc: {acc:.2f}% | "
f"LR: {scheduler.get_last_lr()[0]:.6f}")
# 可视化训练过程
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, 'o-')
plt.title('训练损失')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(train_accs, 'o-')
plt.title('训练准确率')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.grid(True)
plt.tight_layout()
plt.show()
# 可视化注意力权重
def visualize_attention(text, layer_idx=0, head_idx=0):
tokens = tokenizer(text)[:512]
indexed = [vocab[token] for token in tokens]
input_tensor = torch.tensor([indexed])
model.eval()
with torch.no_grad():
# 获取嵌入和位置编码
emb = model.embedding(input_tensor) * np.sqrt(d_model)
src = model.pos_encoder(emb)
# 逐层传递并收集注意力
attn_weights = []
for layer in model.transformer_encoder.layers:
src, attn = layer.self_attn(src, src, src)
attn_weights.append(attn)
# 获取指定层的注意力权重
layer_attn = attn_weights[layer_idx][head_idx]
# 可视化
plt.figure(figsize=(12, 10))
plt.imshow(layer_attn.squeeze().numpy(), cmap='viridis')
plt.title(f'层 {layer_idx+1} - 头 {head_idx+1} 注意力权重')
plt.xlabel('Key位置')
plt.ylabel('Query位置')
plt.xticks(range(len(tokens)), tokens, rotation=90)
plt.yticks(range(len(tokens)), tokens)
plt.colorbar()
plt.tight_layout()
plt.show()
# 测试样例
sample_text = "The movie was absolutely fantastic with incredible performances"
visualize_attention(sample_text, layer_idx=2, head_idx=3)位置编码核心公式:
PE[pos, 2i] = sin(pos / 10000^(2i/d_model)) PE[pos, 2i+1] = cos(pos / 10000^(2i/d_model))
层归一化操作流程:
graph LR A[输入] --> B[计算均值] A --> C[计算方差] B --> D[标准化] C --> D D --> E[缩放和平移]
前馈网络结构:
输入 → 线性层 (d_model→d_ff) → GELU → Dropout → 线性层 (d_ff→d_model)
残差连接实现:
# 自注意力残差 x = x + dropout(self_attn(x)) x = layer_norm(x) # 前馈网络残差 x = x + dropout(ffn(x)) x = layer_norm(x)
编码器层超参数设置:
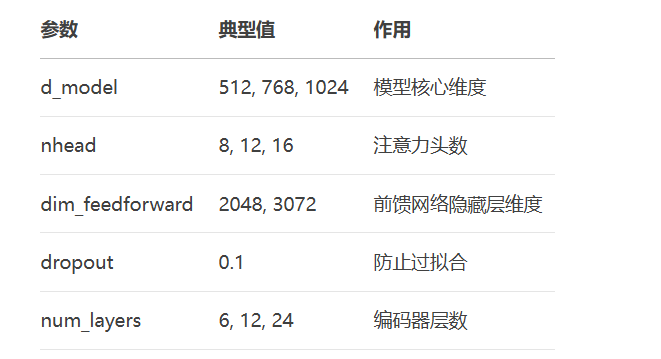
掌握Transformer编码器的核心组件和实现细节,你已经具备了构建现代NLP模型的基础能力。下一步可以探索预训练模型(如BERT、GPT)或扩展到多模态任务!更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



