本文系统讲解CNN核心原理、经典网络架构和图像分类实战,涵盖卷积层、池化层、LeNet/AlexNet/VGG/ResNet设计思想,并提供CIFAR-10/MNIST完整实现代码。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# 创建示例输入图像 (1通道, 5x5)
input_image = torch.tensor([
[1, 0, 0, 1, 0],
[0, 1, 1, 0, 1],
[1, 0, 1, 0, 1],
[0, 1, 0, 1, 0],
[1, 0, 1, 0, 1]
], dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 添加批次和通道维度
# 定义卷积核 (1个输出通道, 1个输入通道, 3x3)
conv_kernel = torch.tensor([
[1, 0, 1],
[0, 1, 0],
[1, 0, 1]
], dtype=torch.float32).unsqueeze(0).unsqueeze(0)
# 创建卷积层
conv_layer = nn.Conv2d(
in_channels=1,
out_channels=1,
kernel_size=3,
bias=False,
padding=0, # 无填充
stride=1 # 步长1
)
# 手动设置卷积核权重
conv_layer.weight.data = conv_kernel
# 执行卷积操作
output = conv_layer(input_image)
# 可视化结果
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.imshow(input_image[0, 0], cmap='gray')
plt.title('输入图像 (5x5)')
plt.subplot(1, 3, 2)
plt.imshow(conv_kernel[0, 0], cmap='gray')
plt.title('卷积核 (3x3)')
plt.subplot(1, 3, 3)
plt.imshow(output.detach()[0, 0], cmap='gray')
plt.title('卷积结果 (3x3)')
plt.tight_layout()
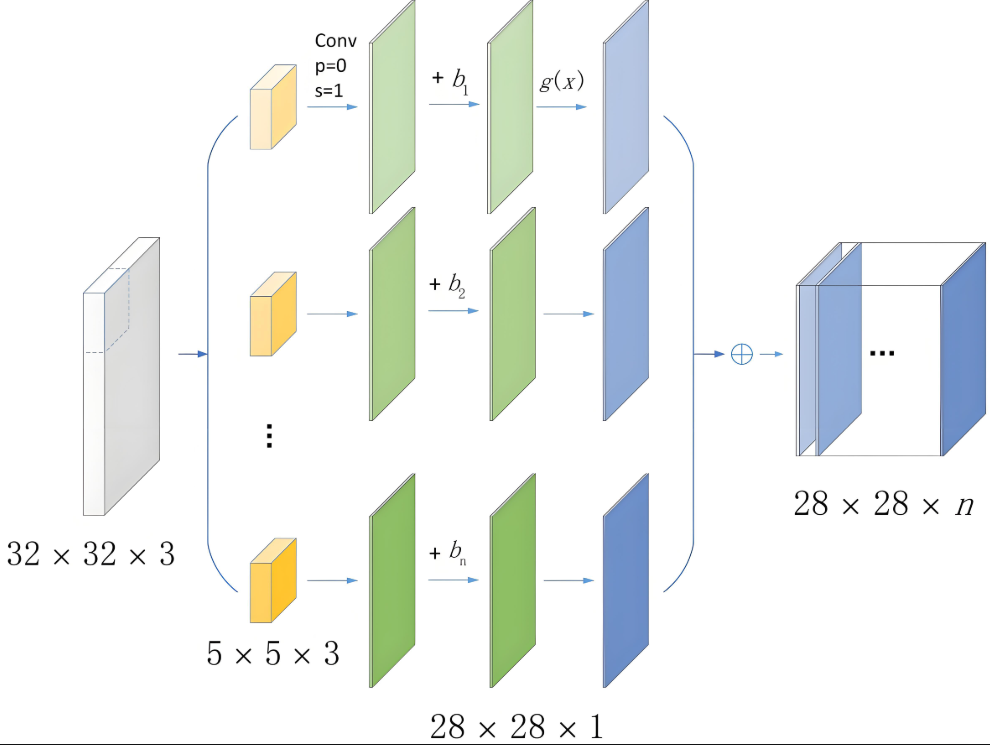
plt.show()卷积运算数学原理:
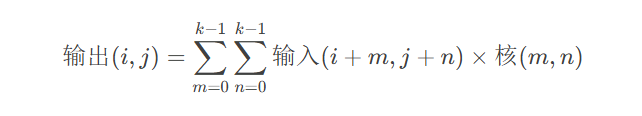
关键参数解析:
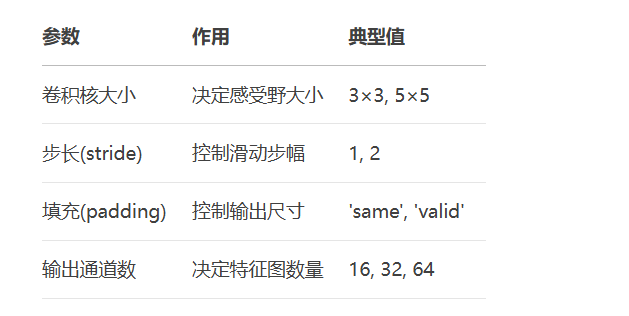
1.2 池化层:特征降维与不变性
# 创建最大池化层
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 创建平均池化层
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
# 输入数据 (模拟特征图)
feature_map = torch.tensor([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
], dtype=torch.float32).view(1, 1, 4, 4)
# 执行池化操作
max_output = max_pool(feature_map)
avg_output = avg_pool(feature_map)
# 可视化结果
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.imshow(feature_map[0, 0], cmap='viridis')
plt.title('输入特征图 (4x4)')
plt.subplot(1, 3, 2)
plt.imshow(max_output[0, 0], cmap='viridis')
plt.title('最大池化结果 (2x2)')
plt.subplot(1, 3, 3)
plt.imshow(avg_output[0, 0], cmap='viridis')
plt.title('平均池化结果 (2x2)')
plt.tight_layout()
plt.show()
print("最大池化结果:\n", max_output)
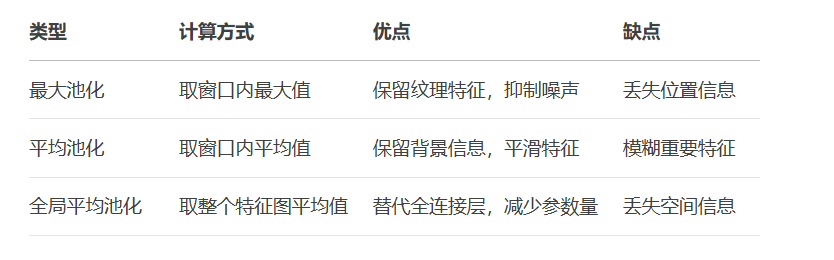
print("平均池化结果:\n", avg_output)池化层对比:
class LeNet(nn.Module): """LeNet-5 架构 (1998)""" def __init__(self, num_classes=10): super().__init__() self.features = nn.Sequential( nn.Conv2d(1, 6, kernel_size=5), # 28x28 -> 24x24 nn.Tanh(), nn.AvgPool2d(kernel_size=2, stride=2), # 24x24 -> 12x12 nn.Conv2d(6, 16, kernel_size=5), # 12x12 -> 8x8 nn.Tanh(), nn.AvgPool2d(kernel_size=2, stride=2) # 8x8 -> 4x4 ) self.classifier = nn.Sequential( nn.Linear(16*4*4, 120), nn.Tanh(), nn.Linear(120, 84), nn.Tanh(), nn.Linear(84, num_classes) ) def forward(self, x): x = self.features(x) x = torch.flatten(x, 1) x = self.classifier(x) return x # 可视化LeNet结构 model = LeNet() print(model)
LeNet-5设计思想:
首次提出卷积-池化交替结构
使用Tanh激活函数
平均池化代替最大池化
参数量仅6万,适合当时硬件
class AlexNet(nn.Module): """AlexNet 架构 (2012)""" def __init__(self, num_classes=1000): super().__init__() self.features = nn.Sequential( nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2), # 227x227 -> 55x55 nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), # 55x55 -> 27x27 nn.Conv2d(96, 256, kernel_size=5, padding=2), # 27x27 -> 27x27 nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), # 27x27 -> 13x13 nn.Conv2d(256, 384, kernel_size=3, padding=1), # 13x13 -> 13x13 nn.ReLU(inplace=True), nn.Conv2d(384, 384, kernel_size=3, padding=1), # 13x13 -> 13x13 nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1), # 13x13 -> 13x13 nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), # 13x13 -> 6x6 ) self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(256*6*6, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.features(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.classifier(x) return x
AlexNet创新点:
首次使用ReLU激活函数解决梯度消失
引入Dropout防止过拟合
使用重叠池化提升特征丰富性
GPU并行训练加速(当时需两块GTX 580)
数据增强技术(随机裁剪、水平翻转)
def make_vgg_layers(cfg, batch_norm=False): layers = [] in_channels = 3 for v in cfg: if v == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) if batch_norm: layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)] else: layers += [conv2d, nn.ReLU(inplace=True)] in_channels = v return nn.Sequential(*layers) # VGG-16配置 cfg_16 = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'] class VGG(nn.Module): def __init__(self, num_classes=1000, init_weights=True): super().__init__() self.features = make_vgg_layers(cfg_16) self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) self.classifier = nn.Sequential( nn.Linear(512*7*7, 4096), nn.ReLU(True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(True), nn.Dropout(), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.features(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.classifier(x) return x
VGG核心思想:
使用更小的3×3卷积核替代大卷积核(减少参数量)
深度增加到16-19层
所有卷积层保持相同填充和步长
每阶段特征图尺寸减半,通道数加倍
class BasicBlock(nn.Module): """ResNet基础残差块""" expansion = 1 def __init__(self, in_channels, out_channels, stride=1): super().__init__() self.conv1 = nn.Conv2d( in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(out_channels) self.relu = nn.ReLU(inplace=True) self.conv2 = nn.Conv2d( out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(out_channels) # 下采样捷径连接 self.downsample = nn.Sequential() if stride != 1 or in_channels != self.expansion*out_channels: self.downsample = nn.Sequential( nn.Conv2d(in_channels, self.expansion*out_channels, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(self.expansion*out_channels) ) def forward(self, x): identity = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) # 捷径连接 identity = self.downsample(identity) out += identity out = self.relu(out) return out class ResNet(nn.Module): """ResNet-18 实现""" def __init__(self, block=BasicBlock, layers=[2, 2, 2, 2], num_classes=1000): super().__init__() self.in_channels = 64 # 初始卷积层 self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 残差块层 self.layer1 = self._make_layer(block, 64, layers[0], stride=1) self.layer2 = self._make_layer(block, 128, layers[1], stride=2) self.layer3 = self._make_layer(block, 192, layers[2], stride=2) self.layer4 = self._make_layer(block, 256, layers[3], stride=2) # 分类器 self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.fc = nn.Linear(256*block.expansion, num_classes) def _make_layer(self, block, out_channels, blocks, stride=1): layers = [] layers.append(block(self.in_channels, out_channels, stride)) self.in_channels = out_channels * block.expansion for _ in range(1, blocks): layers.append(block(self.in_channels, out_channels)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.fc(x) return x
ResNet核心创新:
残差连接:$F(x) + x$ 解决梯度消失
恒等映射:当输入输出维度相同时直接相加
瓶颈设计:1×1卷积降维升维(ResNet50+)
批量归一化:加速训练,提高稳定性
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载MNIST数据集
train_data = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_data = datasets.MNIST('./data', train=False, transform=transform)
# 创建数据加载器
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=1000)
# 可视化样本
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(train_data[i][0][0], cmap='gray')
plt.title(f"Label: {train_data[i][1]}")
plt.axis('off')
plt.tight_layout()
plt.show()class CNN_MNIST(nn.Module):
"""MNIST专用CNN"""
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64*7*7, 128)
self.fc2 = nn.Linear(128, 10)
self.dropout = nn.Dropout(0.25)
def forward(self, x):
# 输入: [batch, 1, 28, 28]
x = self.pool(nn.functional.relu(self.conv1(x))) # -> [14,14]
x = self.pool(nn.functional.relu(self.conv2(x))) # -> [7,7]
x = torch.flatten(x, 1) # -> [batch, 64*7*7]
x = self.dropout(x)
x = nn.functional.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
# 初始化模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNN_MNIST().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练函数
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx*len(data)}/{len(train_loader.dataset)}'
f' ({100.*batch_idx/len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
# 测试函数
def test():
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\n测试集: 平均损失: {test_loss:.4f}, 准确率: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')
return accuracy
# 训练循环
accuracies = []
for epoch in range(1, 6): # 训练5个epoch
train(epoch)
acc = test()
accuracies.append(acc)
# 可视化训练结果
plt.plot(accuracies)
plt.title('MNIST分类准确率')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.grid(True)
plt.show()
# CIFAR-10数据增强
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))
])
# 加载CIFAR-10数据集
train_data = datasets.CIFAR10('./data', train=True, download=True, transform=train_transform)
test_data = datasets.CIFAR10('./data', train=False, transform=test_transform)
# 创建数据加载器
train_loader = DataLoader(train_data, batch_size=128, shuffle=True, num_workers=2)
test_loader = DataLoader(test_data, batch_size=256, shuffle=False, num_workers=2)
# 类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 可视化样本
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i+1)
img = train_data[i][0].permute(1, 2, 0) # CHW -> HWC
img = img * torch.tensor([0.2470, 0.2435, 0.2616]) + torch.tensor([0.4914, 0.4822, 0.4465])
plt.imshow(img.clamp(0, 1))
plt.title(classes[train_data[i][1]])
plt.axis('off')
plt.tight_layout()
plt.show()# 定义ResNet模型
def resnet18(num_classes=10):
return ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes)
# 初始化模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = resnet18(num_classes=10).to(device)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[100, 150], gamma=0.1)
# 训练循环
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx*len(data)}/{len(train_loader.dataset)}'
f' ({100.*batch_idx/len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
# 测试函数
def test():
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\n测试集: 平均损失: {test_loss:.4f}, 准确率: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')
return accuracy
# 训练循环
best_acc = 0
for epoch in range(1, 181): # 训练180个epoch
train(epoch)
acc = test()
scheduler.step()
# 保存最佳模型
if acc > best_acc:
best_acc = acc
torch.save(model.state_dict(), 'cifar10_resnet18.pth')
print(f"当前最佳准确率: {best_acc:.2f}%")
# 可视化分类结果
def visualize_predictions():
model.eval()
dataiter = iter(test_loader)
images, labels = next(dataiter)
images, labels = images[:10].to(device), labels[:10].to(device)
outputs = model(images)
_, preds = torch.max(outputs, 1)
# 反归一化图像
images = images.cpu()
mean = torch.tensor([0.4914, 0.4822, 0.4465])
std = torch.tensor([0.2470, 0.2435, 0.2616])
images = images * std.view(1, 3, 1, 1) + mean.view(1, 3, 1, 1)
plt.figure(figsize=(15, 5))
for i in range(10):
plt.subplot(2, 5, i+1)
img = images[i].permute(1, 2, 0).numpy()
plt.imshow(img.clip(0, 1))
plt.title(f"真实: {classes[labels[i]]}\n预测: {classes[preds[i]]}")
plt.axis('off')
plt.tight_layout()
plt.show()
visualize_predictions()
架构设计原则:
graph LR A[输入层] --> B[卷积层1] B --> C[激活函数] C --> D[池化层] D --> E[卷积层2] E --> F[激活函数] F --> G[池化层] G --> H[...] H --> I[全连接层] I --> J[输出层]
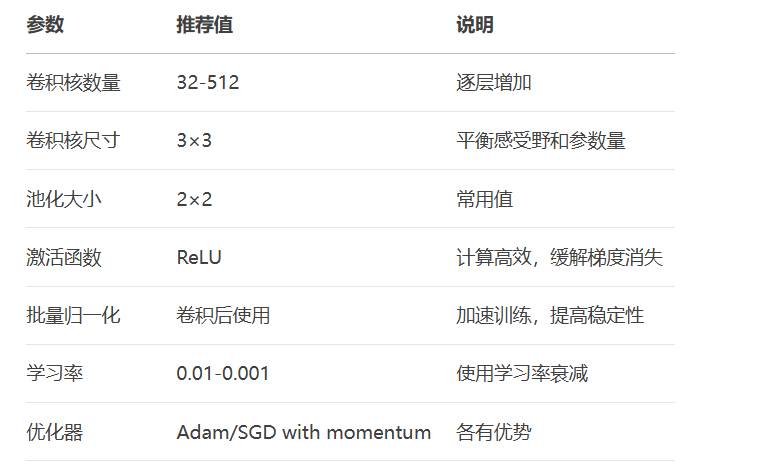
超参数选择指南:
性能优化技巧:
使用深度可分离卷积减少参数量
添加残差连接提升训练深度
使用注意力机制提升特征选择能力
实施混合精度训练加速计算
迁移学习策略:
# 加载预训练模型 pretrained_model = torchvision.models.resnet50(pretrained=True) # 冻结卷积层权重 for param in pretrained_model.parameters(): param.requires_grad = False # 替换分类器 pretrained_model.fc = nn.Linear(pretrained_model.fc.in_features, num_classes)
局部感受野提取特征
权重共享减少参数量
平移不变性处理位置变化
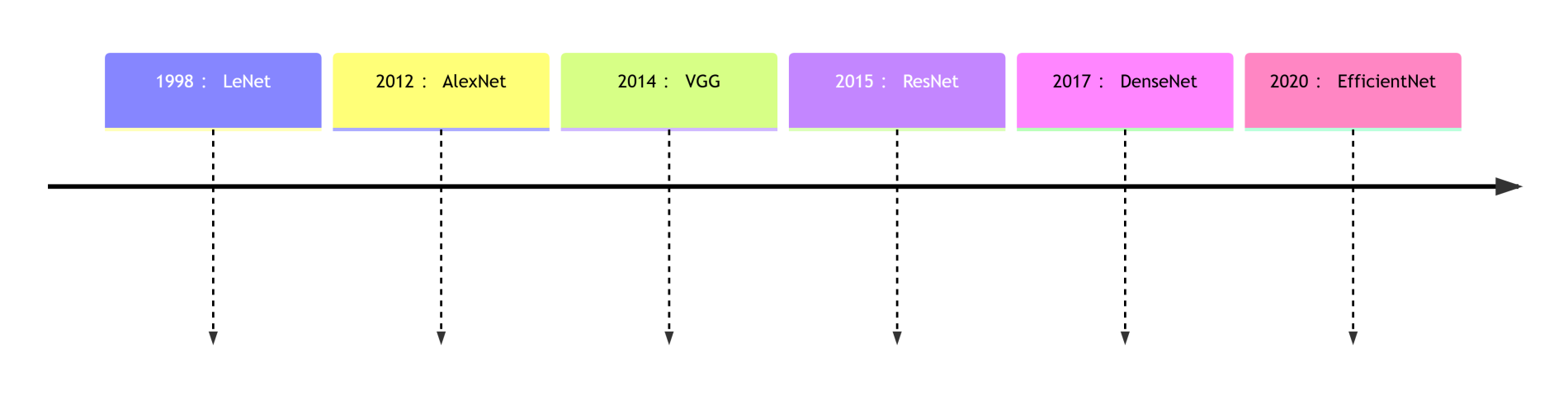
经典架构演进:
图像分类实战流程:
# 1. 数据加载与增强 transform = ... dataset = ... dataloader = ... # 2. 模型构建 model = ... # 3. 训练配置 criterion = ... optimizer = ... # 4. 训练循环 for epoch in range(epochs): for data in dataloader: # 前向传播 # 计算损失 # 反向传播 # 参数更新 # 5. 模型评估 test_accuracy = ...
CNN应用领域扩展:
目标检测(YOLO, Faster R-CNN)
语义分割(U-Net, DeepLab)
人脸识别(FaceNet)
医学影像分析
自动驾驶视觉系统
掌握这些CNN核心知识和实战技能后,你已具备开发复杂计算机视觉应用的基础能力。下一步可以探索目标检测、图像分割等高级任务,或深入研究Transformer在CV领域的应用!更多AI大模型应用开发学习视频和资料尽在聚客AI学院。



